最佳实践:Google文件系统为何不关心小文件,不关心一致性

文章目录
【注意】最后更新于 August 7, 2024,文中内容可能已过时,请谨慎使用。
知识地图: 项目架构–Google文件系统
一、 GFS有很多特点,为何我只看为大文件存储设计这一个特点。
一次只解决一个问题
分布式文件系统中最为著名的莫过于Google File System(GFS), 追求的是简单、够用的原则
正如GFS论文所述:“在设计中,我们更倾向于简单高效的机制,而非追求复杂的一致性协议。
它构建在廉价的普通PC服务器之上,支持自动容错。 GFS内部将大文件划分为大小约为64MB(目前128M)的数据块(chunk)
GFS设计目标支持弹性扩展 最大的已知集群规模超过1000个存储节点 最大集群的存储容量超过300TB
GFS的开发者在开发完GFS之后,很快就去开发BigTable了, 我估计是没有足够多时间。 在清晰地看到GFS的一致性模型给使用者带来的不便后,开源的HDFS(Hadoop分布式文件系统)坚定地摒弃了GFS的一致性模型,提供了更好的一致性保证。
GFS主要谷歌内部使用
- Bigtable、Google Megastore、Google Percolator均直接或者间接地构建在GFS之上。
- Google大规模批处理系统MapReduce也需要利用GFS作为海量数据的输入输出
足够内部使用,大家做项目不都是这样设计的吗?可以留言,评论一下
根据一次只解决一个问题 本文针对大文件读写做哪些优化措施? 其他特点 例如 容错 和性能, 一致性 不是本文重点, 不要贪多,能说明清楚一个问题,已经很了不起了。
二、 提出问题就成功一半,哪怕一个特点,也足够多问题
从小白角度去理解,放弃别人厉害你跟着说厉害,害怕说错了话,让人感觉无知,这都不懂,不需要。 别人有别人任务,他们不会你结果负责,他们更不愿意时间投入,你才这主角。第一步要做事情,搞清楚需要解决什么问题
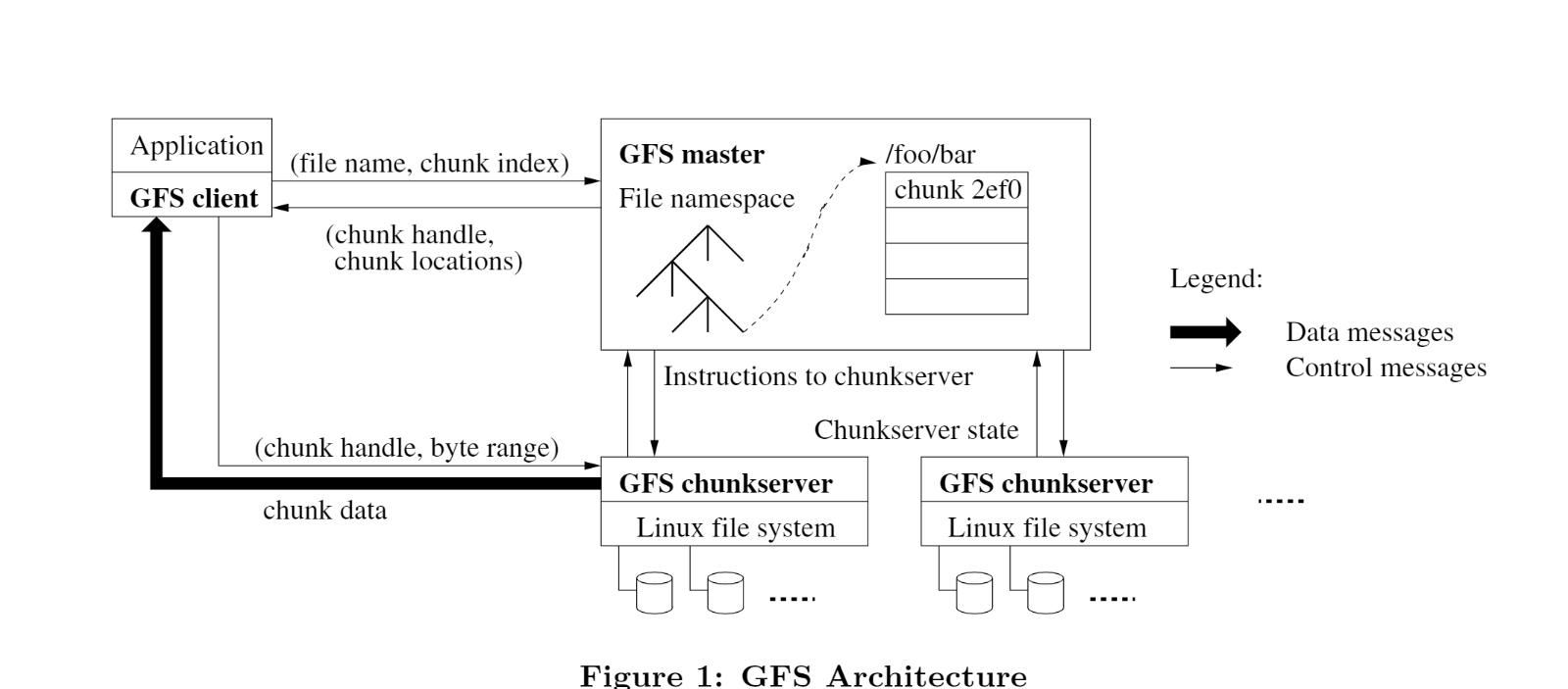
组成部分
GFS的主要架构组件有GFS client、GFS master和GFS chunkserver。 一个GFS集群包括一个master和多个chunkserver, 集群可以被多个GFS客户端访问。
三个组件的详细说明如下
2.1 组件 GFS客户端(GFS client)是运行在应用(application)进程里的代码,通常以SDK形式存在。
疑问1:为什么sdk方式提供,而不是标准文件方式提供?
- POSIX要求:强一致性,写入后所有读取必须看到最新数据。
- GFS设计:仅保证最终一致性。并发写入可能导致数据覆盖或未定义状态,需应用层处理冲突。
- POSIX强一致性需复杂同步机制(如分布式锁),违背GFS“单Master轻量化”原则。**专用接口将一致性责任转移至应用层(如BigTable),降低系统复杂度
- 用户态实现限制 GFS在用户态实现,若兼容POSIX需内核支持(如FUSE),引入性能损耗。专用API直接与Client/Master交互,减少上下文切换。
时间紧任务重,因此fuse不支持,复杂逻辑不支持。
疑问:GFS中的客户端不缓存文件数据?为什么
- GFS最主要的应用有两个:MapReduce与Bigtable。对于MapReduce,GFS客户端使用方式为顺序读写,没有缓存文件数据的必要
2.2 组件:元数据管理节点(GFS master),只有一个
疑问2 为什么元数据全部能存储到内存?是因为存储大文件文件少缘故吗?为什么只有一个节点,中心化设计不是不好吗?
- 反常识:普通文件系统,数据库 为了海量存储并不会全部元数据放入内存。
- GFS系统中每个chunk大小为64MB,默认存储3份,每个chunk的元数据小于64字节。那么1PB数据的chunk元信息大小不超过1PB×3/64MB×64=3GB 存
- 元数据都由master节点统一管理。所以一致性问题处理起来相对容易,简单呀
- 对比:完全无中心架构(GlusterFs)
疑问3:元数据如何存储文件目录,采用类似字符串方式数据结构?。
- 反常识:是普文件系统设计了目录项(directory entry),索引节点(index node),目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存
- Master节点负责维护三种关键类型的元数据,它们构成了GFS架构的核心:
-
文件和块的命名空间:
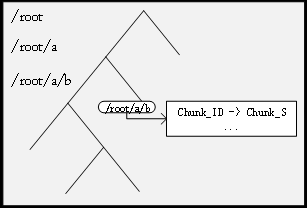
-
文件到块的映射
-
块副本的位置信息:这个不持久化
The master stores three major types of metadata: the fileand chunk namespaces, the mapping from files to chunks ,and the locations of each chunk’s replica
he master does not store chunk location informa-tion persistently. Instead, it asks each chunkserver about itschunks at master startup and whenever a chunkserver joinsthe cluster
举例:
以路径 /home/user/file.txt 为例:
- 路径分割:拆分为分段列表
["home", "user", "file.txt"]。 - 逐级查找(时间复杂度 O(m), m=路径深度):
- 从根目录
/的哈希表中查找"home"→ 返回目录节点指针; - 在
home目录的哈希表中查找"user"→ 返回目录节点指针; - 在
user目录的哈希表中查找"file.txt"→ 返回文件节点及关联的 Chunk/Block 列表
- 从根目录
2.3 数据存储节点 GFS chunkserver
疑问4 为什么不自己研发一套文件系统,建立在本地文件系统之上?本地文件系统ext4有什么特点
- 复用成熟组件:本地文件系统(如ext3/ext4)已提供稳定的块管理、空间分配、磁盘I/O调度等基础功能。GFS直接在ChunkServer层重用这些能力,避免了从零开发物理存储管理的复杂性,大幅缩短研发周期【没有人从0开发一套系统】
- 聚焦核心创新:GFS的核心价值在于分布式元数据管理、多副本一致性、大规模负载均衡等高层设计。将资源集中于这些创新点,而非重复实现底层功能,更符合Google的工程目标
- 追加写入优化:GFS的核心操作是追加写入(Append),本地文件系统对顺序写入的高效支持(如ext4的extent分配)可直接利用,无需自研写入路
Linux内核ext4 extent:解决大文件存储难题的关键?
 Extent 有效提升了顺序文件读写的性能,主要是因为 Extent 写入的描述连续块元数据量要少得多,从而减少了文件系统开销
Extent 有效提升了顺序文件读写的性能,主要是因为 Extent 写入的描述连续块元数据量要少得多,从而减少了文件系统开销
 假设存储一个 1GB 视频文件(256,000 个 4KB 逻辑块):
假设存储一个 1GB 视频文件(256,000 个 4KB 逻辑块):
- 物理分配:
- 磁盘预留 3 个连续物理块区(extent):
- Extent1:逻辑块 0-100,000 → 物理块 20000-120000
- Extent2:逻辑块 100,001-200,000 → 物理块 150000-250000
- Extent3:逻辑块 200,001-256,000 → 物理块 300000-356000
- 磁盘预留 3 个连续物理块区(extent):
- B+树结构:
- 根节点存储 3 个
ext4_extent(直接映射,无需索引层)。
- 根节点存储 3 个
- 读取性能:
- 顺序读取时,仅需 3 次磁盘寻道(每个 extent 连续访问),而 Ext3 需 25 万次寻道
- Ext4 的 extent B+树 通过 连续物理块映射 和 动态层级扩展,解决了传统文件系统在大文件场景下的元数据膨胀与碎片问题。其核心优势在于
疑问5:为什么Chunk位置信息(chunk Locations )不持久化?
-
Master仅将文件和Chunk的命名空间、文件到Chunk的映射关系持久化存储在操作日志(Operation Log)中,并通过Checkpoint机制定期备份
-
Chunk位置信息(如Chunk副本分布在哪些Chunkserver上)不写入持久化存储,仅在Master内存中维护
-
问题:Chunkserver集群动态性强——节点频繁加入/退出、重启、更名、磁盘故障或人为操作(如禁用磁盘)可能导致Chunk副本突然消失
-
设计权衡:若持久化存储位置信息,Master需在每次集群变动时同步更新持久化数据,否则会与Chunkserver的实际状态不一致。这种同步机制需处理分布式事务,显著增加复杂性
-
解决方案:将Chunk位置信息的“权威源”下放至Chunkserver自身(Chunkserver最清楚自身磁盘状态),Master仅作为缓存层,通过心跳机制动态同步,避免强一致性维护的开销
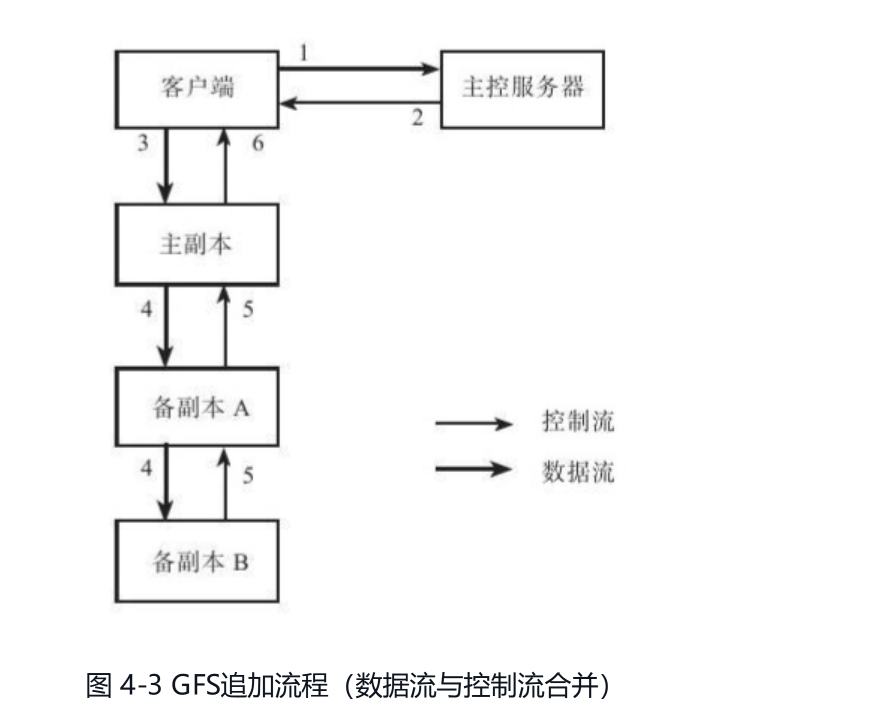
疑问6 GFS 追加写流程是什么?为什么客户数据发送过不是主节点呢?
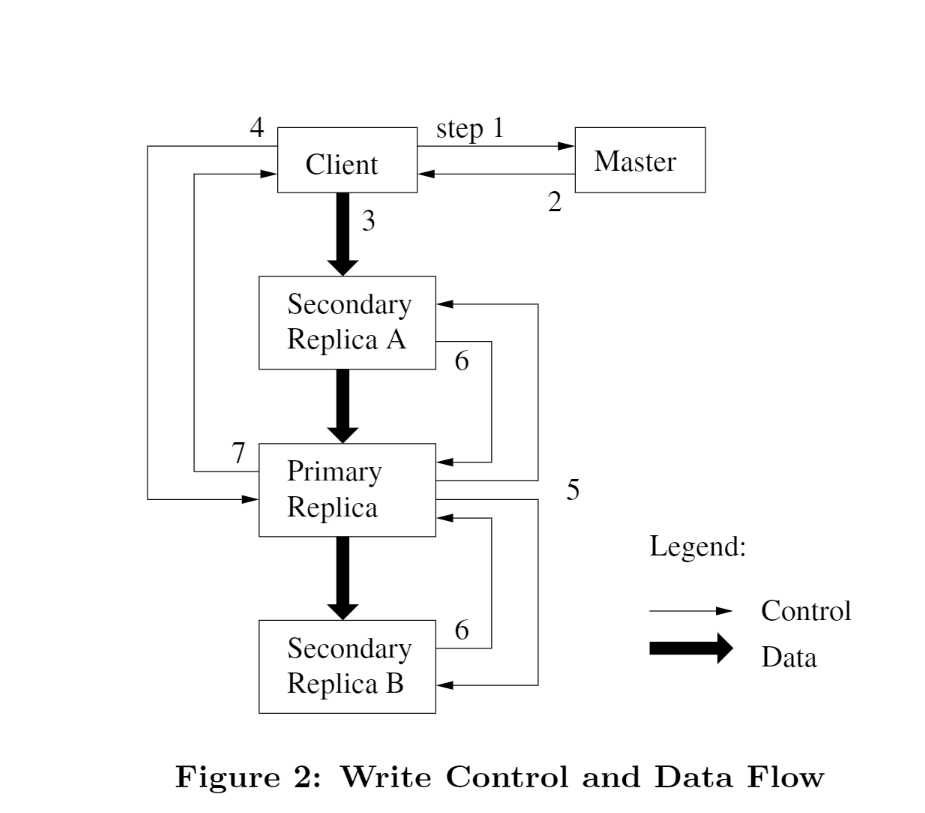
GFS追加流程有两个特色:流水线及分离数据流与控制流。
论文【3.2 Data Flow】
To fully utilize each machine’s network bandwidth, thedata is pushed linearly along a chain of chunkservers ratherthan distributed in some other topology (e.g., tree
举个例子,假设有三台ChunkServer:S1、S2和S3,S1与S3在同一个机架上,S2在另外一个机架上,客户端部署在机器S1上。
如果数据先从S1转发到S2,再从S2转发到S3,需要经历两次跨机架数据传输;
相对地,按照GFS中的策略,数据先发送到S1,接着从S1转发到S3,最后转发到S2,只需要一次跨机架数据传输。
疑问6 什么场景采用数控分离,什么场景不采用
分离数据流与控制流的前提是每次追加的数据都比较大,
比如MapReduce批处理系统,而且这种分离增加了追加流程的复杂度。
如果采用传统的主备复制方法,追加流程会在一定程度上得到简化
普通写入是数控分离
客户发送 1 3 4 这三个命令
(1)当客户端要进行一次写入时,它会询问master哪个chunkserver持有这个chunk的租约,以及其他副本的位置。如果没有副本持有这个chunk的租约,那么master会挑选一个副本,通知这个副本它持有租约。
(2)master回复客户端,告诉客户端首要副本的位置和所有次要副本的位置。客户端联系首要副本,如果首要副本无响应,或者回复客户端它不是首要副本,则客户端会重新联系master。
3)客户端向所有的副本以任意的顺序推送数据。每个chunkserver都会将这些数据缓存在缓冲区中。
4)当所有的副本都回复已经收到数据后,客户端会发送一个写入请求(write request)给首要副本,在这个请求中标识了之前写入的数据。首要副本收到写入请求后,会给这次写入分配一个连续串行的编号,然后它会按照这个编号的顺序,将数据写入本地磁盘中。
(5)首要副本将这个带有编号的写入请求转发给次要副本,次要副本也会按照编号的顺序,将数据写入本地,并且回复首要副本数据写入成功。
(6)当首要副本收到所有次要副本的回复后,说明这次写入操作成功。
(7)首要副本回复客户端写入成功。在任意一个副本上遇到的任意错误,都会告知客户端写入失败。[这里没有回滚出来为什么?]
在GFS的写入流程中,步骤7明确表示“在任意一个副本上遇到的任意错误,都会告知客户端写入失败”,但未触发回滚机制
- 回滚成本过高
- 分布式协调开销:回滚需协调所有副本撤销已写入的数据,在跨机架、跨节点的网络环境下,协调通信延迟显著(尤其在数百节点集群中)。
- 部分成功状态的复杂性:若部分副本已写入而部分失败,回滚需精准定位已写入副本并执行逆向操作,可能引发二次错误
- GFS的核心设计目标
- 高吞吐优先于强一致性:GFS面向海量数据追加场景(如日志写入),追求整体吞吐量最大化。回滚会阻塞后续写入,降低系统并发能力
- 容忍部分不一致:GFS采用宽松一致性模型(Relaxed Consistency),允许副本间短暂不一致,通过客户端重试或上层应用(如MapReduce)处理脏数据。
GFS的建议:依赖追加(append)而不是依赖覆盖(overwrite)
-
写入模式差异
- 覆盖写入(Overwrite):在文件指定位置修改数据,可能破坏原有内容(如随机写)。
- 追加写入(Append):仅将新数据添加到文件末尾,不修改已有内容(如日志追加)。
- GFS 的取舍:因 Google 工作负载中 95% 的修改是追加操作(如日志收集、流式数据生成),覆盖写需求极少
-
一致性模型的简化
- 覆盖写入的挑战:需保证多副本的原子性和顺序性,需复杂锁机制或分布式事务,显著增加延迟。
- 追加写入的优势:天然支持原子性(至少写入一次),通过 租约机制(Lease) 由 Primary 副本统一分配偏移量,无需全局锁
- 案例:100 个客户端并发追加日志时,GFS 可并行处理;若用覆盖写,需协调写入位置,性能骤降
-
硬件特性适配
- 机械磁盘顺序写吞吐量是随机写的 100 倍以上,追加写最大化利用磁盘带宽
- 网络传输中,数据管道化推送(客户端→最近副本→其他副本)减少跨机架流量
| 维度 | 追加写入(Append) | 覆盖写入(Overwrite) |
|---|---|---|
| 一致性保证 | 原子追加(至少一次),状态为已定义 | 需强一致性协议,易出现不一致 |
| 并发能力 | 支持多客户端无锁并行 | 需分布式锁,并发性能低 |
| 硬件利用率 | 最大化顺序 I/O 吞吐 | 随机写导致磁盘性能瓶颈 |
| 空间开销 | 存在填充/重复数据,但可控 | 无额外占用,但需预留空间防碎片 |
| 适用场景 | 日志、流式数据、生产者-消费者队列 | 数据库事务、随机更新 |
参考文章
- Google File System 论文详析
- MIT 6.824 的课
- Ext4文件系统的delalloc选项造成单次写延迟增加的分析
- linux内核源码:ext4 extent详解
- ext4 extent详解1之示意图演示
- GFS与MapReduce的实现研究及其应用
每天收获一小点,快乐生活一整天!
我在寻找一位积极上进的小伙伴,
一起参与神奇早起 30 天改变人生计划,发展个人事情,不妨 试试
1️⃣ 加入我的技术交流群Offer 来碗里 (回复“面经”获取),一起抱团取暖
 2️⃣ 关注公众号:后端开发成长指南(回复“面经”获取)获取过去我全部面试录音和大厂面试复盘攻略
2️⃣ 关注公众号:后端开发成长指南(回复“面经”获取)获取过去我全部面试录音和大厂面试复盘攻略
 3️⃣ 感兴趣的读者可以通过公众号获取老王的联系方式。
3️⃣ 感兴趣的读者可以通过公众号获取老王的联系方式。
—————-我是黄金分割线—————————–
抬头看天:走暗路、耕瘦田、进窄门、见微光,
- 我要通过技术拿到百万年薪P7职务,打通任督二脉。
- 但是不要给自己这样假设:别人完成就等着自己完成了,这个逃避问题表现,裁员时候别人不会这么想。
低头走路:
- 一次专注做好一个小事。
- 不扫一屋 何以扫天下,让自己早睡,早起,锻炼身体,刷牙保持个人卫生,多喝水 ,表达清楚 ,把基本事情做好。