从青铜到王者系列:跟着文件系统学数据结构

文章目录
老师好,小义同学,这是大厂面试拆解——项目实战系列的第8篇文章。
知识地图:深入理解计算机系统—文件子系统
一次只讲清楚一个问题:
阅读本文你将获得以下收益:
- ✅ ext4文件系统为了支持单个文件最大16TB存储,采用哪些数据结构?
- ✅ 文件在创建、打开、读取过程中与上述数据结构有什么关系?(分析中)
“走暗路、耕瘦田、进窄门、见微光"告诉我,面试关键就在于深入理解自己的项目,这才是最考察基本功的地方。然而现实情况往往是这样的:
- 第一家公司A:面试官问同样一个项目问题,没有回答出来,直接拜拜。
- 公司A没有复盘明白,换下一家公司B面试,还是面试同样问题,还是回答不出来,直接拜拜。
- 第三个公司C继续去面试,同样问题回答不出来,直接拜拜。
- 过几年再去面试,还是面试同样问题。
为什么会这样?
-
对同一个行业来说,面临都是相同业务场景,采用相同技术方案,差别就在于深入理解。有的企业通过添加机器解决,有的企业引用开源软件解决,有的企业需要定制开发。差距一个天上,一个地下。因为这些问题面试官根据业务挑选出来的题目,同一个题目卡住上千人、上万人,面试官不需要换题目。因为这就是行业最难挑战。仅仅看书,仅仅背诵八股文无法解决。
-
你10+年工作经验的程序员,面试官至少P6、P7标准考察。企业需要什么人才?面试官只出一个项目题目,一个算法题目,就彻底考察一个候选人。必须超预期回答,不能像刚毕业那样回答,只沉浸在当时项目中。当时项目一钱不值,面试目的不是一个人写一个功能,而是一个人挑战整个行业。你要说自己可以,我行,在基础知识方面你做到最强。
-
工作10年,面试官招聘的是一个人独立负责一个特性,给公司解决问题的,而不是什么设计好,按部就班。那个实习生、应届生,我已经没有这样待遇了。考察的是过去积累,而不是仅仅岗位。
答疑1:通过提供数据结构来数据EXT4文件系统
ext4文件系统为了支持单个文件最大16TB存储,采用哪些数据结构?可视化的逻辑结构和代码实现怎么对应的?
这里假设你熟悉了
- 了解严老师写的<数据结构>(C语言版)逻辑结构(不用紧张,非代码实现),参考一下 通过动画可视化数据结构和算法。
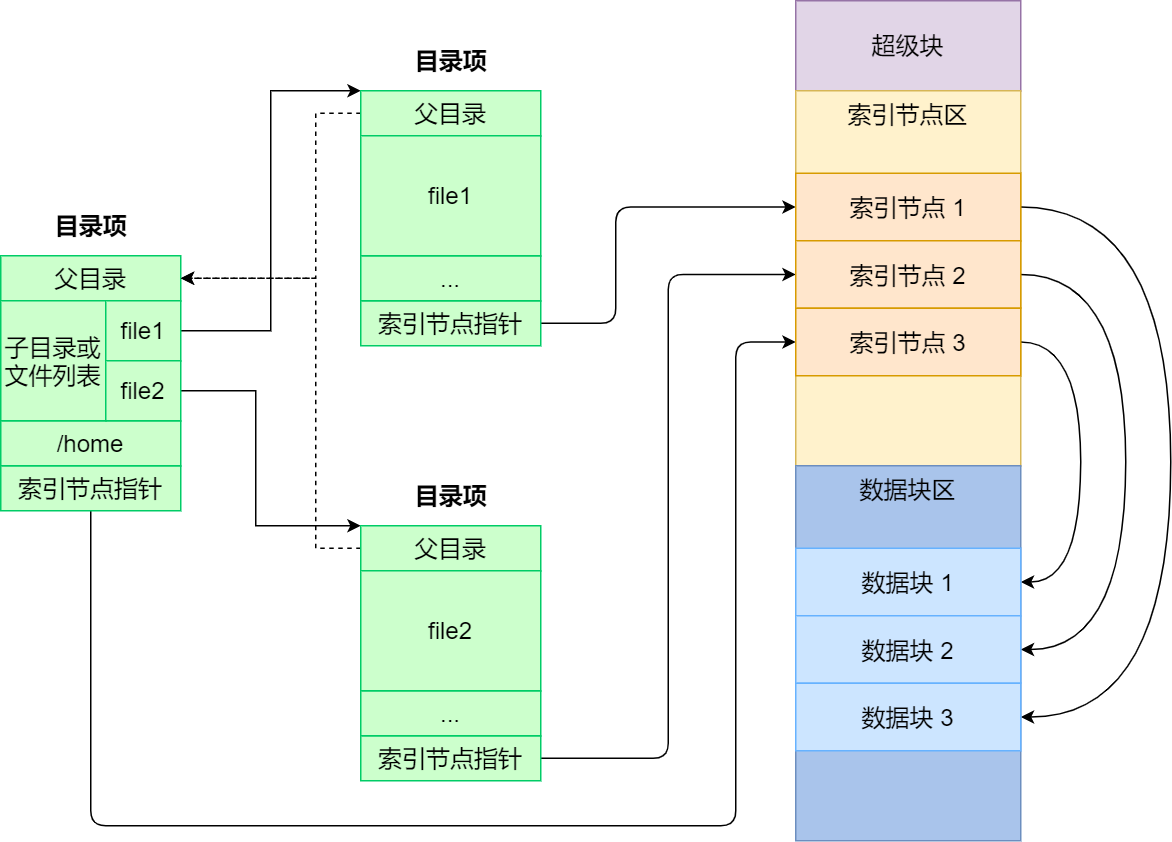
- **了解文件系统基本组成部分- 目录项,索引节点,逻辑块,,超级块
 小提示:为什么非要打破砂锅问到底(这个提示有点长)
小提示:为什么非要打破砂锅问到底(这个提示有点长) - 在日常生活中,通过网络搜集搜集到资料, 感觉有问题但是描述不出来,这就是 实践最好时机,现在要做事情把模糊感觉变成一个具体问题,如果无法变成具体问题,根本无法作者交流,只会点赞收藏,这个毫无意义,后面忙碌工作就淡忘。这给自己抱怨,不是我不想学,被安排太多事情,哪怕后面有时间也不会看,这个最可怕的事情,别人全能人,自然全能角度衡量,不仅要完成工作,还要搞懂原理,具体你怎么搞,抽时间我不管,谁记得 因为忙碌工作,,现在5分钟内,把模糊感觉变成具体需求?无论大小,无论难易都接受。5分钟,提出一个好问题 就相当于完成20% ,因为不去做后果太可怕了,承受不了,
- 把模糊感觉变成一个具体问题 最低成本,最有效方式,公司架构师,项目经理,SRE是最直接了解事情根本根本的,他们项目支持,各种环境支持,各种问题支持,你根本不具备这样资源,更具备这样能力,让你设计项目可以吗不可以,让独立解决一个问题可以吗 不可以?,自放弃专门项目,专门问题自己练手,你会说,可以问他们呀,他们无数项目,无数个问题等着解决,根本没时间,关键自己自己说不出来,都是无效沟通,因此第一直觉就是第一生产力,也是最直接最重要一个问题,在坚持5分钟 完成30%
- 怎么做?别人怎么做,就跟踪怎么做,搜集别人写文章,别人视频,自己不停练习,练习,从h这样最简例子开始,不停演进,在演进,在技术资料面前,大家看到都是一样的,
-
不要说我不是专家,我不是领导,没有项目支持,没有客户驱动,都是瞎研究,无组织,无纪录,毫无价值和意义 公司百万千万客户项目你根本没有这个能力, 既然他出现在面前 ,就是说明是你需要急需要解决事情,是看的到,听到事情,伸手够到事情,不要100%了解,不要 拿出100%研究,至少想别人解释清楚 这是什么,最后别人一问三不知,让别人鄙视不如自己鄙视自己,从疑惑地方开始。
-
自己探索一番,不过消耗你时间和精力,不到导致部落战争牺牲xx人,不会导致重大决策失败损失xxx 亿,你根本影响别人,公司早就不同岗位划分隔离好了。不会别人挣多少钱,不给比人造成多大影响,放下担心,专注目前15分钟 就是要做事情。
1.1 目录项 采用什么数据结构存储

主要内容
- Linear (Classic) Directories
- Hash Tree Directories
| 特性 | 线性目录(如Ext2) | Htree目录(如Ext4) |
|---|---|---|
| 查找效率 | O(n)(需遍历所有项) | O(log n)(哈希过滤) |
| 适用场景 | 小规模目录(<1000项) | 大规模目录(百万级项) |
| 存储开销 | 低 | 较高(需额外索引块) |
| 扩展性 | 差 Directory scalability | 支持动态分裂与多级索引 |
 |
举例说明:
一个目录下多个文件
|
|
目录本质也是一种文件,但是这种目录文件的内容,
是其下文件或目录的inode与文件名信息。
|
|
当然了,这只是示意,目录中记录的条目并非这么简单了,但也并不复杂,结构体如下:
|
|
| Offset | Size | Name | Description |
|---|---|---|---|
| 0x0 | __le32 | inode | Number of the inode that this directory entry points to. |
| 0x4 | __le16 | rec_len | Length of this directory entry. Must be a multiple of 4. |
| 0x6 | __le16 | name_len | Length of the file name. |
| 0x8 | char | name[EXT4_NAME_LEN] | File name. |
| 就是一个数组呀, |
-
适合目录下文件数目比较少的情况下,一个块存储。那么为了获取子文件的inode,一次io操作完成
-
如果一个目录下有几十万个条目,一旦需要几十几百个block?需要多次IO怎么处理?
dir_index 特性:
-
线性目录项不利于系统性能提升。因而从ext3开始加入了快速平衡树哈希目录项名称
-
Ext4基于HTree的增强方案,在已有数据块的结构基础之上,新增了一层或多层的hash索引

场景假设:
假设目录/docs下有多个文件:file1.txt、image.jpg、report.pdf等,
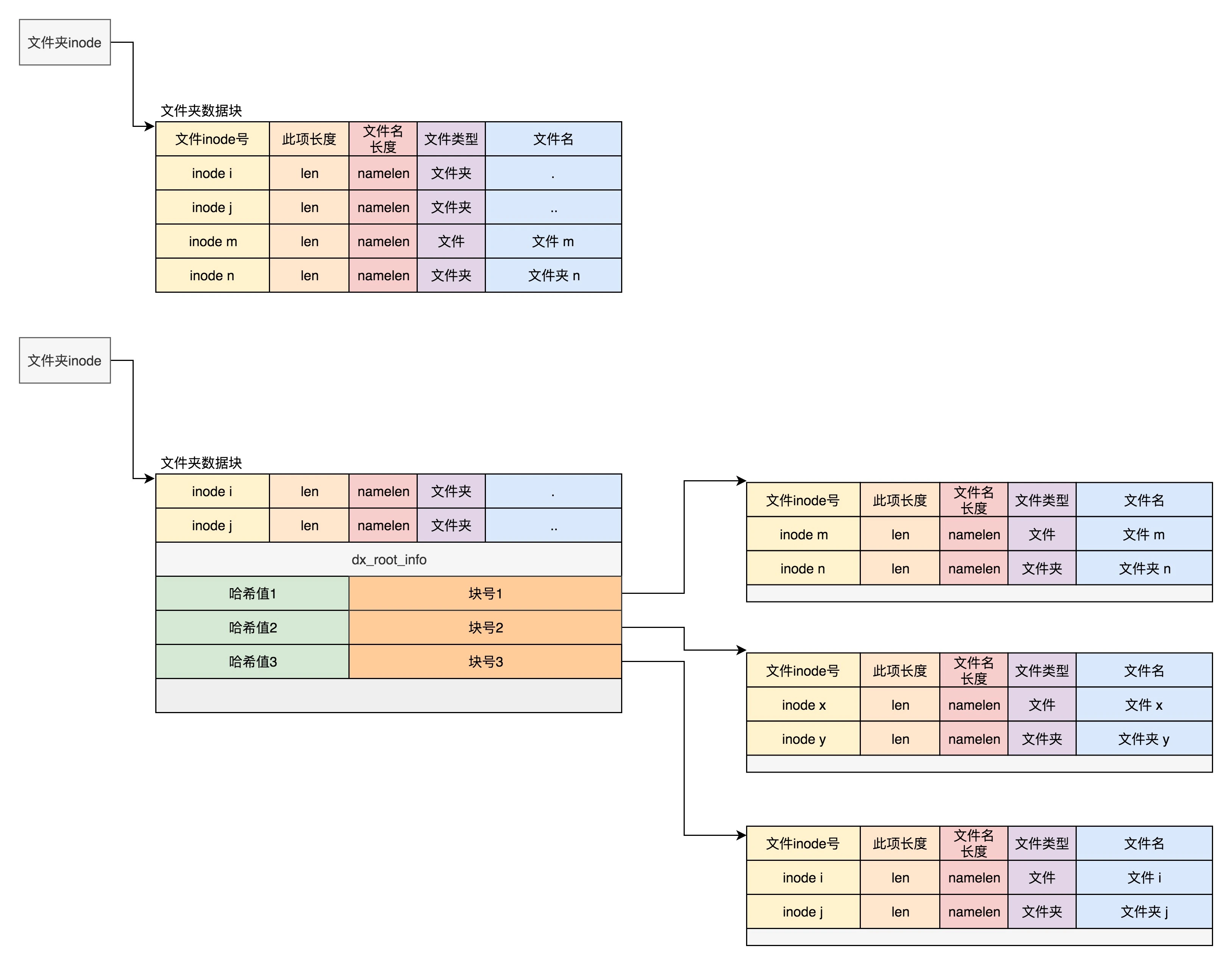
Htree的存储结构如下:
|
|
关键组件:
- DX-block(索引块):存储哈希范围与子块地址的映射(如
[0-1000] → 块1) - DE-block(数据块):存储实际目录项(文件名、inode ID等),内部不排序,但通过哈希范围过滤—这个和原来存储方式一样
- 哈希值:由文件名计算得出,决定目录项所属的块。
对应代码
**Htree的根 :struct dx_root
|
|
 索引项由结构体 dx_entry表示,本质上是文件名的哈希值和数据块的一个映射关系。
索引项由结构体 dx_entry表示,本质上是文件名的哈希值和数据块的一个映射关系。
|
|
如果我们要查找一个目录下面的文件名,可以通过名称取哈希。
通过索引树,我们可以将一个目录下面的 N 多的文件分散到很多的块里面,可以很快地进行查找
Ext4文件系统的目录索引采用两层哈希B树(Hash B-tree)结构 其本质是哈希表与B树的结合体
可以通过debugfs工具查看目录的哈希树信息
小王疑问:为什么ext4目录项索引采用选用 HTree,而不是B+
HTree 是一种专门用于目录索引的树形数据结构 ,类似于 B 树 。
它们的深度恒定为一级或两级,扇出因子较高,使用文件名的哈希值 ,并且不需要平衡 。
而是为了大目录场景专门设计的,HTree 索引用于 ext3 和 ext4 Linux 文件系统 ,并于 2.5.40 左右被合并到 Linux 内核中。
| 特性 | Htree(Ext4目录) | B/B+树(如MySQL索引) |
|---|---|---|
| 索引键 | 文件名哈希值(非有序) | 主键或索引字段值(有序) |
| 存储粒度 | 目录项块(如4KB) | 数据页或磁盘块(如16KB) |
| 查询类型 | 精确匹配(等值查询) | 范围查询、排序、最左前缀匹配 |
| 结构扩展 | 哈希冲突时分裂数据块 | 节点填充度不足时分裂或合并 |
HTree 与 B-tree/B⁺-tree 的比较
| 特性 | HTree | B-tree / B⁺-tree |
|---|---|---|
| 树高 | 常数(1 ~ 2 层) | 随数据量增加而增加 |
| 扇出 | 高(数千) | 较低(几十到数百,取决于节点大小) |
| 平衡 | 无需平衡 | 需分裂/合并以保持平衡 |
| 键排序 | 按哈希范围分布,不保证时序 | 保证键的有序存储 |
| 冲突处理 | 溢出块或二级索引 | 不存在哈希冲突(键唯一排序) |
| 查找复杂度 | O(1)~O(深度) ≈ O(1) | O(logₙ N) |
| 元数据开销 | 较小(只存哈希与指针) | 较大(存键-值对或指针、维持平衡信息) |
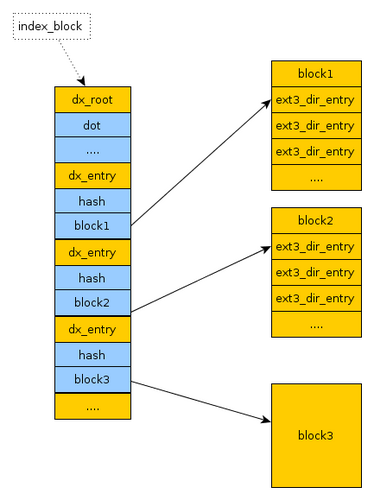
演示如下:

上图展现了一个简单的两级 HTree 结构示例:
-
根节点(Root Node):存储一组哈希范围和对应的指针,例如
[0–1000] → Leaf Node 1,[1001–2000] → Leaf Node 2。查找时,先对文件名计算哈希值,落在某个范围内就跟随指针进入相应叶子节点。 -
叶子节点(Leaf Nodes):包含目录项实际记录(或指向溢出块的链表),这里示例中:
- Leaf Node 1 负责存储哈希值在 0–1000 范围内的文件名条目;
- Leaf Node 2 负责存储哈希值在 1001–2000 范围内的文件名条目。
HTree 关键点:
- 定深度:此例中总共两层,深度不会随着条目增长而变化,定位只需访问根+叶,访问次数恒定。
- 高扇出:在真实场景中,一个节点可包含数百到上千个哈希范围/指针,进一步减少深度。
- 哈希索引:使用哈希值作为键,不需要维护有序性,不进行节点分裂或合并,简化元数据更新并加速查找。
By default in ext3, directory entries are still stored in a linked list, which is very inefficient for directories with large numbers of entries.
The di-rectory indexing feature addresses this scalability issue by storing directory entries in a constant depth HTree data structure, which is a specialized BTree-like struc-ture using 32-bit hashes
Htree操作
Htree是持久存储于目录的数据块中,用来维护目录项布局的一种持久化数据结构。针对Htree有以下操作:
- 查找(lookup):在htree中查找目录项或者查看某文件名是否存储于该目录;
- 插入目录项:在htree定位路径的DE-block中插入一个目录项;
- 删除目录项:在htree定位路径的DE-block删除一个目录项;
- 分裂DE-block:如果目录项正在插入一个满的DE-block,那么将会分配一个新的块,原来的DE-block中一半的目录项将会迁移到新分配的块中;—不需要重新调整平衡
- 分裂DX-block:在分配一个新的DE-block时,需要将它插入到父DX-block。当DX-block满了的时候,会造成DX-block的分裂;—不需要重新调整平衡
1.2 inode采用什么数据结构进行存储?
别人咀嚼过的内容,可能过时内容不是ext4的
|
|
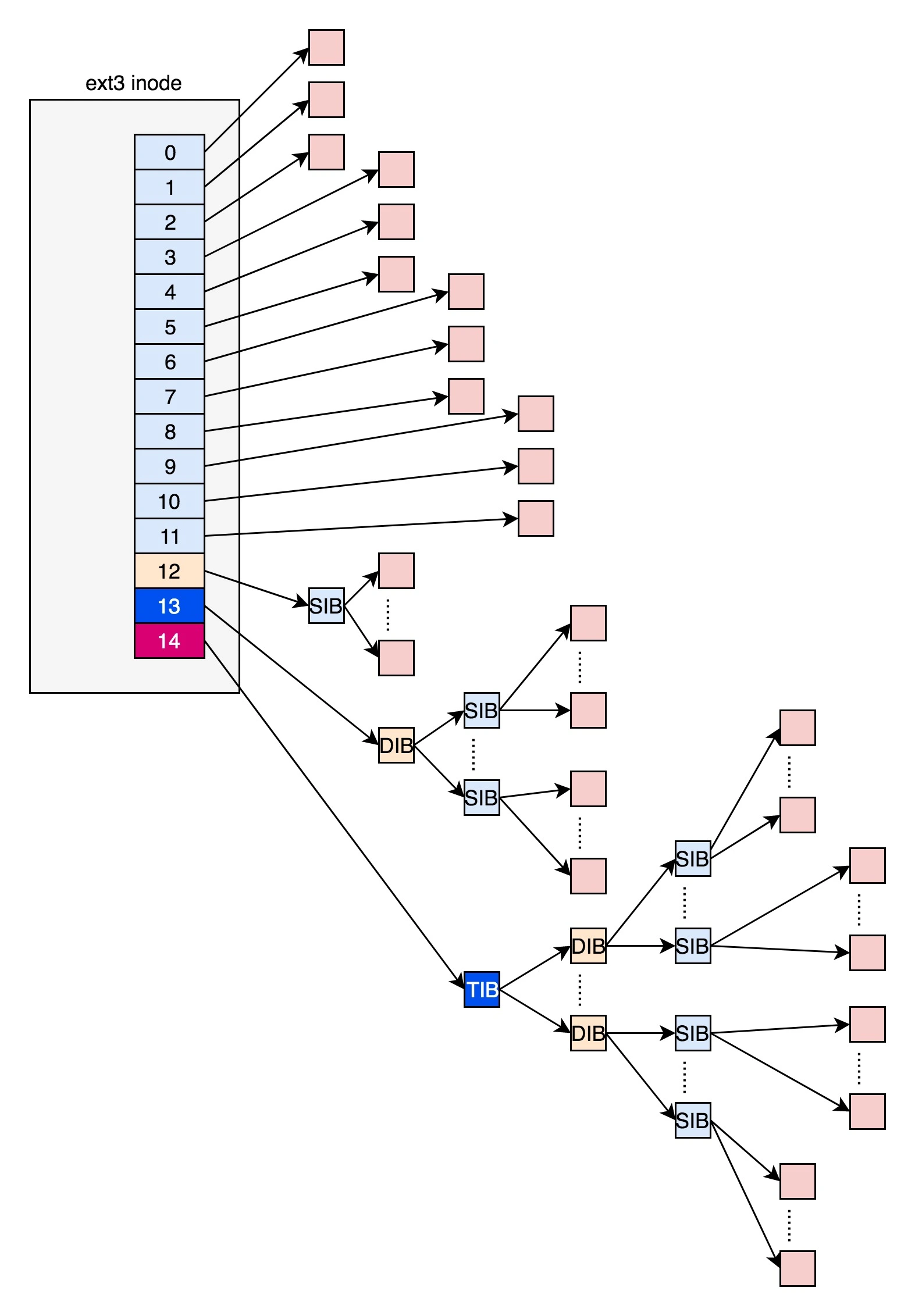
ext3 文件系统使用间接块映射方案,提供从逻辑块到磁盘块的一对一映射。
这种方案对于稀疏或小文件非常有效,但对于较大文件的开销很高 现在你应该能够意识到,这里面有一个非常显著的问题,
对于大文件来讲,我们要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。
ext4_extent 就像是一张"纸条”,用来记录文件里一段连续数据在硬盘上的位置和长度,比 Ext3 记"每一块"的方式要高效得多.


疑问:不对呀,从数据结构定义 根本和An extent tree 没有关系呀?
|
|
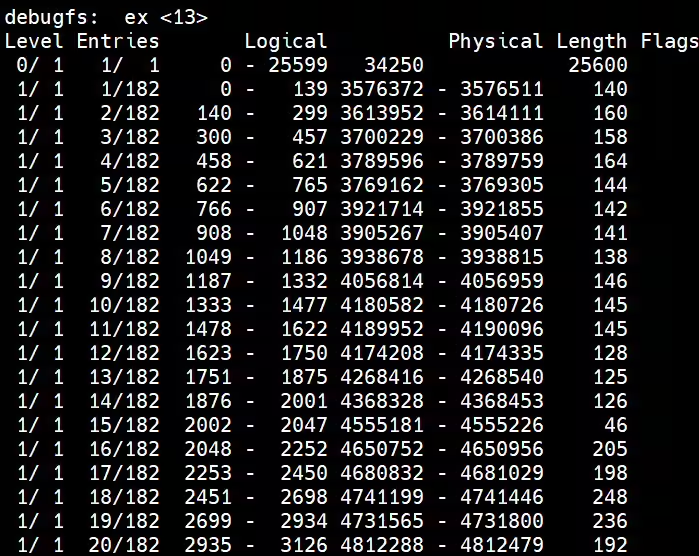
在 ext4 文件系统中,
__le32 i_block[EXT4_N_BLOCKS] 数组通过 B+树结构 实现 extent(区段)关系
|
|
i_block[3]~i_block[15] 共 12 个元素(每个 4 字节)动态存储两类数据:
- 叶子节点(
ext4_extent结构):描述文件逻辑块到物理块的连续映射
|
|
- 索引节点(
ext4_extent_idx结构):指向下一层 B+树节点
|
|

请问:这个图片隐藏什么内容,数组 怎么存储一个tree结果呢?
如果文件不大,inode 里面的 i_block 中,可以放得下一个 ext4_extent_header 和 4 项 ext4_extent。所以这个时候,eh_depth 为 0,也即 inode 里面的就是叶子节点,树高度为 0。
|
|
如果文件比较大,4 个 extent 放不下,就要分裂成为一棵树,eh_depth>0 的节点就是索引节点,其中根节点深度最大,在 inode 中。最底层 eh_depth=0 的是叶子节点
|
|
i_block数组的两种模式
请一定看 https://docs.kernel.org/6.0/filesystems/ext4/dynamic.html#the-contents-of-inode-i-block
inode.i_block can be used in different ways.
在 ext4 中,i_block数组(定义于 struct ext4_inode)有两种使用模式,由 i_flags 中的 EXT4_EXTENTS_FL 标志位决定:
- 传统间接块模式(兼容 ext2/ext3)
i_block[0-11]直接存储数据块号,i_block[12-14]指向间接块(一级、二级、三级)- 适用于未启用 extent 的文件或旧版本兼容场景。
- extent B+树模式
i_block存储 B+树的根节点,包含ext4_extent_header和多个ext4_extent或ext4_extent_idx项- 启用条件:文件创建时设置
EXT4_EXTENTS_FL标志(通过ext4_set_inode_flag()函数
演示ext4 extent B+树的形成过程
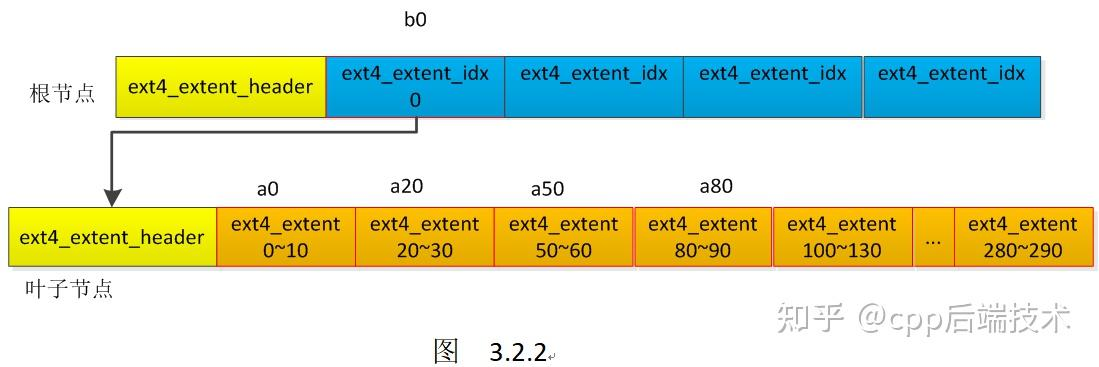
3.1 根节点4个extent插入过程
最开始,ext4 extent B+树是空的
 好的,现在我们把这个ext4_extent插入到ext4 extent B+树,如下所示:
好的,现在我们把这个ext4_extent插入到ext4 extent B+树,如下所示:
 好的,现在当然需要3个ext4_extent保存这3段逻辑块地址与物理块地址的映射关系,并插入到ext4 extent B+树,全插入后如下所示:
好的,现在当然需要3个ext4_extent保存这3段逻辑块地址与物理块地址的映射关系,并插入到ext4 extent B+树,全插入后如下所示:

3.2 根节点下的叶子节点extent插入过程


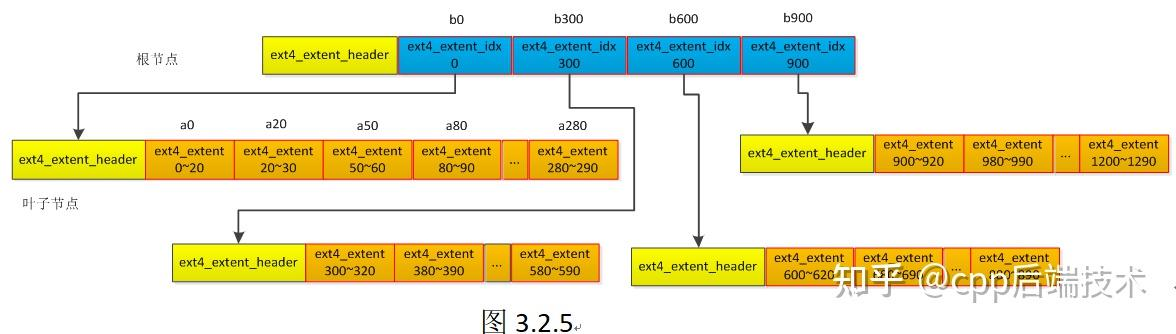

疑问2:IO读写过程
上来 先别直接分析io过程过程 ,假如io高楼大厦的话,那么 第一次地基是什么
文件拆分
- 如何创建一个文件 mkdir a b c 过程是什么(readdir)
- 如何从目录下查找一个文件 cat /mnt/icfs/test/a
- cat /mnt/icfs/test/a
- 和上面数据结构有什么关系?
流程分析
dd if=/dev/zero of=/root/c++/test bs=1M count=16
blktrace -d /dev/loop0 -o - |blkparse -i -
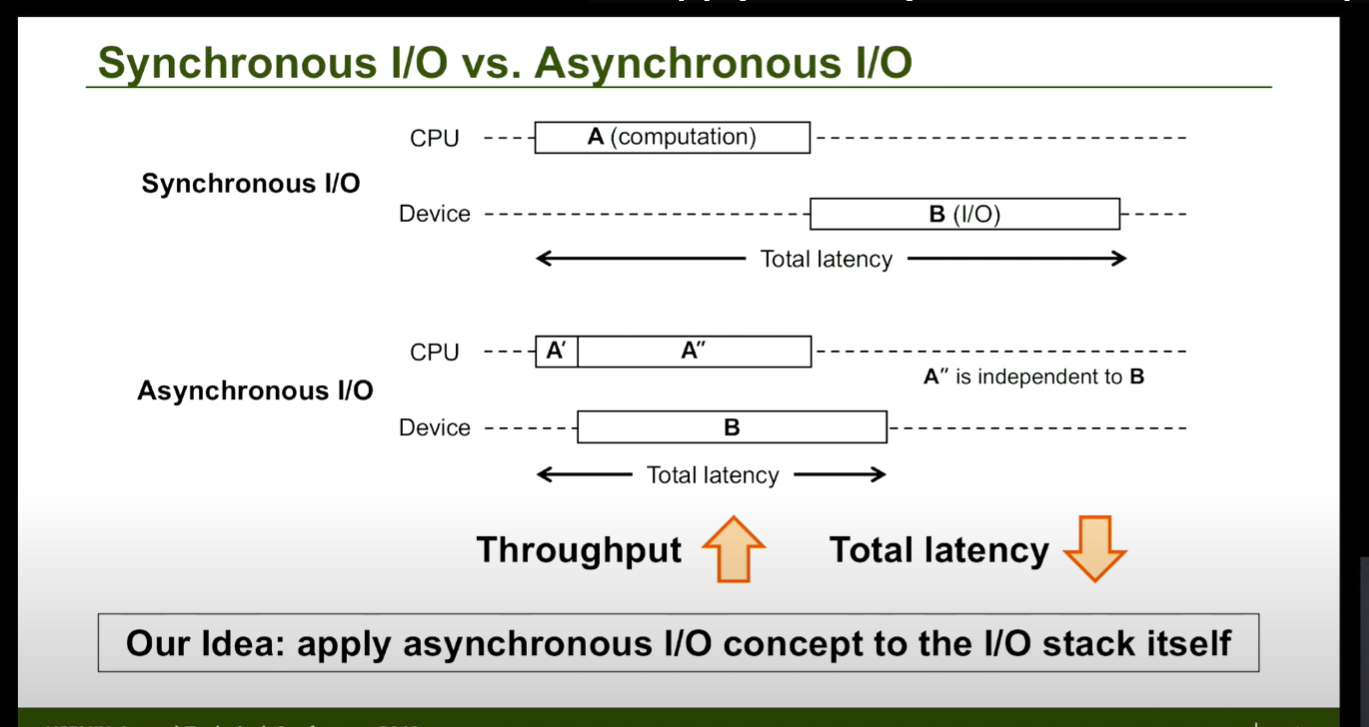





请问疑问:文件io读过程,文件目录怎么读取,内容怎么读取
-
Directory Entry Lookup in ext4
- When we request the kernel to look up a file, the kernel goes through the following process:
当我们请求内核查找一个文件时,内核会经历以下过程:
- It obtains the inode and dentry of the parent directory.
它获取父目录的 inode 和 dentry。 - From the inode, it reads the extent tree information and retrieves the location of the dx_root of the hash tree (htree).
它从 inode 中读取范围树信息并检索哈希树 (htree) 的 dx_root 的位置。 - Using the hash value of the requested file, it traverses through the htree to locate the leaf block that contains the directory entry (dirent) of the requested file.
使用所请求文件的哈希值,它遍历 htree 来定位包含所请求文件的目录条目(dirent)的叶块
对比:
- CephFS 则通过碎片化将单一目录拆分,客户端可并行地查询不同碎片,并利用 RADOS 的高并发访问特性避免单节点 I/O 瓶颈。
- CephFS 的目录查找仍然依赖 MDS 授权(capabilities)及碎片映射算法,但文件数据和多数元数据读取可 绕过 MDS,直接与 OSD/RADOS 交互,提升可扩展性
| 阶段 | ext4 (HTree) | CephFS (MDS + dirfrags) |
|---|---|---|
| 父目录 inode 获取 | dcache → page cache → 磁盘读取 | 本地 capability 缓存,必要时向 MDS 发起 lookup |
| 文件布局定位 | extent tree → dx_root → 磁盘物理块 | MDS journaling → RADOS metadata pool → 客户端缓存 inode 布局 |
| 目录项查找 | HTree hash 遍历 → dirent | 目录碎片化 → RADOS 对象直接读取 → 在片段中查找 dentry |
从上述对比可见,ext4 完全在单机层面依赖页缓存和 HTree,
而 CephFS 则在集群环境下通过 MDS 分发元数据与目录碎片化设计, 实现了面向大规模并发和海量条目的可扩展目录查找【大规模 通过添加机器实现,在单个数据结构设计不合理,还是常规map set实现】
. 客户端如何"知道"数据在哪 3.1 客户端侧计算
- 客户端通过 librados 拉取最新 CRUSH Map。
- 写入时,库根据对象名/PG 走 CRUSH 算法,计算出 Primary 和 Secondary OSD 列表。
- 读取时,同样用 CRUSH 算法计算并直接联系相应 OSD,无需 MDS 或 MON 中
青铜疑问:在写文件过程中
第一手资料
[1] An Introduction to the Linux Kernel Block I/O Stack
- 来源:https://chemnitzer.linux-tage.de/2021/media/programm/folien/165.pdf
- Linux文件读写(BIO)波澜壮阔的一生
- Linux通用块设备层
- IO路径流向初探
- 了解IO协议栈 https://www.slideshare.net/slideshow/io-12278640/12278640
[2] 论文: Rearchitecting Linux Storage Stack for µs Latency and High Throughput
- 原文:https://www.usenix.org/conference/osdi21/presentation/hwang
- 翻译:重新构建 Linux 存储堆栈以实现 μs(微妙) 延迟和高吞吐量
- 社区中普遍认为,使用 Linux 内核堆栈时不可能实现 μ 级的尾部延迟–如何解
- blk-switch 为 Linux 存储堆栈引入了一个按内核、多出口队列块层架构
- 主要介绍了两种存储栈结构:
- 现有存储堆栈:低延迟或高吞吐量,但不能同时满足两者。 在 Linux 存储堆栈的早期版本中,所有核提交的请求都在一个队列中处理 完全公平调度程序 (CFS):在共享内核的应用程序之间平均分配 CPU 资源,毫秒时间尺度,分配时间
- SPDK(广泛部署的用户空间堆栈)
- USENIX ATC ‘19 - Asynchronous I/O Stack: A Low-latency Kernel I/O Stack for Ultra-Low Latency SSDs
- https://www.youtube.com/watch?v=ri1MrvJnbSU
- https://www.youtube.com/watch?v=BBONTH-BZvU&t=352s
【3】 Ext4(The fourth extended file system)
- 论文:The new ext4 filesystem: current status and future plans
- https://github.com/MoonShadowzzc/Data-Structure
- 刨根问底:Ext4文件系统目录下可以存放多少子文件
- Lustre并行目录操作的设计与实现 ✅ note 结构可视化
- EXT4 的 dir_index 特性✅阅读完成
- [fs] 与ext4_dir_entry_2相关的ext文件系统知识 ✅ 阅读摘要 目录也是文件
- https://ty-chen.github.io/linux-kernel-fs/ # Linux操作系统学习笔记(十一)文件系统
- 一篇文章理解Ext4文件系统的目录
-
ext4 Data Structures and Algorithms
- How ext4 File system is changing directory entry structure form linear to Htree?
-
理解 Ext4 磁盘布局,第 2 部分 https://blogs.oracle.com/linux/post/understanding-ext4-disk-layout-part-2
3. Linux内核源码:ext4 extent详解
- https://mp.weixin.qq.com/s/GjwnocmX-akq5b9W2Zwl4g
- [文件系统(六):一文看懂linux ext4文件系统工作原理]
- https://docs.kernel.org/6.0/filesystems/ext4/dynamic.html#the-contents-of-inode-i-block
4. 文件系统技术内幕
- https://github.com/lvsoso/fs-tech-inside-story
- 文件系统源码分析之inode.c