IO的一生

文章目录
大家好我是小义同学,这是大厂面试拆解——项目实战系列的第6篇文章,
”走暗路、耕瘦田、进窄门、见微光” 告诉我 面试关键就 深入理解自己项目 这个才是最考察基本功的地方。
知识地图:KV存储引擎—IO栈
本文 主要描述 read/write为例子普通文件 IO过程是什么?,
分析这个问题关键思路在哪里?
如果您觉得阅读本文对您有帮助, 请点一下“点赞,转发” 按钮, 您的“点赞,转发” 将是我最大的写作动力!
上篇文章 新一代存储引擎BlueStore,需四步
在创建一个文件时候,Ceph的BlueStore ,
- 将文件的数据直接写块设备
- 将文件的元数据写RocksDB
- BlueStore IO流程 先写数据,还是先写元数据顺序不同 ,提供不同策略。
- Ceph IO 软件栈开销原因 无实现低于 0.5 毫秒的随机读取延迟和低于 1 毫秒的随机写入延迟
普通文件写是否区分元数据 和 数据,这些请求最后怎么写入磁盘 呢?
因为内容太多,分批梳理。
大纲如下:
(1) 预备知识:
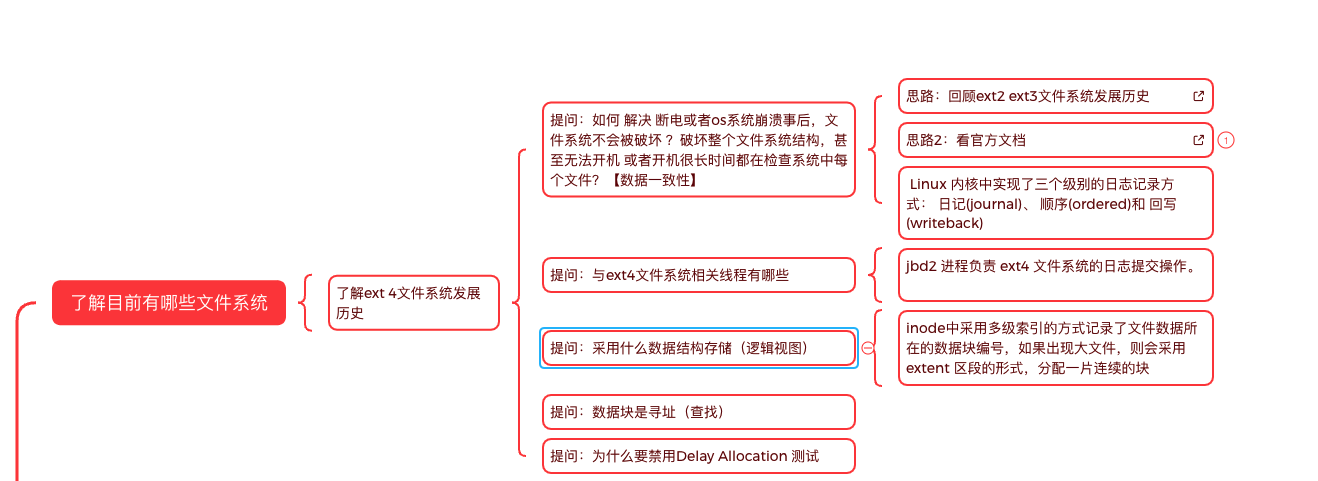
(2) 通过工具 了解IO栈
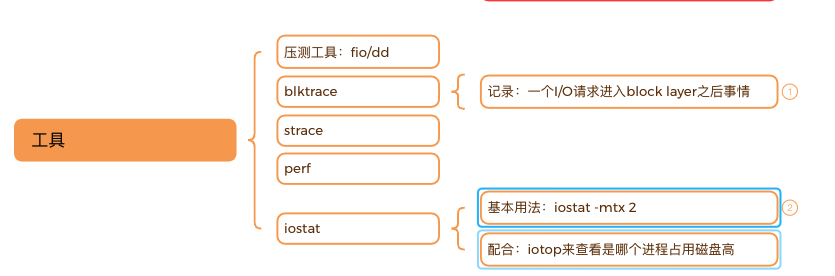 (3) 性能优化
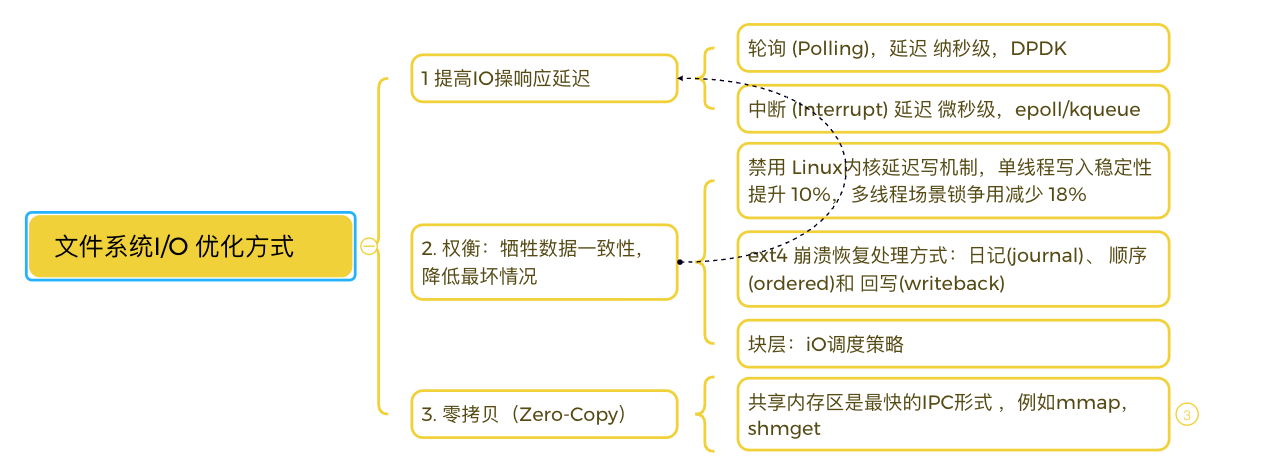
(3) 性能优化
一. 准备环境
1.1 机器配置
✅ 购买2C2G云主机 成本一年不超过100元
✅ 创建1G的大文件充代替块设备,因为没有额外的磁盘
📌 例子:用 Loop 设备模拟一个 ext4 文件系统
|
|
划重点:参数含义说明
文件系统支持的三种日志模式 是什么
- ext4挂载参数: data
| Journal特性 | Journal | Ordered(默认) | Writeback |
|---|---|---|---|
| 数据记录 | 元数据+数据均记录日志 | 仅元数据日志 | 仅元数据日志 |
| 数据写入顺序 | 严格同步 | 数据先于元数据写入 | 无强制顺序 |
| 性能 | 最低 | 中等 | 最高 |
| 崩溃恢复 | 完全一致 | 数据可能部分丢失 | 数据可能大量丢失 |
| 典型场景 | 数据库、关键业务 | 服务器、日常办公 | 高性能计算 |
- If
data=writeback, dirty data blocks are not flushed to the disk before the metadata are written to disk through the journal. - 内核有专门的机制负责将页缓存中的数据异步地写入磁盘,这个过程称为写回(writeback)。
| 延迟分配场景 | 推荐选项 | 原因 |
|---|---|---|
| 高吞吐量顺序写入 | delalloc |
利用批量分配优化连续写入性能(如日志服务器、大数据处理) |
| 低延迟关键业务 | nodelalloc |
避免单次写入延迟波动(如数据库事务、实时系统) |
2.1 块设备IO跟踪
|
|
一、字段含义与事件链分析
- 字段解析(参考示例行:
7,0 1 226 52.043115656 3815652 Q WS 1104864 +8 [jbd2/loop0-8])- 7,0:设备号(主设备号:次设备号),表示
/dev/loop0(虚拟块设备)。 - 1:CPU 核编号(此处为 CPU 1)。
- 226:事件序列号。
- 52.043115656:时间戳(秒级精度)。
- 3815652:进程 PID(jbd2 内核线程)。
- Q/WS:事件类型(Q=请求进入队列,WS=写同步操作)。
- 1104864 +8:起始块号
1104864,操作大小8个块(通常 1 块=4KB,即 32KB 写操作)。 - [jbd2/loop0-8]:进程名,表示
jbd2线程管理/dev/loop0设备的日志功能。
- 7,0:设备号(主设备号:次设备号),表示
- 事件链分析(关键阶段)
- Q→G 阶段(请求生成):
示例:Q WS 1104864 +8→G WS 1104864 +8
表示 I/O 请求进入块层后分配request结构体(耗时约微秒级)。 - I 阶段(插入调度器队列):
多行I WS事件显示请求被插入 I/O 调度器队列(如mq-deadline)。 - D 阶段(下发到驱动):
D WS表示请求被发送至设备驱动层,进入物理设备处理。 - U/FN 阶段:
U N表示队列解绑操作;D FN可能涉及屏障(Barrier)或刷新操作。
- Q→G 阶段(请求生成):
|
|
2.3从块层面 IO优化
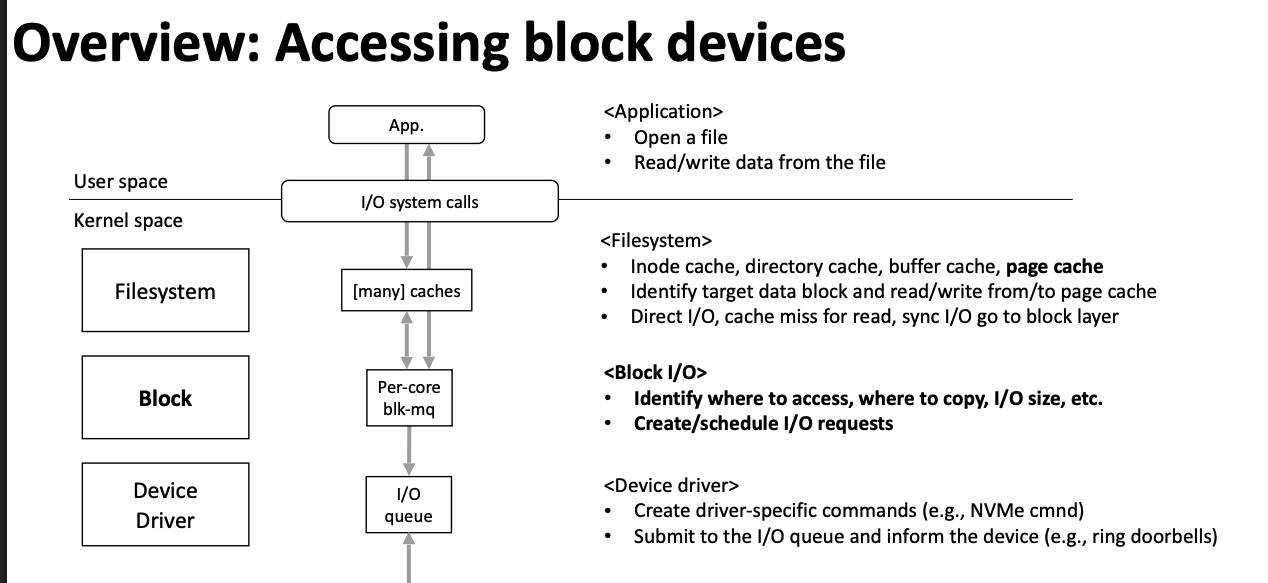
二. IO栈全景图
{kind=link}
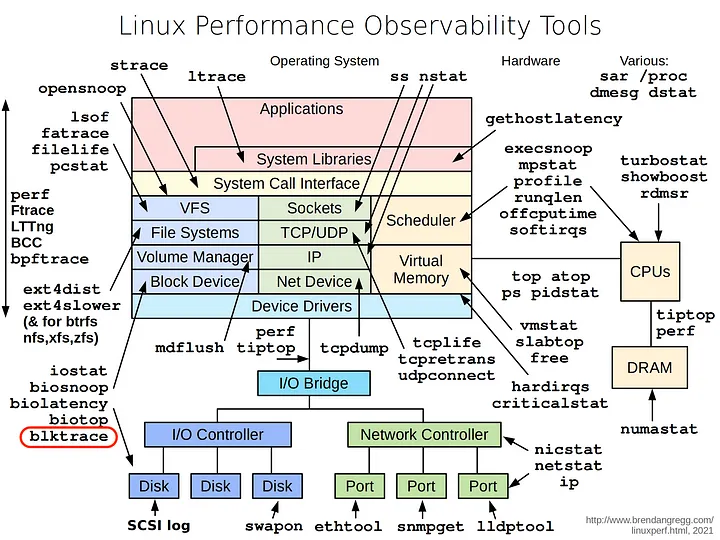
为了掌握IO栈必须了解的基本知识
- 什么是虚拟内存,与磁盘有什么关系? 这个是了解 块设备bio层基础
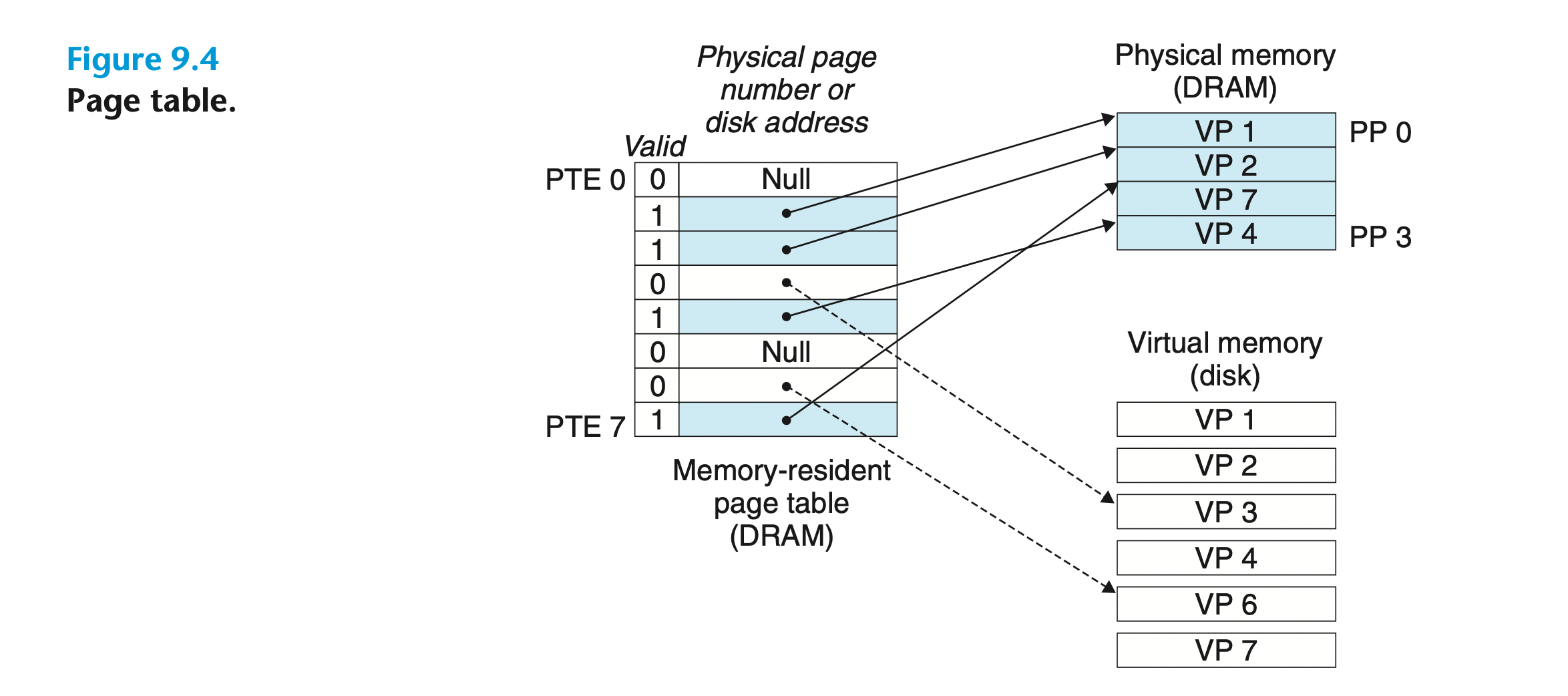 它将主存看成是一个存储在磁盘上的地址空间的 高速缓存,
在主存中只保存活动区域,
并根据需要在磁盘和主存之间来回传送数据,
通过 这种方式,它高效地使用了主存
它将主存看成是一个存储在磁盘上的地址空间的 高速缓存,
在主存中只保存活动区域,
并根据需要在磁盘和主存之间来回传送数据,
通过 这种方式,它高效地使用了主存
在任意时刻,虚拟页面的集合都分为三个不相交的子集: •未分配的:VM 系统还未分配(或者创建)的页。 未分配的块没有任何数据和它们相 关联,因此也就不占用任何磁盘空间。 •缓存的:当前已缓存在物理内存中的已分配页。 •未缓存的:未缓存在物理内存中的已分配页
-
地址空间(address space)是一个非负整数地址的有序集合【地址和数据关系】
-
—个 VM 系统是如何使用主存作为缓存
-
在虚拟内存的习惯说法中,DRAM 缓存不命中称为缺页(page fault)
-
在磁盘和内存之间传送页的活 动叫做交换(swapping)或者页 面调度(paging)。页从磁盘换入(或者页面调入)DRAM 和从 DRAM 换出(或者页面调出)磁盘。
-
三、IO性能优化采用手段
参考第一手资料
[1] Introduction to Perf
[2 ] etcd 在超大规模数据场景下的性能优化
- 英文:https://www.cncf.io/blog/2019/05/09/performance-optimization-of-etcd-in-web-scale-data-scenario/
- 摘要:当 etcd 存储数据量超过 40GB 后,经过一次 compact(compact 是 etcd 将不需要的历史版本数据删除的操作)后发现 put 操作的延时激增
- etcd 存储层可以看成由两部分组成,一层在内存中的基于 btree 的索引层,一层基于 boltdb 的磁盘存储层。这里我们重点介绍底层 boltdb 层,因为和本次优化相关
- https://www.qiyacloud.cn/2021/10/2021-10-08/
- https://www.qiyacloud.cn/2021/10/2021-10-21/
- 由一次 slow-request 浅谈 Ceph scrub 原理
- https://www.infoq.cn/article/Z9m5xkLYPlp95wyFtksm
- 可以看到rocksdb正在进行compacting,说明业务写请求比较多。 所以可确定本次slow-request的原因:大量的用户写入操作导致rocksdb进行compacting,加上deep-scrub进一步引发底层IO资源的竞争,最终导致用户请求超时
3. CRUSH 如何实现均匀分布
- CRUSH 算法能够快速定位存储设备对应的对象,并根据规则选择一个新的存储设备来存储对象,实现数据的自动恢复和重新分布。例如,当某个 OSD 出现故障时,CRUSH 算法会重新计算数据的存储位置,将原本存储在故障 OSD 上的数据迁移到其他正常的 OSD 上,确保数据的高可用性。同时,CRUSH 算法还能够根据集群的负载情况,动态地调整数据的分布,实现负载均衡,提高集群的整体性能。
- https://www.clyso.com/us/data-distribution-in-ceph-understanding-the-crush-algorithm/
- https://www.clyso.com/us/pushing-ceph-rados-into-new-frontiers-lets-make-the-linux-of-storage-a-reality/
- 桶(Buckets):
- 用于表示集群的层级结构,例如数据中心、机房、机架、主机等。桶可以嵌套,形成树状结构。每个桶包含一个或多个子桶或设备。
- https://ceph.com/assets/pdfs/weil-crush-sc06.pdf
与一致性哈希(Consistent Hashing)的区别
| 特性 | CRUSH | 一致性哈希 |
|---|---|---|
| 拓扑感知 | 支持多层级故障域(机架、机房等),确保副本在不同域分布 | 通常只在逻辑环上分布,不关心物理拓扑 |
【4】 ceph
- Accelerating Ceph with RDMA and NVMe-oF
- https://www.openfabrics.org/images/2018workshop/presentations/206_HTang_AcceleratingCephRDMANVMe-oF.pdf
- https://www.youtube.com/watch?v=Mb816kz27mY
- 自旋锁的高昂成本 在高 IOPS 场景下,spinlock 会在短时间内不断循环尝试获取锁而不进行休眠,这种“忙等”方式会占用大量 CPU 周期却无法做有效工作,表现为 CPU 使用率飙高但吞吐并未提升
- AsyncMessenger::AsyncMessenger(
|
|
-
BlueStore: a new, faster storage backend for Ceph
- https://events.static.linuxfound.org/sites/events/files/slides/20170323%20bluestore.pdf
- https://github.com/c-rainstorm/blog/blob/master/os/FileSystem-Ext4.md 这个文章没说journal让陷入误导,注意区分
- https://events.static.linuxfound.org/sites/events/files/slides/20170323%20bluestore.pdf 【后后面多看几次】 一、核心痛点:LSM-Tree架构的固有缺陷 不理解地方:● Many deferred write keys end up in L0
-
Compaction优先级控制困难
- 问题本质:RocksDB基于LSM-Tree(Log-Structured Merge Tree)设计,数据通过逐层合并(Compaction)实现有序化。但不同层级(L0-Lmax)的Compaction优先级无法精细控制,导致高优先级业务数据(如元数据)可能被低优先级数据阻塞。
- 典型案例:元数据(如Bluestore的
onode)写入后频繁触发L0→L1 Compaction,而用户数据Compaction抢占资源,导致元数据访问延迟抖动。
-
元数据总量增长引发性能劣化
- 雪崩效应:随着元数据规模增长(如Ceph集群中数十亿对象),Compaction操作所需内存、CPU、IO资源呈非线性上升。
- 数据佐证:当元数据总量超过Block Cache容量时,Range Query(范围查询)因缓存失效被迫触发磁盘IO,吞吐量下降50%+
- https://www.slideshare.net/Inktank_Ceph/ceph-day-shanghai-ceph-performance-tools?from_search=7# Ceph Day Shanghai - Ceph Performance Tools 【了解几个命令 】
- https://www.youtube.com/playlist?list=PLrBUGiINAakNgeLvjald7NcWps_yDCblr