IO的一生

文章目录
大家好我是小义同学,这是大厂面试拆解——项目实战系列的第6篇文章,
”走暗路、耕瘦田、进窄门、见微光” 告诉我 面试关键就 深入理解自己项目 这个才是最考察基本功的地方。
知识地图:KV存储引擎—IO栈
本文 主要描述 read/write为例子普通文件 IO过程是什么?,
分析这个问题关键思路在哪里?
如果您觉得阅读本文对您有帮助, 请点一下“点赞,转发” 按钮, 您的“点赞,转发” 将是我最大的写作动力!
上篇文章 新一代存储引擎BlueStore,需四步
在创建一个文件时候,Ceph的BlueStore ,
- 将文件的数据直接写块设备
- 将文件的元数据写RocksDB
- BlueStore IO流程 先写数据,还是先写元数据顺序不同 ,提供不同策略。
- Ceph IO 软件栈开销原因 无实现低于 0.5 毫秒的随机读取延迟和低于 1 毫秒的随机写入延迟
普通文件写是否区分元数据 和 数据,这些请求最后怎么写入磁盘 呢?
因为内容太多,分批梳理。
大纲如下:
(1) 预备知识:
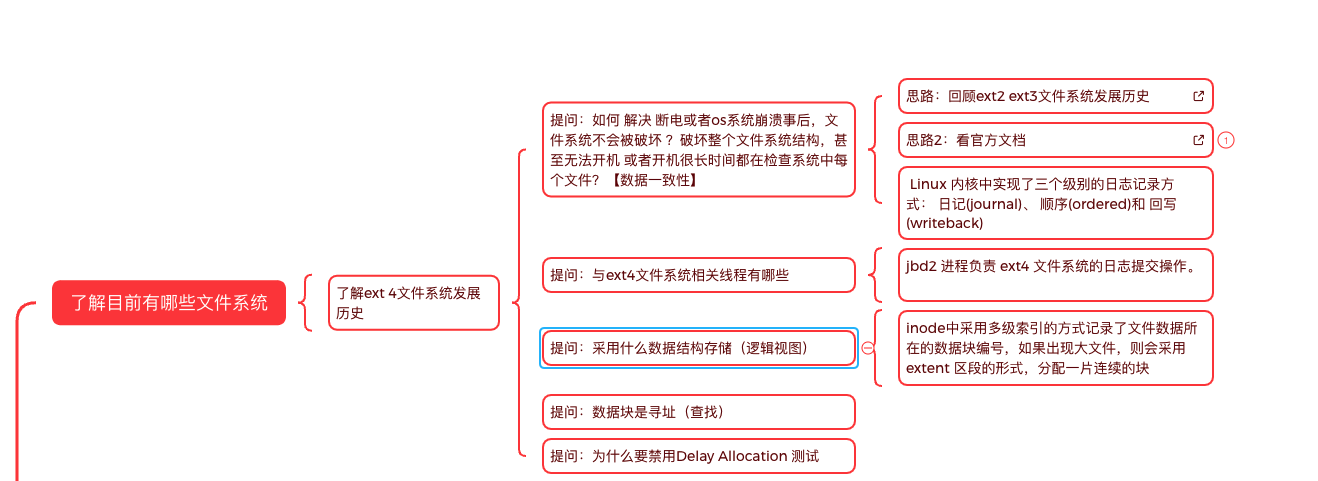
(2) 通过工具 了解IO栈
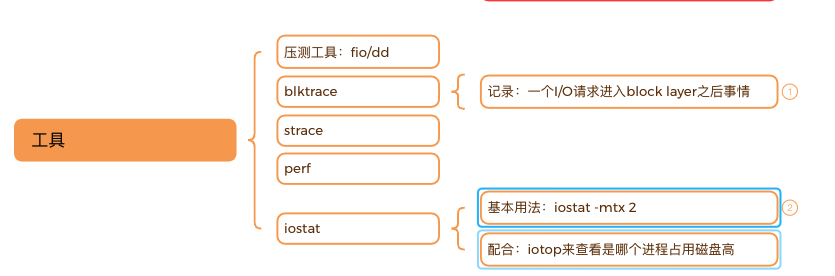 (3) 性能优化
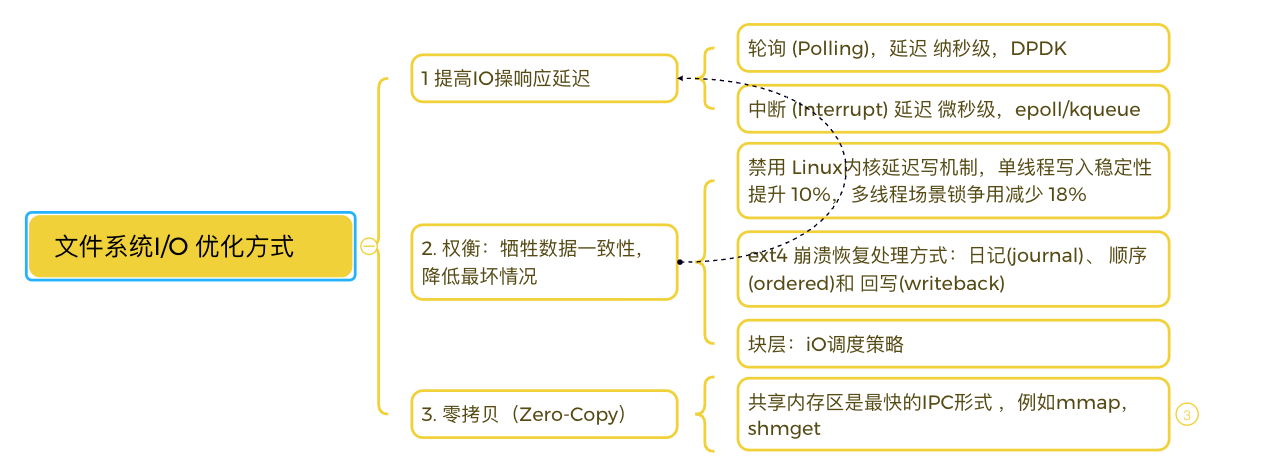
(3) 性能优化
一. 准备环境
1.1 机器配置
✅ 购买2C2G云主机 成本一年不超过100元
✅ 创建1G的大文件充代替块设备,因为没有额外的磁盘
📌 例子:用 Loop 设备模拟一个 ext4 文件系统
|
|
划重点:参数含义说明
文件系统支持的三种日志模式 是什么
- ext4挂载参数: data
| Journal特性 | Journal | Ordered(默认) | Writeback |
|---|---|---|---|
| 数据记录 | 元数据+数据均记录日志 | 仅元数据日志 | 仅元数据日志 |
| 数据写入顺序 | 严格同步 | 数据先于元数据写入 | 无强制顺序 |
| 性能 | 最低 | 中等 | 最高 |
| 崩溃恢复 | 完全一致 | 数据可能部分丢失 | 数据可能大量丢失 |
| 典型场景 | 数据库、关键业务 | 服务器、日常办公 | 高性能计算 |
- If
data=writeback, dirty data blocks are not flushed to the disk before the metadata are written to disk through the journal. - 内核有专门的机制负责将页缓存中的数据异步地写入磁盘,这个过程称为写回(writeback)。
| 延迟分配场景 | 推荐选项 | 原因 |
|---|---|---|
| 高吞吐量顺序写入 | delalloc |
利用批量分配优化连续写入性能(如日志服务器、大数据处理) |
| 低延迟关键业务 | nodelalloc |
避免单次写入延迟波动(如数据库事务、实时系统) |
2.1 块设备IO跟踪
|
|
一、字段含义与事件链分析
- 字段解析(参考示例行:
7,0 1 226 52.043115656 3815652 Q WS 1104864 +8 [jbd2/loop0-8])- 7,0:设备号(主设备号:次设备号),表示
/dev/loop0(虚拟块设备)。 - 1:CPU 核编号(此处为 CPU 1)。
- 226:事件序列号。
- 52.043115656:时间戳(秒级精度)。
- 3815652:进程 PID(jbd2 内核线程)。
- Q/WS:事件类型(Q=请求进入队列,WS=写同步操作)。
- 1104864 +8:起始块号
1104864,操作大小8个块(通常 1 块=4KB,即 32KB 写操作)。 - [jbd2/loop0-8]:进程名,表示
jbd2线程管理/dev/loop0设备的日志功能。
- 7,0:设备号(主设备号:次设备号),表示
- 事件链分析(关键阶段)
- Q→G 阶段(请求生成):
示例:Q WS 1104864 +8→G WS 1104864 +8
表示 I/O 请求进入块层后分配request结构体(耗时约微秒级)。 - I 阶段(插入调度器队列):
多行I WS事件显示请求被插入 I/O 调度器队列(如mq-deadline)。 - D 阶段(下发到驱动):
D WS表示请求被发送至设备驱动层,进入物理设备处理。 - U/FN 阶段:
U N表示队列解绑操作;D FN可能涉及屏障(Barrier)或刷新操作。
- Q→G 阶段(请求生成):
|
|
2.3从块层面 IO优化
二. IO栈全景图
{kind=link}
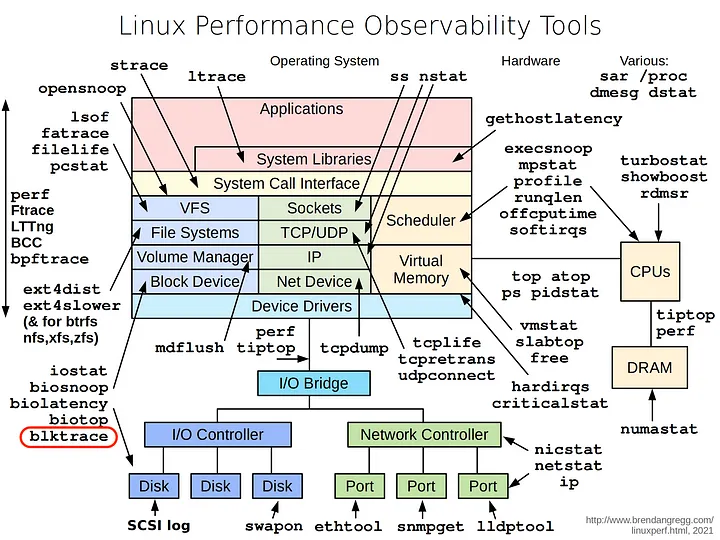
为了掌握IO栈必须了解的基本知识
- 什么是虚拟内存,与磁盘有什么关系? 这个是了解 块设备bio层基础
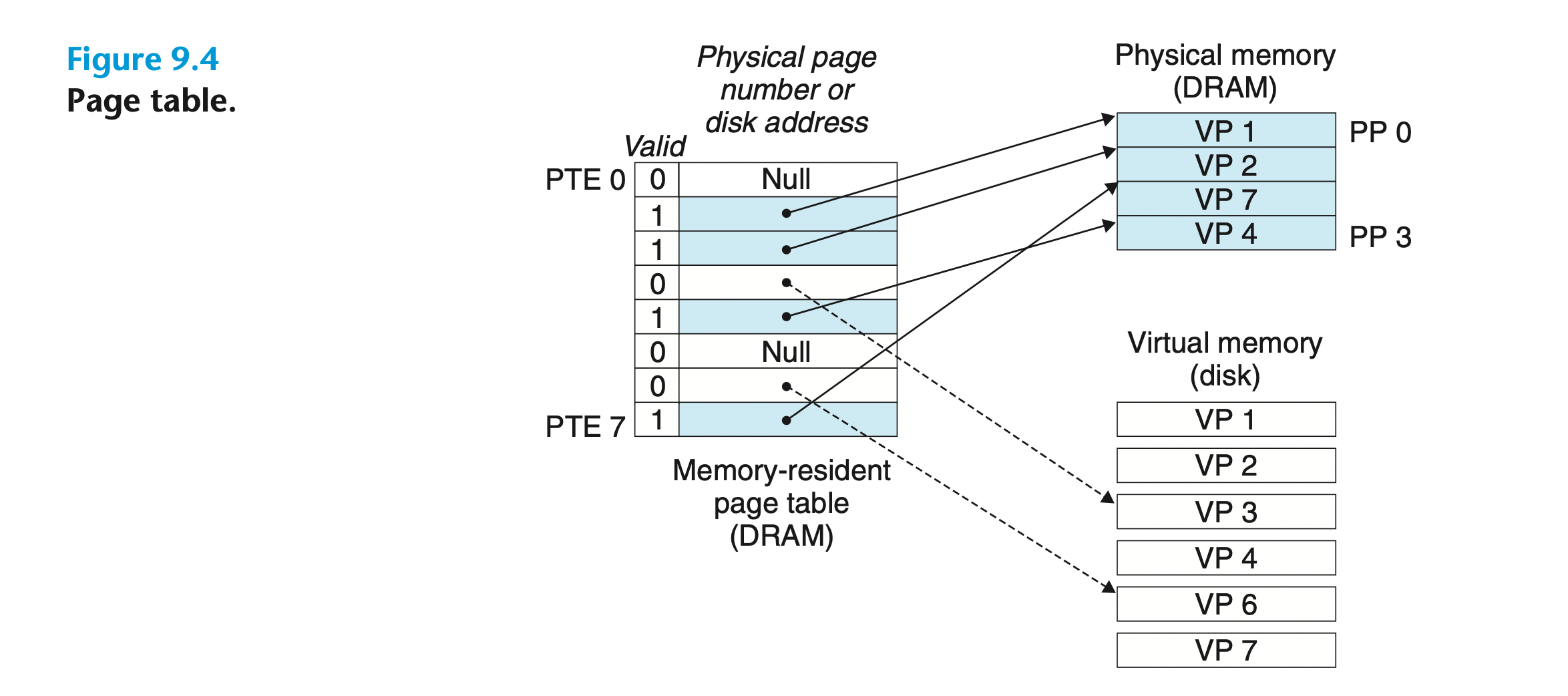 它将主存看成是一个存储在磁盘上的地址空间的 高速缓存,
在主存中只保存活动区域,
并根据需要在磁盘和主存之间来回传送数据,
通过 这种方式,它高效地使用了主存
它将主存看成是一个存储在磁盘上的地址空间的 高速缓存,
在主存中只保存活动区域,
并根据需要在磁盘和主存之间来回传送数据,
通过 这种方式,它高效地使用了主存
在任意时刻,虚拟页面的集合都分为三个不相交的子集: •未分配的:VM 系统还未分配(或者创建)的页。 未分配的块没有任何数据和它们相 关联,因此也就不占用任何磁盘空间。 •缓存的:当前已缓存在物理内存中的已分配页。 •未缓存的:未缓存在物理内存中的已分配页
-
地址空间(address space)是一个非负整数地址的有序集合【地址和数据关系】
-
—个 VM 系统是如何使用主存作为缓存
-
在虚拟内存的习惯说法中,DRAM 缓存不命中称为缺页(page fault)
-
在磁盘和内存之间传送页的活 动叫做交换(swapping)或者页 面调度(paging)。页从磁盘换入(或者页面调入)DRAM 和从 DRAM 换出(或者页面调出)磁盘。
-
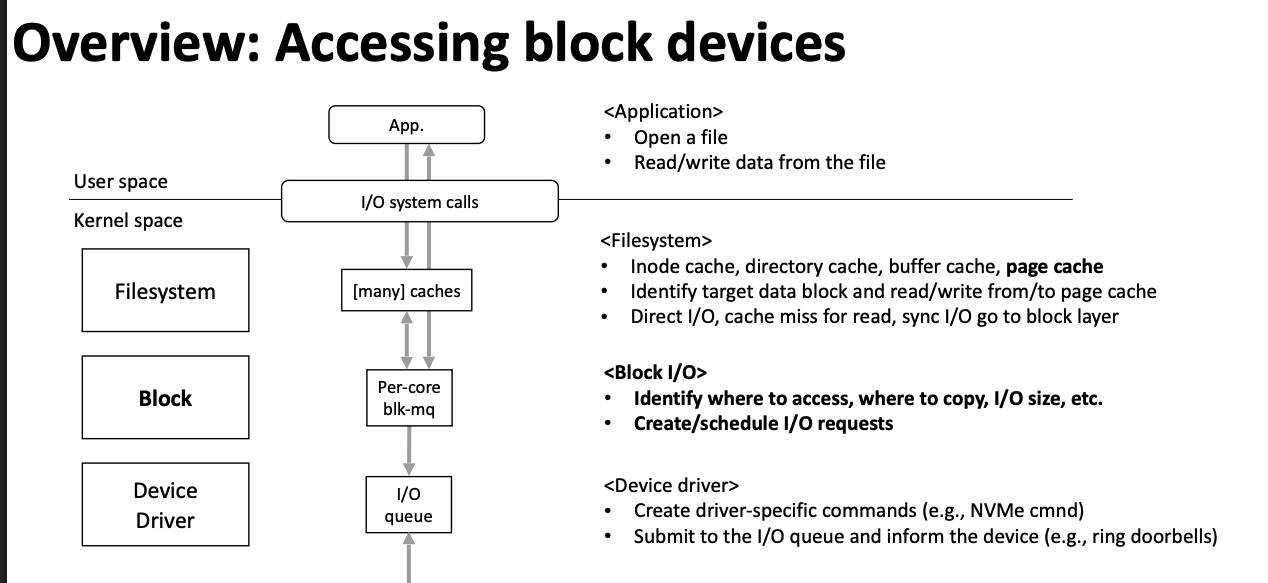
三、IO性能优化采用手段
参考资料
1 Linux问题分析与性能优化
- 地址:https://mp.weixin.qq.com/s/ZDq5_bVGidW1UcPI2TpRb
2 深入理解 Linux的 I/O 系统
3 EXT4
- https://blog.csdn.net/wmzjzwlzs/article/details/143608926
- 一次 write 系统调用竟然消耗了 147ms,很明显地,问题出在 write 系统调用上。
- **猜测因为 journal 触发了脏页落盘,而脏页落盘导致 write 被阻塞,所以解决 journal 问题就可以解决接口超时问题。
- https://oenhan.com/rwsem-realtime-task-hung 问题终于处理清楚了,如此坑爹的问题,陆陆续续的搞了有近月的时间
-
延迟分配(delayed allocation):ext4 文件系统在应用程序调用 write system call 时并不为缓存页面分配对应的物理磁盘块,当文件的缓存页面真正要被刷新至磁盘中时,才会为所有未分配物理磁盘块的页面缓存分配尽量连续的磁盘块。
- https://man7.org/linux/man-pages/man5/ext4.5.html
- nodelalloc Disable delayed allocation. Blocks are allocated when data is copied from user to page cache.
- 日前线上在升级到Ext4文件系统后出现应用写操作延迟开销增大的问题。造成这一问题的根源目前已经查明,是由于Ext4文件系统的一个新特性——Delay Allocation造成的。(后面简称delalloc)
-
delalloc: lat (usec): min=2 , max=193466 , avg= 5.86, stdev=227.91
nodelalloc:
4 打通IO栈:一次编译服务器性能优化实战
- 通过通用块层把页缓存里的数据回刷到磁盘中
- bio层记录了磁盘块与内存页之间的关系
- 在request层把多个物理块连续的bio合并成一个request
-
Linux阅码场原创精华文章汇总
https://www.cnblogs.com/sky-heaven/p/15987836.html
- 文件系统和IO
-
宋宝华: 文件读写(BIO)波澜壮阔的一生
网上关于BIO和块设备读写流程的文章何止千万,但是能够让你彻底读懂读明白的文章实在难找,可以说是越读越糊涂!
我曾经跨过山和大海 也穿过人山人海
我曾经问遍整个世界 从来没得到答案 本文的写作宗旨是:绝不装逼,一定要简单,简单,再简单!
在Linux里面,用于描述硬盘里面要真实操作的位置与page cache的页映射关系的数据结构是bio。相信大家已经见到bio一万次s
把bio转化为request,把request放入进程本地的plug队列;蓄势多个request后,再进行泄洪。
【】学习bio计划
本计划以 8 周为期,分阶段由浅入深,结合文档学习、源码阅读与动手实践。
前期准备(第 0 周)
-
环境搭建:准备一台可刷写内核的测试机或虚拟机,安装常用开发工具(
git、make、gcc、perf、blktrace等)。 -
基础知识回顾:
阶段 1:Bio 与 Request 层(第 1–2 周)
学习目标
- 理解 bio 如何映射到页缓存与磁盘块
- 掌握
struct bio与struct request的关系
实践任务
-
用
printk或 ftrace 打点submit_bio()与generic_make_request()路径。 -
编写一个简单的 RAM-disk 驱动(
blk_queue_make_request)并观察 bio 到 request 层的流转。
阶段 2:I/O 调度器源码研读(第 3–4 周)
学习目标
- 深入阅读
block/elevator.c,理解合并逻辑:-
elv_bio_merge_ok():判断 bio 与 request 是否可合并 -
elv_merge()、elv_attempt_insert_merge()、elv_merged_request()、elv_merge_requests()等函数
-
学习资源
-
GitHub 上的
elevator.c:最新内核源码(GitHub, Android Git Repositories) -
Android Git 源:含注释的
elv_bio_merge_ok实现([Android Git Repositories](https://android.googlesource.com/kernel/common/%2B/baa23246e93f/block/elevator.c?utm_source=chatgpt.com “block/elevator.c - kernel/common - Git at Google1 2
阶段 3:深度跟踪与性能分析(第 5–6 周)
学习目标
- 掌握
blktrace、blkparse与btt的用法 - 分析 I/O 生命周期,识别调度与设备瓶颈
学习资源
-
Medium 实战教程:
blktrace基本用法与示例(Medium) https://bean-li.github.io/blktrace-to-report/ Q – 即将生成IO请求 | G – IO请求生成 | I – IO请求进入IO Scheduler队列 | D – IO请求进入driver | -
Brooker 博文:超越
iostat的存储分析(brooker.co.za) -
Red Hat 性能调优指南:
btt深度分析方法(红帽文档)
实践任务
-
对比不同调度策略(
noop/deadline/cfq)下的跟踪结果:1 2blktrace -d /dev/sda -o - | blkparse -i - btt -i trace.blktrace.*.0 | less -
通过
Q,I,D,C事件时序,判断调度与驱动延迟所在,并输出可视化报告。 -
调整
elevator(cat /sys/block/sda/queue/scheduler),重新跟踪验证。
阶段 4:多队列与自定义驱动(第 7–8 周)
学习目标
-
理解并使用多队列块层(blk-mq)
-
在驱动中自定义
make_request_fn或迁移至 blk-mq 接口
学习资源
-
Thomas Krenn Wiki:blk-mq 性能分析(Thomas-Krenn.AG)
-
社区讨论:如何在 6.x 上扩展
make_request_fn(dattobd/submit_bio)(Reddit)
实践任务
-
在支持多队列的设备上启用 blk-mq(检查
QUEUE_FLAG_MQ_PCI等标志)。 -
将示例驱动改为
blk_mq_alloc_sq_tags()+blk_mq_queue模式,实现 per-CPU 软件队列。 -
使用
perf分析多队列下的中断与上下文切换开销,优化tag_set配置。
如何评估进阶/大师水平
-
代码阅读:能在 ≥ 30 分钟内定位并讲解
elv_bio_merge_ok()、blk_try_merge()等核心点; -
参数调优:熟练使用
nomerges、nr_requests、scheduler等并在真实场景中给出合理配置; -
跟踪分析:用
blktrace/btt输出瓶颈报告,并提出改进方案; -
驱动开发:完成一个支持 blk-mq 的自定义块驱动,确保在高并发 I/O 下稳定且性能优良。
通过以上系统化、阶梯化的学习与实践,你将从“新手”逐步晋级至真正的“块层 I/O 大师”。祝学习顺利!
5. 资料 The Linux Process Journey — “jbd2”
- “JBD” stands for “Journal Block Device
- https://elixir.bootlin.com/linux/v6.2.1/source/fs/jbd2/journal.c#L277
- https://elixir.bootlin.com/linux/v6.2.1/source/fs/jbd2/journal.c#L152
- An Introduction to the Linux Kernel Block I/O Stack
- Device-Mapper(dm)和 Linux 软件 RAID(md)都是基于虚拟块设备(stacked block device)的核心技术
- Linux 内核中的 Device Mapper 机制
- LVM2是Linux 下的逻辑卷管理器,它可以对磁盘进行分区等。但是我们这里用LVM主要是利用用户空间的device mapper 库以及它提供的 dmsetup 工具
- 通过使用 LVM 标记,
lvm子命令能够通过查询与 OSD 关联的设备来存储和重新发现这些设备,以便可以激活这些设备。 这还包括对基于 lvm 的技术 (例如dm-cache) 的支持。 - 虚拟块设备(stacked block device)
- 是通过信号完成异步通知的吗?
| 特性 | 内核中断+回调机制 | 用户态信号(如 SIGIO) |
|---|---|---|
| 触发源 | 硬件中断(IRQ) | 内核向进程发送信号(如 fcntl(F_NOTIFY)) |
| 延迟 | 微秒级(直接由中断处理) | 毫秒级(需上下文切换到用户态) |
| 适用场景 | 块设备驱动、内核 I/O 栈 | 文件描述符就绪事件(如网络套接字) |
| 数据安全 | 无用户态上下文切换,高效安全 | 需处理信号竞争和重入问题 |
similar to high speed networking, with high speed storage targets it can be beneficial to use Polling instead of Waiting for Interrupts to handle request completion 新手和专家 理解
| 方面 | 轮询 (Polling) | 中断 (Interrupt) |
|---|---|---|
| 延迟 | 最低:纳秒级完成检测 | 较高:微秒级中断开销 |
| CPU 利用 | 较高:持续忙等会占用 CPU 周期 | 低:只有 I/O 完成瞬间才消耗少量 CPU |
| 吞吐 | 高并发场景表现优异(减少中断风暴) | 中断风暴可能成为瓶颈 |
| 复杂度 | 需要仔细调度、线程亲和及轮询时长(budget)管理 和 fallback | 简单,操作系统自动管理 |
| blk‑mq 的核心思想 |
-
多提交队列(per‑CPU submit queues):每个 CPU 核有自己的一小队列,提交 I/O 时先放到本核的队列里,减少跨核抢锁。
-
多硬件队列映射:内核将每个 CPU 的提交队列和存储设备的硬件队列一一对应,I/O 完成时也回到同一个 CPU 去处理,保证缓存局部性。
-
减少共享状态:提交和完成都在本核完成,尽量不在 CPU 之间传递数据,降低延迟和锁竞争
与 Linux 块层的关系
-
并不绕开块层:io_uring 的 SQE 填写只是告诉内核要做哪种 I/O,真正的读写还是走 submit_bio → request → 调度 → 驱动 的标准块层路径。
-
异步化+批量化:原来应用是「一次 syscall → 一次 I/O」,io_uring 则可以「一次 enter 提交多条 SQE → 批量下发多条 bio → 批量回收 CQE」,大大减少 syscalls/上下文切换。
-
可选 Direct I/O/Busy‑Poll:对于支持的设备(NVMe),SQE 可以带
RWF_HIPRI或 io_uring iopoll 标志,利用块层的 polling 特性进一步压低延迟。
小结
-
三大数据结构:SQ ring、CQ ring、SQE array;
-
流程:用户填 SQE → 更新 SQ → 内核回调标准 syscall 后端 → submit_bio → 块层调度 → bio_end_io → 写 CQE → 用户读 CQ;
-
关系:io_uring 是用户态到内核态的「高效提交/完成框架」,真正的磁盘 I/O 仍由 Linux 通用块层(bio/request/elevator 或 blk‑mq)完成
6. # linux io过程自顶向下分析
- 进程是内核对CPU的抽象,虚拟内存是对物理内存的抽象,文件是对所有IO对象的抽象(在本文,则主要是指对磁盘的抽象)
- 通用块层的核心–bio
- 本进程内,fd的最直观操作是open、close、mmap、ioctl、poll这