深入理解 新一代存储引擎BlueStore,需四步

文章目录
大家好我是小义同学,这是大厂面试拆解——项目实战系列的第5篇文章,
”走暗路、耕瘦田、进窄门、见微光” 告诉我 面试关键就 深入理解自己项目 这个才是最考察基本功的地方。
知识地图:KV存储引擎—BlueStore
Ceph分布式锁的设计哲学与工程实践 提到 为了支持海量并发, 满足多客户端,主副本等多节点数据达成一致,设计了分布式锁, 分布式锁特点如下:
- 根据不同状态自驱转换,减少用户操作复杂性
- 持久化存储(BlueStore)
本文 主要介绍什么是BlueStore,如何快速理解BlueStore并且进行优化。
一、BlueStore出现的背景、初衷
看版本变化
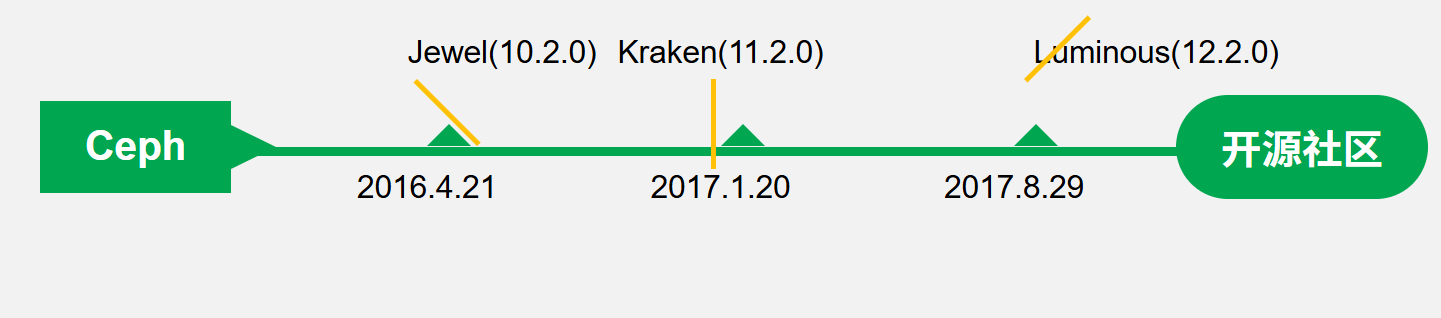
-
2016年4月21 Jewel版本10.2.0,首次引入 BlueStore 存储引擎
-
2017年8月29,Ceph 12.2.0 正式版本发布, 代号 Luminous,BlueStore 成为默认存储引擎
BlueStore 是一个从头开始设计的存储后端, 旨在解决使用本地文件系统后端所面临的挑战。
BlueStore 仅用两年时间就实现了所有这些目标, 并成为 Ceph 的默认存储后端
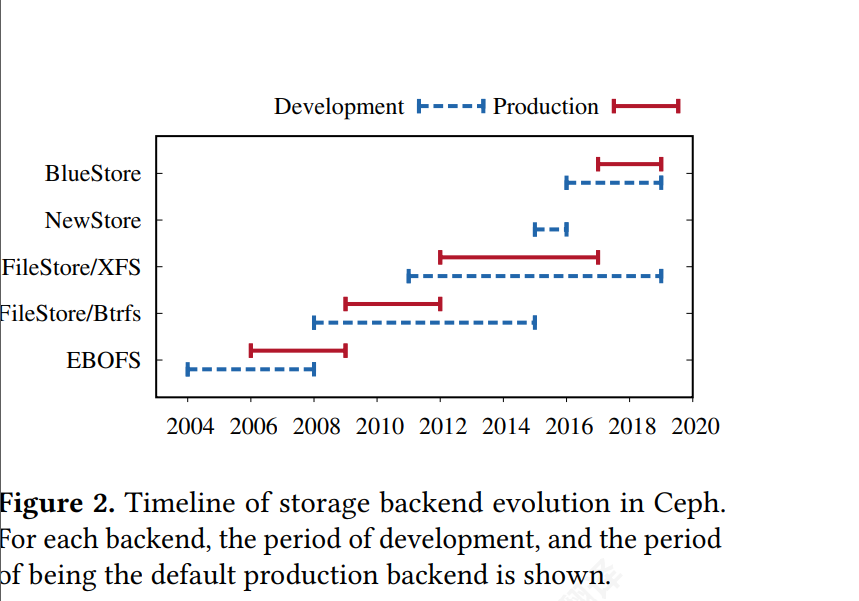
上图看出 ceph不停变换后端从FileStore到BlueStore
BlueStore 的一些主要目标包括:
- 快速元数据操作(第 4.1 节)
- 对象写入无一致性开销(第 4.1 节)
- 基于写时复制的克隆操作 (第 4.2 节)
- 无日志记录的双重写入(第 4.2 节)
- 优化了 HDD 和 SSD 的 I/O 模式(第 4.2 节)
对比如下:
| BlueStore vs FileStore | FileStore (基于文件系统) | BlueStore (直接管理裸设备) | 核心优势说明 |
|---|---|---|---|
| 系统架构 | XFS + LevelDB | RocksDB + 块设备 | 绕过文件系统直接管理磁盘,降低软件栈复杂度 |
| 双写问题 | 存在 | 无(原子写操作) | 消除写放大,提升性能 |
| 批量读取 | 通过 XFS 文件系统读取(百万级别) | RocksDB 元数据 + 直接块设备访问 | 减少 I/O 路径延迟 |
| 对象列举 | 需对 XFS 文件排序 | RocksDB 预排序键值(LSM 树结构**) | 列表操作快 10 倍以上 |
| 批量删除 | 逐个删除 XFS 文件 | 批量删除 RocksDB 键值,批量事务 | 删除速度提升 50-100 倍 |
| 对象读缓存 | 依赖 XFS 缓存机制 | 需用户态实现(如 LRU 缓存) | 灵活性更高,可定制化 |
克服本地文件系统面临什么挑战
挑战 1:高效事务
挑战 2:快速元数据操作
- Ceph 与 FileStore 后端的关键元数据 挑战之一来自在大目录上的缓慢目录枚举( readdir ) 操作,
- 以及返回结果的缺乏排序。
挑战 3:支持新的存储硬件
二、这个技术的优势和劣势分别是什么
- 还有更强的

Crimson 是基于 Seastar C++ 框架实现的 Ceph 下一代 OSD,用以提升多核可扩展性与 I/O 性能。
Crimson 被设计为高性能对象存储守护程序 (OSD),针对 NVMe 等快速存储设备进行了优化。
为了实现这些目标,Crimson 使用包括 SPDK、DPDK 和 C++ Seastar 框架在内的尖端技术从头开始构建。
Crimson 继续沿用 BlueStore 作为底层存储后端
并在未来计划通过原生 Seastore 存储后端摆脱对 BlueStore 的依赖
三、技术的组成部分和关键点。
架构如下:

BlueStore主要4个技术点:
用户态直接写快设备( BlockDevice.)
- BlueStore 直接读写原始块设备(如 SSD/NVMe)
- 在用户态使用linux aio直接操作块设备,去除了本地文件系统的消耗
聪明你可能你会疑问:
- 绕过文件系统,在用户态,怎么完成IO读写?
- RocksDB本身并不支持对裸设备的操?还是使用文件系统?矛盾
- 远离文件系统不能更好支持 - 对全SSD及全NVMe SSD闪存适配?
轻量文件系统
- BlueFS基于裸设备模拟一个简易的用户态文件系统,用于支持RocksDB。
- 支持 SSD/NVMe新硬件
聪明你可能你会疑问 : 为了使用RocksDB,有写一个文件系统?
- POSIX文件系统作为通用的文件系统,其很多功能对于RocksDB来说并不是必须的,为了进一步提升RocksDB的性能,RocksDB的场景量身定制一套本地文件系统,BlueFS也就应运而
- BlueRocksEnv封装文件系统的抽象接
文件系统磁盘空间管理和缓存管理
- 失去默认文件系统支持,要一个磁盘的空间管理系统,Bluestore采用Allocator进行裸设备的空间管理,目前支持StupidAllocator和BitmapAllocator两种方式;
- BlueStore 实现为用户态并通过 DirectIO 直接访问裸盘,因此不实用 kernel 提供的 page cache,为了提升读的性能,需要自行管理Cache。
聪明你可能你会疑问 :
- 为了规避一个问题,出现更多问题,我复习基本Direct I/O 是啥吧?
RocksDB 键值存储元数据:
1. 慢速层(Block):存储对象数据,通常使用 HDD。 2. 高速层(DB):存储 RocksDB 的 SST 文件,通常使用 SSD。 3. 超高速层(WAL):存储 RocksDB 日志,通常使用 NVMe
BlueStore是基于RocksDB和BlockDevice实现的ceph的对象存储
四、技术的底层原理和关键实现
4.1 先测试,在了解
目的:假设你需要对BlueStore优化,必须了解 IO过程是什么
测试 方法1:测试你的磁盘
FIO测试NVMe SSD裸盘的性能,并观察iostat状态
|
|
测试结果:
- 32 io_uring iops: qps:80w 完全发挥NVMe特性
- fio的numjob,iodepth提高NVMe SSD的性能.
测试 方法2 测试您的 Ceph 集群
推荐的基准测试工具
|
|
测试方法1 绕过文件系统,读NVMe_ ssd进行fio的读盘操作 iops 10w-80w
针对测试CEPH集群的性能时,nvme ssd的读写iops总量不超过4w+ why?
方法1 和方法2为何差距这么大
首先的青铜猜想是:
- 在 Ceph 在 HDD 上并不慢:
- Bluestore 的理论单线程随机写入性能是驱动器 IOPS 的 66%(2/3),
- Ceph 的线性读写速度并不慢
- 当你用 SSD 替换 HDD 并使用快速网络时,Ceph 的速度应该会几乎一样快,天真了 ❎
- Ceph 都很难实现低于 0.5 毫秒的随机读取延迟和低于 1 毫秒的随机写入延迟。[
- 单线程下,这意味着随机读取 IOPS 和随机写入 IOPS 分别只有 2000 和 1000,即使能达到这个结果[0.5-1毫秒 一个请求,一个秒多少个?]
- Ceph “软件栈"引入了额外的 I/O 打包、网络传输与协议层延迟,使得 OSD 在压力下无法压满 NVMe,
fio只是本地落盘,时延极小,因此能将 SSD 压。
大师理解的猜想
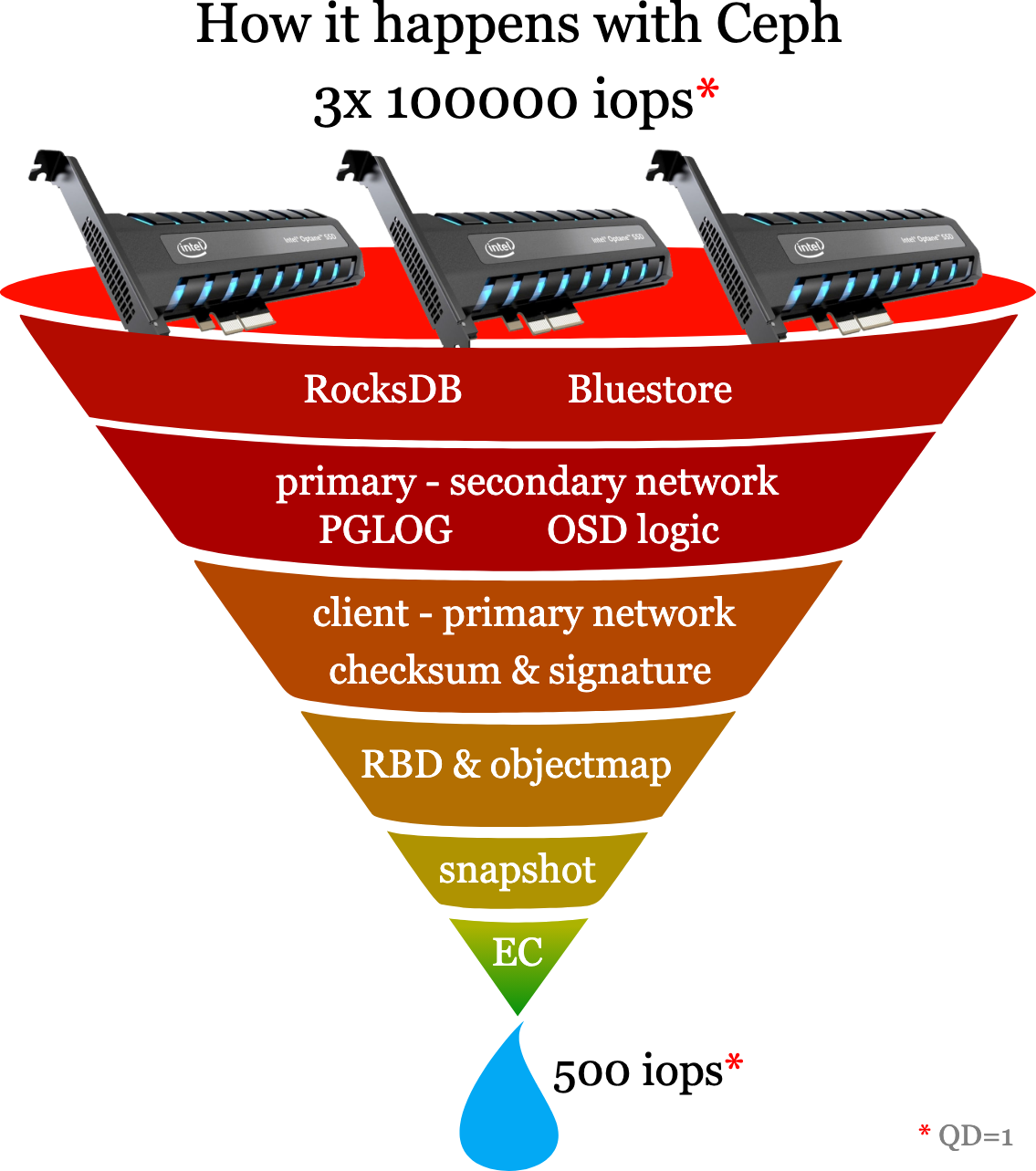
Ceph OSD 多层软件栈开销
- Ceph 默认在 BlueStore 层使用 RocksDB 存储元数据,写请求要先进入 WAL,再写入 MemTable,后台异步 Compaction 会带来 100–300 µs 级别的额外延迟
- RADOS & PG 流程:每次写操作需要通过 RADOS 协议,将数据发送到 Primary OSD 并复制到 Secondary OSD 后才确认,网络 RTT 累加典型在 0.1–0.5 ms 范围,吞吐受限
- TCP/IP vs RDMA:Ceph 原生使用 Kernel TCP/IP,产生 system CPU、iowait 和软中断开销;采用 RDMA(iWARP/RoCE)可减少复制延迟并降低 CPU 占用,使 4K 随机写 IOPS 提升 17%–
- NUMA 与 CPU 亲和
4.2 事务特性 和延迟统计
BlueStore可以理解为一个支持ACID事物型的 本地日志文件系统。- 所有的读写都是以Transaction进行。
- BlueStore通过状态机的方式控制整个IO流程。
- queue_transactions接口 向 BlueStore 提交 事务组完成一系列写请
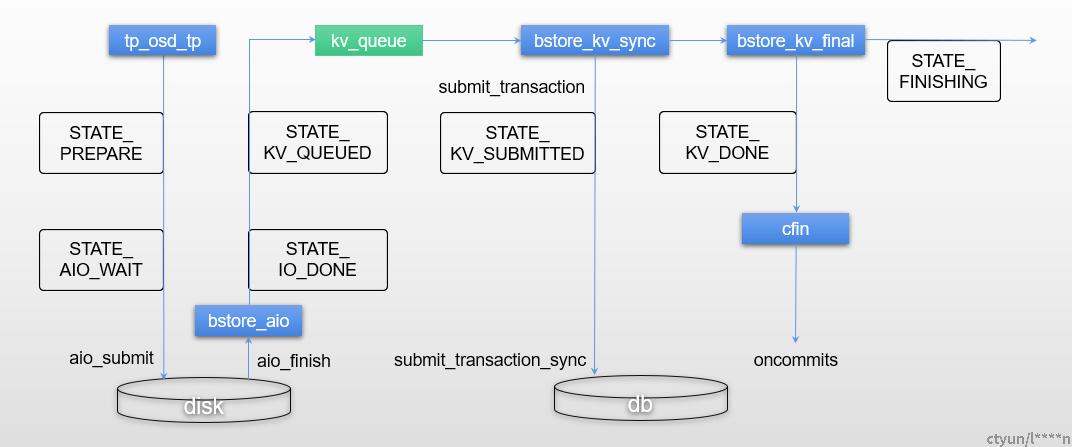
新手视角
基本流程
- 准备(Prepare):在内存中组装本次要执行的写入与元数据操作,事务尚未落盘。
- 编码(Encode):将内存中的操作打包并转化为块设备可识别的 I/O 请求,包括预写日志(WAL)记录或直接写入命令。
- 提交(Submit):通过同步或异步 I/O 接口,将事务操作写入底层存储设备。
- 确认(Commit):等待 I/O 完成后,标记事务已持久化,确保断电或崩溃时数据不丢失。 [
- 应用(Apply):把已提交的变更应用到内存中的索引或缓存,更新对象元数据 write transaction that Ceph will apply atomically 关注重点
- 原子性与持久性:只要事务完成,用户无需关心具体底层细节;
大师视角
|
|
技术点1:线程+队列
-
线程+队列是BlueStore事物状态机的重要组成部分
-
aio_thread线程:属于KernelDevice模块的,主要作用写物理磁盘 。
-
kv_sync_thread:更新元数据k/v,这些必须按顺序操作。BlueStore::_kv_sync_thread
-
kv_finalize_thread:BlueStore::_kv_finalize_thread(),设置状态为STATE_KV_DONE
技术点2:保证IO的顺序性以及并发性
- 因为BlueStore使用异步IO,后提交的IO可能比早提交的IO完成的早,所以更要保证IO的顺序
4.2 BlueStore IO流程

BlueStore IO流程:Simple Write
- 对于simple write场景,先把数据写入新的block,然后把元数据写入k/v数据库中
- 写新block状态转换:STATE_PREPARE -> STATE_AIO_WAIT -> STATE_IO_DONE -> STATE_KV_QUEUED
- 元数据写k/v数据库状态转换:STATE_KV_QUEUED -> STATE_KV_SUBMITTED -> STATE_KV_DONE -> STATE_FINISHING -> STATE_DONE
在处理simple-write时, 需要考虑offset、length是否对齐到block_size(4KB)以进行补零对齐的操作。
BlueStore IO流程:Deferred Write
(https://blog.wjin.org/assets/img/post/ceph_bluestore_deferred_write.png)
{kind=link}
- 对于deferred write场景,延迟IO数据封装在k/v事务中,
- 写入kv数据库后给客户端返回应答,然后在后台执行延迟IO数据的写操作。
写k/v日志:
STATE_PREPARE -> STATE_IO_DONE -> STATE_KV_QUEUED -> STATE_KV_SUBMITTED -> STATE_KV_DONE -> STATE_DEFERRED_QUEUE
写数据:
STATE_DEFERRED_QUEUE -> STATE_DEFERRED_CLEANUP -> STATE_FINISHING -> STATE_DONE
主要步骤:延迟写入的基本流程:
-
当写入请求到来时,BlueStore 首先将数据写入 KV 数据库(RocksDB),并立即返回成功给客户端
-
实际的数据写入被延迟到后台处理,主要涉及以下几个关键数据结构:
-
bluestore_deferred_op_t: 封装单个延迟写操作
-
bluestore_deferred_transaction_t: 包含多个延迟写操作的事务
-
DeferredBatch: 批量处理多个延迟写事务,将多个写操作合并处理
-
OpSequencer: 确保写操作按正确顺序执行
慢点集中在哪里?
- ceph daemon osd.8 perf dump | egrep “wait|lat”
综合来看,RocksDB 同步提交(阶段4) 和 AIO 等待(阶段2) 是占比最高的两部分, 共计可超过 80% 的
64K随机写入(QD=16场景)
- 总延迟:2.268ms(其中Store层占比达93%)
- Store层细分:
- state_aio_wait_lat:0.797ms(较QD=1增长14.7倍)
- state_kv_queued_lat:0.544ms(元数据队列等待,增长107倍)
- state_kv_commiting_lat:0.689ms(RocksDB提交耗时,增长9.5倍)
- 瓶颈根源:
- 单线程设计:
kv_sync_thread需串行处理元数据提交,导致高QD下队列堆积(如kv_queued_lat从0.005ms升至0.544ms - 异步I/O竞争:Linux AIO的
io_submit在高并发时需频繁上下文切换,占用CPU核心资源
- 单线程设计:
- Store层细分:
小结(三步走)
- FIO压测 :即便在读客户端压力足够的情况下 软 件层不能给到下层足够的I/O压力,不能利用起NVME强大的硬件并发性能。工具:fio,iostat,vmstat,iotop
- 读请求各阶段耗时分析 降低延迟。工具:ceph daemon osd.10 perf dump/perf /gdbpmp,慢的原因在哪里能说清楚吗?性能优化:上千提升上万,过10万是不可能的?为什么
- 如何证明:Ceph “软件栈"引入了额外的 I/O 打包、网络传输与协议层延迟,使得 OSD 在压力下无法压满 NVMe。
如果您觉得阅读本文对您有帮助, 请点一下“点赞,转发” 按钮, 您的“点赞,转发” 将是我最大的写作动力!
链接我
刚刚好,是最难得的美好
我就在这里 ,我刚刚好。

我正在做的事情是
1. 目标:拿百万年薪
- 想进入一线大厂,但在C++学习和应用上存在瓶颈,渴望跨越最后一道坎。
2. 现状:缺乏实战,渴望提升动手能力
-
公司的项目不会重构,没有重新设计的机会,导致难以深入理解需求。
-
想通过阅读优秀的源码,提高代码能力,从"不会写"到"敢写”,提升C++编程自信。
-
需要掌握高效学习和实践的方法,弥补缺乏实战经验的短板。
3. 价值:成为优秀完成任务,成为团队、公司都认可的核心骨干。
优秀地完成任务= 高效能 + 高质量 + 可持续 + 可度量
错误示范:
- 不少同学工作很忙,天天加班,做了很多公司的事情。 但是 不是本团队事情,不是本部门事情,领导不认可,绩效不高
- 做低优先级的任务,绩效不高,随时被优化
参考
【1】 File Systems Unfit as Distributed Storage Backends: Lessons from 10 Years of Ceph Evolution
- 文件系统作为分布式存储后端:从 Ceph 十年进化中汲 取的教训
- https://dl.acm.org/doi/pdf/10.1145/3341301.3359656
【2】Ceph OSD Crimson: Next-generation Ceph OSD for Multi-core Scalabilit
- https://ceph.io/en/news/blog/2023/crimson-multi-core-scalability/
- ceph-osd-cpu-scaling
- https://ceph.io/en/news/crimson/
- https://seastar.io/
[5] io_uring: So Fast. It’s Scary. - Paul Moore, Microsoft
- IO uring gets Zero Copy network operations
- 随着存储和网络设备性能越来越高,用户发现kernel那厚重的存储栈和网络栈效率越发低下,分分推出kernel bypass技术,但这类技术有一个通病,就是接口设计不统一,无法兼容,所以业界迫切期待内核推出一套成熟高效通用的异步编程框架,来缓解厚重模块带来的影响
- io_uring只通过提供3个系统调用接口,就统一了网络和存储异步IO编程框架,使得上层开发人员无需过多关注其接口的可扩展性
- 深入理解io_uring(一)设计初衷
- 深入理解io_uring(二)设计原理
- strace -c dd if=/dev/zero of=test bs=1M count=1000
- 深入理解io_uring(七)零拷贝发送网络请求
- 深入理解io_uring(三)一个完整请求
[6] Understanding BlueStore, Ceph’s New Storage Backend - Tim Serong, SUSE
- https://yourcmc.ru/wiki/index.php?mobileaction=toggle_view_desktop&title=Ceph_performance#Why_is_it_so_slow
- 2018-May-29 :: Ceph Code Walkthrough: BlueStore part 1 [视频 ]
- Ceph BlueStore的状态机
- Block I/O Layer Tracing using blktrace
- 你可以通过 iostat、blktrace 工具分析瓶颈是在应用层还是内核层、硬件层。其中 blktrace 是 blkio 层的磁盘 I/O 分析利器,它可记录 IO 进入通用块层、IO 请求生成插入请求队列、IO 请求分发到设备驱动、设备驱动处理完成这一系列操作的时间,帮助你发现磁盘 I/O 瓶颈发生的阶段
- BlueStore IO 流程代码梳理 [看完 ]
- BlueStore源码分析之事物状态机
- https://blog.wjin.org/categories.html
- Ceph性能瓶颈分析与优化一部曲:rados(mix)
【7】 https://ceph.io/en/news/blog/2024/ceph-a-journey-to-1tibps
- 希望将其基于 HDD 的 Ceph 集群迁移到 10PB 的 NVMe
- 客户的网络配置设计精良,68 node/memory:192g/amd/network:100GB2/ disk:nvme10
- FIO 4MB 和 4KB IO 测试,每次持续 300 秒 [自己测试上层业务功能1个月,根本没有工具和全部,自己感觉,不断测试浪费大量时间,老板不认,这是自己测试的。期望 写完代码完成,根本不后续]
- Iperf Iperf 网络测试显示每个节点的速率接近 200Gb/s
- 一个 Ceph 结果也远低于我们的期望,始研究单节点,甚至单 OSD 配置
- 最初的单 OSD 测试在处理大量读写操作时表现非常出色
- 一旦运行 8-OSD 测试,我们就会发现性能下降
- 只要不引入多 OSD 测试,性能就能保持较高水平
- Why would running an 8 OSD test cause the kernel to start blocking in io_submit during future single OSD tests
- 一个多星期以来,我们尝试了各种方法,包括 BIOS 设置、NVMe 多路径、NVMe 底层调试、更改内核/Ubuntu 版本,以及检查我们能想到的每一个内核、操作系统和 Ceph 设置。但这些方法都无法完全解决问题。
- 我们开始让硬件供应商参与进来。最终发现这完全没有必要。我们只做了一个小修复和两个大修复,事情就回到了正轨
- 用户已通过禁用C-State获得10-20%性能提升,但未达预期目标。C-state是intel CPU处于空闲时的一种状态,其核心逻辑是:当CPU无任务处理时,自动进入不同深度的休眠状态(C1、C2、C3等),从而在性能和功耗之间实现动态平衡,,禁用C-State后性能仍不,- 使用更高主频的CPU(如AMD EPYC 7xx3系列)以提升单线程处理能力。
- Ceph的延迟敏感性:Ceph的分布式存储操作(如元数据处理、网络协议栈、RocksDB写入)依赖高频率的CPU响应。若频繁触发C-State切换,累积的延迟会导致I/O处理效率下降,尤其在小文件随机读写(4K IOPS)场景下更为明显。
- raw_spin_lock_irqsave,禁用IOMMU通过消除自旋锁争用释放了大块I/O的潜力
- 在更新 IOMMU 映射时,内核中有大量时间用于争用自旋锁。他在内核中禁用了 IOMMU,在 8 节点测试中立即看到了性能的大幅提升。我们多次重复这些测试,并多次看到 4MB 读写性能的显著提升。客户值得一提。然而,4KB 随机写入仍然存在问题
- 如果未使用正确的 cmake 标志和编译器优化进行编译,Ceph 可能会非常慢。
- Ceph can be very slow when not properly compiled with TCMalloc support.
- TCMalloc通过线程本地缓存和细粒度内存管理大幅降低多线程环境下的锁竞争,尤其在Ceph的高并发I/O场景中
- 启用TCMalloc后,4KB随机写入IOPS从30K提升至42K(+40%),尾延迟降低80%
- 禁用调试符号:Debug模式(-O0)会导致性能下降50%以上,仅限开发环境使用
-
- disables c-states,获得10-20%性能提升
-
- disabled IOMMU
- Ceph can be very slow when not compiled with the right cmake flags and compiler optimizations
- 32 nodes 31 client nodes
- 630 OSD