成为ob贡献者(6):如何阅读Paxos代码

文章目录
为了整理思路,文章采用模拟2人对话方式,文中比喻可能错误的,请注意区分。
本文主要内容
- 通过对学习数据库下 定义聚焦学习内容
如果关心代码,直接去看代码,如果关心SQL,直接看SQL,先满足第一需求。
- 通过OB定义一体化不是什么,是什么 聚焦学习方向
一体化 在添加一个字: 像一体化,例如 多个节点像一个节点 来保证高并发和可扩展
- 采取对照组实验方式学习, 请说出他们相同点 和不同点确定关键部分。
对照组: 从一个最简单例子开始,这个自己很清楚,大家都知道 从一个 工程实践组: 一个是踩过无数坑,经过无数考验,自己不知道,别人知道 。
一、对学习下个定义:简化,简化,简化
风和日丽下午,小王与老王在咖啡馆相遇了,
小王:我想学习数据库,但是笔记本配置低,最新的4.x至少8G内存,不方便安装了,即装 了也无法长时间运行?更别说编译了,该如何开始呢
老王:咱们对学习下个定义
- 如果业务开发人员,关心的是怎么写sql,可用使用OB Cloud 云数据库 30 天免费试用,先别考虑30是否太短。用完30天在说,不需要关心部署问题。
- 如果源码爱好者,关心的是设计方案,代码流程 ,代码规范,如果提交代码,可用gitpod简单编译,不用担心没有经过充分测试 github提供大部分自动化测试用例。
- 如果万能DBA 考虑更多。。。
资源有限情况下,做出取舍,这样更加集中精力,咱们主要学习ob 并发情况下如何保证数据的一致性
- 对ob下个定义:自研的一体化架构,兼顾分布式架构的扩展性与集中式架构的性能优势,
小王疑问:
一体化 不是把全部功能放在一块,这有点违反直觉,软件为了代码可读性和可维护性采用, “高内聚、松耦合” 设计,代码目录划分是不是回混乱?
在存储领域, 海量非结构化存储的 有一体机说,软硬件一体化的设计。这这个意思吗?
老王: OceanBase 为什么走向一体化 看一下这个文章 https://open.oceanbase.com/blog/5022262784
下面是我的另外一个理解
对比熟悉产品他们没有一体化这个概念,他们是怎么解决这个高可用这样问题的?
_Ceph:统一存储解决方案,三部分组 Ceph 对象存储设备服务进程,简称 OSD。一个 OSD 守护进程与集群中的一个物理磁盘绑定 Ceph 元数据服务器服务进程,简称 MDS Ceph 监视器服务进程,简称 MON。负责监控集群的监控状态,至少有3个 Ceph monitor中实现了paxos算法。 Ceph monitor 通过保存一份集群状态映射来维护整个集群的健康状态。它分别为每个组件维护映射信息,包括OSD map、MONmap、PG map和CRUSH map。所有群集节点都向MON节点汇报状态信息,并分享它们状态中的任何变化
Redis Sentinel 模式
Sentinel(哨兵)是一个独立运行的进程,三个节点(box)启动三个 Sentinel组成进程一个分布式系统。但是只有一个leader,leader来管理Redis 主从切换。
一体化 概念不理解 就是抽象:是多个进程,抽象一个进程,每个进程里 可能不同功能线程组成。
- election worker:选举线程。
因此看代码时候 直接main 函数从头到尾不合适了,这是大型工程,不是简单的例子,
越是大型工程,必然内部必然清晰模划分,每个独立部分都是单独封装起来。
Paxos 协议与选举协议为什么分开独立实现的?
OceanBase 数据库的 Paxos 实现和选举协议一起构成了一致性协议(日志服务)的实现。 两者有一定的相关性,但在实现上又尽量做到减少耦合。
项目:必然符合,“高内聚、松耦合” 设计思想,这样保证代码的可读性和可维护性。
不一定是通过进程区分,还是可以 通过线程
题外话: 用多个进程,多个线程能实现一个数据库,协程呢,为什么大家都不用协程实现一个数据库。协程的特点不是更加高效,自主切换??
这里重点解释几个概念
-
Redis 主从模式 节点为单位存储数据,一个节点故障了,另外一个节点上数据代替。
redis集群有槽点这划分,槽点放到节点上,
单节点 性能有限?如果提高性能,直接添加机器固然可用,理论依据是什么
看看硬件:
-
网卡绑定,多个网卡像一个网卡一样使用。
网卡绑定是将多块物理网卡虚拟成一块逻辑网卡的过程。 多块物理网卡被视为一个整体,共同完成网络数据的传输任务。同时,当其中一块网卡出现故障时,其他网卡可以继续提供网络服务,增强了网络的稳定性。 ![[Pasted image 20241013170845.png]]
-
硬RAID和软RAID 多个磁盘像一个磁盘一样
RAID 全称叫廉价冗余磁盘阵列(Redundant Array of Inexpensive Disks) 其设计初衷是为了将多个容量较小、相对廉价的磁盘进行有机组合, 在实际应用领域中使用最多的 RAID 等级是 RAID0 、 RAID1 、 RAID4 、 RAID5 、RAID10 、JBOD
软raid是通过操作系统和软件来实现raid功能,而硬raid则是使用专门的raid控制器来实现raid功能。硬Raid 通过raid 卡进行数据交换,占用系统I/O 极小,数据的交换与运算都是通过RAID 卡来完成的
-
CEPH PG全称是placement groups,ceph的逻辑存储单元
简单是一个存储节点上 10个磁盘,一个磁盘对应一个osd服务。 通过服务把三个节点上30个磁盘组成像一个磁盘一样,
PG全称是placement groups,它是ceph的逻辑存储单元,可以把PG想象成存储了多个对象的逻辑容器,这个容器映射到多个具体的OSD
如果没有PG,就难以管理和跟踪数以亿计的对象,它们分布在数百个OSD上。对ceph来说,管理PG比直接管理每个对象要简单得多。每个PG需要消耗一定的系统资源包括CPU、内存等
![[Pasted image 20241013145523.png]]
-
说到这里CEPH PG 与ob 有点类似
-
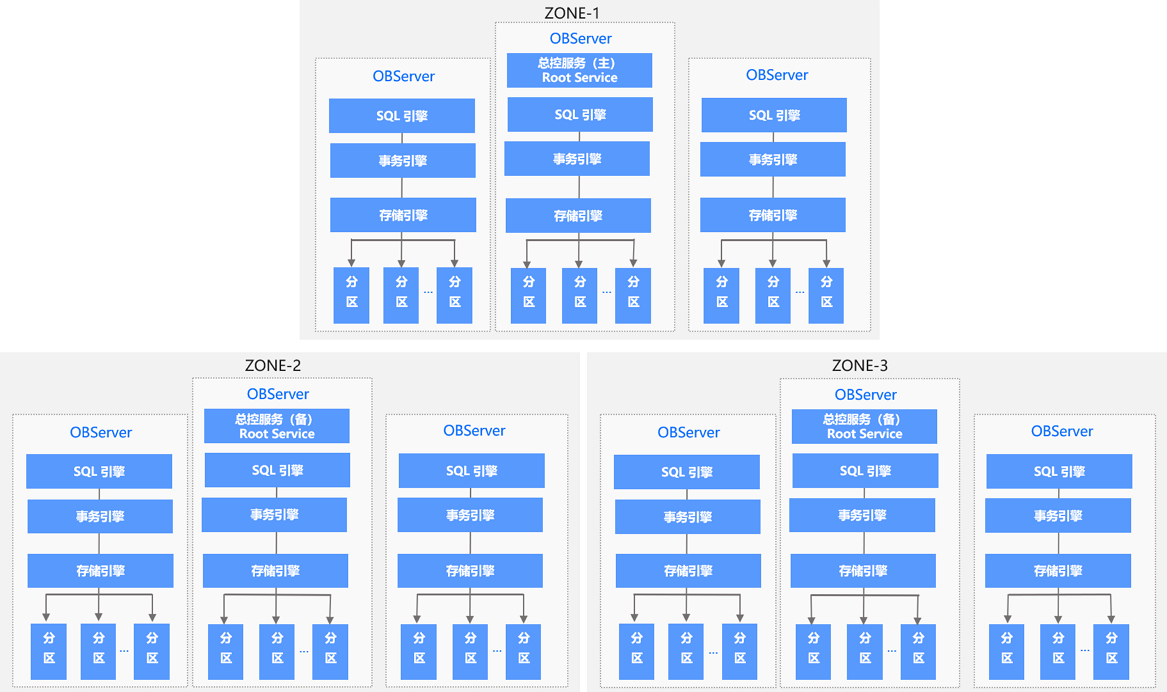
分区与副本 由于 OceanBase 数据库的数据副本是以分区为单位的,所以同一个分区的数据会分布在多个 Zone 上。每个分区的主副本所在服务器被称为 Leader,所在的 Zone 被称为 Primary Zone
-
可用区/区(Zone)
Zone 是 Availability Zone 的简称。一个 OceanBase 集群,由若干个可用区(Zone)组成。通常由一个机房内的若干服务器组成一个 Zone。为了数据安全性和高可用性,一般会把数据的多个副本分布在不同的 Zone 上,可以实现单个 Zone 故障不影响数据库服务。
每个 Zone 会提供两种服务:总控服务(RootService)和分区服务(PartitionService)
其中,每个 Zone 有一台 OBServer 会同时运行总控服务(RootService),用于执行集群管理、服务器管理、自动负载均衡等操作
|
|
旁白, 一体化,总控服务RootService,ObServer等,如同金箍棒 一样 变小 变小再变小 用其他产品来比喻 别看这么粗暴介绍OceanBase整体结构, 至少目的了,方法有了,就展开看行动吧,至少1个月内完内✅ 2024-10-01–2024-11-01
二、如何学习:对照,对照,在对照
小王:我准备好阅读代码工具 和和找到相关代码模块,如下 ,该如何下手呢?
阅读代码工具选择 (只阅读不编译代码)
- In Windows, we recommend
Souce Insightcan be used - in Mac or Linux, we recommend that
VSCode + ccls
代码路径:
其中 Palf 不是随便命名的,全名 “Paxos-backed Append-only Log File System” 这个是对日志服务一个抽象,
这里你发现:这里只有领导选举代码,并没有日志复制代码(和期望一样全部在一个模块不一样,别慌,你发现的绝对没问题),根据模块划分 原则,哪怕不知道完整代码,不影响阅读领导选举模块。
小疑问 :PALF 为什么领导者选举与共识协议分离开来?———开始 原文1:PALF decouples leader election from the consensus protocol to manipulate the location of the database leader without sacrificing availabilit
PALF 将领导者选举与共识协议分离开来—选择距离最近的。
小王猜测可能从用户角度考虑,为了降低业务延迟,在业务部署时候,尽可能部署到Primary Zone。这样用户需就可以灵活指定领导者优先级 ,不仅仅根据谁日志编号大就是选择谁。 回顾:配置2 领导者选举时候保证zone1 > zone2 > zong3 ,zone1故障恢复后,流量切换zone1
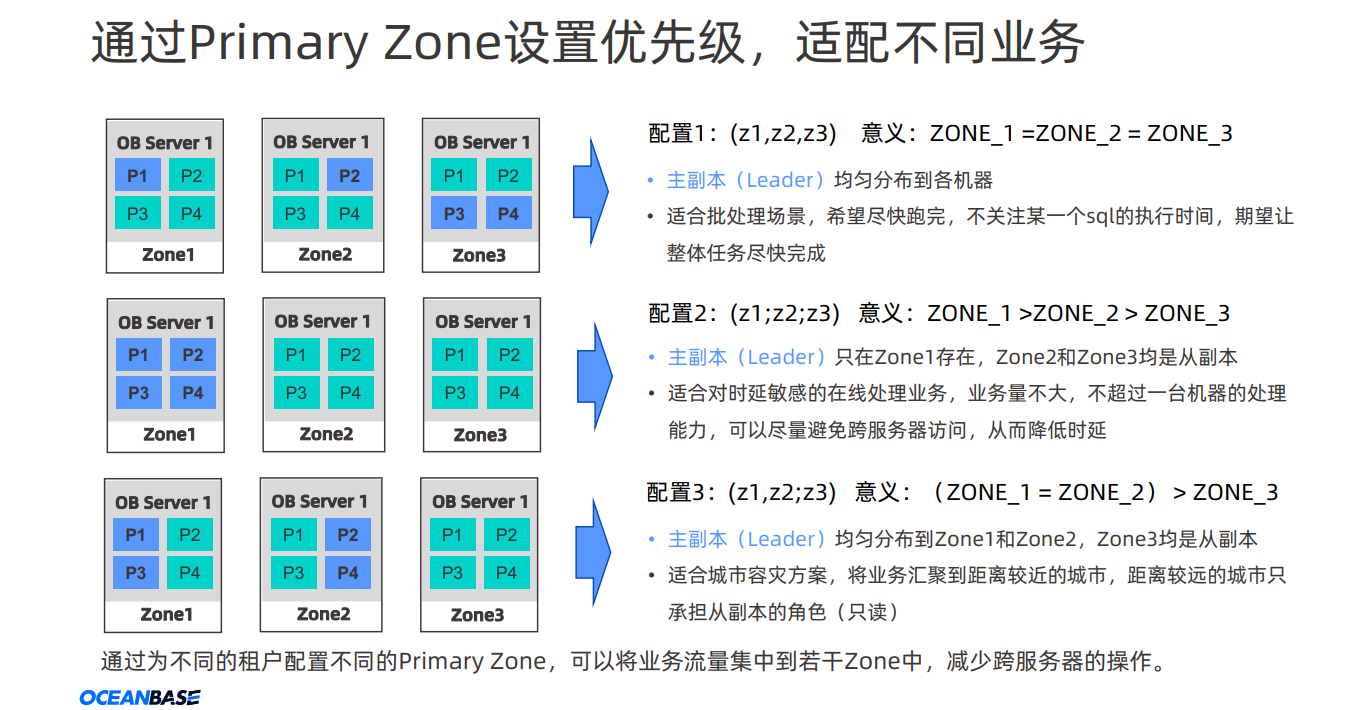
Primary Zone 描述了 Leader 副本的偏好位置,而 Leader 副本承载了业务的强一致读写流量,即 Primary Zone 决定了 OceanBase 数据库的流量分布。假设某张表 t1 的 primary_zone="Zone1",则 RootService 会尽量将 t1 表的 Leader 调度到 Zone1 上来。
在补充概念
小疑问 :PALF 为什么领导者选举与共识协议分离开来?————结束 原文2:For example, in cross-region deployment, users tend to make the upper application and the database leader in the same region to reduce latency, If the previous leader recovers from failure and its priority is still higher than current leader’s, leadership can be automatically transferred back to the recovered replica.
下面是 小王概念简单理解:
- 持久化: 联想到在 Redis persistence AOF,Append Only File,是指Redis将每一次的写操作(命令)都以日志的形式记录到一个AOF文件中,
- 持久化内容: 日志 联想到 可以理解文件系统上一个文件,比较熟悉的是java业务中使用 log4j打印不同级别日志。
- 持久化内容进行复制:在2024 年 8 月 26 日至 8 月 30 日 VLDB2024 会议上,OceanBase 的 2 篇论文《Replicated Write-Ahead Logging for Distributed Databases》和《Native Distributed Databases: Problems, Challenges and Opportunities》入选,获得了国际学术界的高度认可。
-
https://www.vldb.org/pvldb/vol17/p3745-xu.pdfPALF: Replicated Write-Ahead Logging for Distributed Databases
从上面内容看一会提到kv,Redis,java,VLDB2024 太发散了不知道到底说什么, 一句话解释 增量变更内容日志形式持久存储下来,然后复制不同副本。 复制方式很多种,从主从复制 升级到Paxos方式
请看下面完整定义
Palf 是数据库的一个基础组件,它需要完成两大核心功能:
-
对于事务系统,具备以下特性:
-
满足事务系统 Write-Ahead Logging 的功能需求,实现事务的原子性和持久性。
-
支持返回特定语义的时间戳,满足读写事务、备机弱读等生成事务版本号的需求。
-
实现事务的高性能,同时做到多核下的可扩展。
-
-
对于分布式,具备以下特性:
-
基于 Paxos 协议,保证数据在多数派副本持久化成功;同时通过成员变更提供容灾能力,实现高可用和高可靠。
-
提供异步复制的能力。
-
提供完善的诊断监控能力,实现可诊断、可运维。
-
老王:自然对照组方式,一个最 简单demo方式实现 这个你清楚了解的,一个是踩过无数坑,经过无数考验实现 这个是你不清楚的,请说出他们相同点 和不同点。
- 版本1.0: 采用Go语言 完全按照lamport的论文paxos-simple.pdf中的描述流程,没有任何优化实现
- 版本4.0 :采用c++实现的工业级实现的 multi-paxos
- Raft vs Paxos 方式
三、技术的组成部分和关键点
Master选举与Paxos的关系
- 为什么需要Leader
Multi-Paxos允许并行提交,最坏情况要退化到Base Paxos
- 如活锁问题:
多个 proposor,轮流用更高的 proposal ID 运行 phase1,导致两者都没法进入 phase2,无法确定谁可以写入,形成活锁
- 用户无法自定义选举的优先级。
所以我们并不希望长时间处于这种情况,Leader的作用是希望大部分时间都只有一个节点在提交。
任一时刻,仅有一个节点成为Leader或者没有任何节点成为Leader
- 如何选举唯一的Master
Base Paxos 是通过2次RPC达成一个值,
Master选举也是达成一致,是不是可以用Base Paxos ?
或者
是不是可以用选择一个编号最大的一个,ID最大一个?
都可以。既然都可以没有统一的说明,这就是百花齐放,
各自使用各自方式实现,让人感觉不好理解
PALF 是 OceanBase 数据库在 V4.0 版本中将日志同步服务进行打包后的一个框架简称,
选举功能是该框架提供的子功能
但是:
PALF: Replicated Write-Ahead Logging for Distributed Databases
提到:重点介绍复制日志系统的设计,
因此,我们将选举算法的实现细节留给另一篇论文也没有具体给出说明
This paper focuses the design of the replicated logging system, therefore, we leave implementation details of the election algorithm for another paper
在万字解析:从 OceanBase 源码剖析 paxos 选举原理 ob作者提到

题外话:
Paxos算法强调达成一致,但是没有告诉如何选举,
或者认为选举就是很随意一个事情。这就是框架的灵活性,就c++一样,
Master选举算法可以采用其他通用性的算法,它可以与任何强一致性算法搭配来完成,而无需要求一定是Paxos是算法。
选举算法和Paxos日志同步可以分开来实现。
题外话:
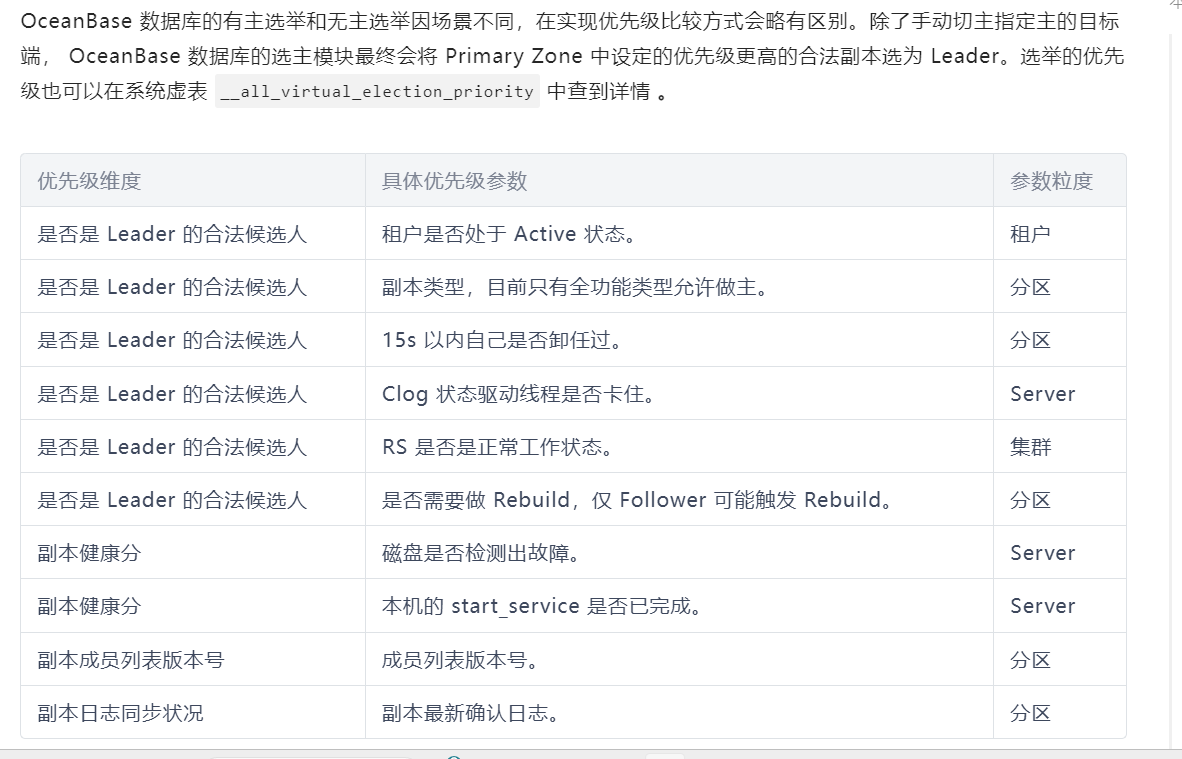
在选举中哪个副本会被选为主?OceanBase 数据库的选举模如何保证选举到的 Leader 副本是更好的选择? 这个是帮助理解,不需要记住,他们做不少优化
如何查看代码呢?
- 租约(Lease):租约是一把时间锁,是一段时间内的排他性保证,是目前已知的在分布式系统中保证唯一
Leader又不会丧失活性的唯一手段,选举实际上是使用 basic-paxos 在副本间就租约达成共识。
The candidate is elected by a lease-based election algorithm
- election proposer:
proposer是paxos中的提案发起者,proposer会提议开始一次选举,并尝试竞选成为Leader。 - election acceptor:
acceptor是paxos中的提案审议者,acceptor会根据基本原则判断是否要接受一项提案(在选举中提案就是租约),并确保任意时刻集群中只有一个Leader。
OceanBase 数据库知识导图
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000324072
参考
选举层面无主问题排查指南
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000001230231
OceanBase 数据库选举
https://www.oceanbase.com/knowledge-base/oceanbase-database-20000000075
类似的机制可以参考微信的 phxpaxos 的文章:https://zhuanlan.zhihu.com/p/21540239。
https://zhuanlan.zhihu.com/p/21466932?refer=lynncui
https://zhuanlan.zhihu.com/p/21466932?refer=lynncui
- [1]万字解析:从 OceanBase 源码剖析 paxos 选举原理
https://zhuanlan.zhihu.com/p/630468476
- [2] 开源数据库OceanBase代码导读
https://www.zhihu.com/people/yang-zhi-feng-79/posts?page=2
http://oserror.com/uncategorized/yuque/OceanBase%E4%BB%A3%E7%A0%81%E5%AF%BC%E8%A7%88/
PALF: Replicated Write-Ahead Logging for Distributed Databases
沟通步骤
- 准备一个图片,一段话,可以放在三页doc,三页ppt 描述你方案一、这个技术出现的背景、初衷和要达到什么样的目标或是要解决什么样的问题二、这个技术的优势和劣势分别是什么三、这个技术适用的场景。任何技术都有其适用的场景,离开了这个场景四、技术的组成部分和关键点。五、技术的底层原理和关键实现六、已有的实现和它之间的对比
- 反馈:鸡蛋里挑骨头,经过客户,领导 ,公司认证,做事情价值和意义。听到否定愤怒反对 说明自己对这个事情还不了解。
- 最后融合别人建议,然后完善你项目
参考
-
[1] 1. OceanBase Development Guide https://oceanbase.github.io/oceanbase/ide-settings/
-
[2] 2. https://lamport.azurewebsites.net/pubs/paxos-simple.pdf
-
[1] 3.Redis persistence https://redis.io/docs/latest/operate/oss_and_stack/management/persistence/
-
5. # 万字解析:从 OceanBase 源码剖析 paxos 选举原理
-
7. 开源数据库OceanBase代码导读
-
8. 整体架构 https://www.oceanbase.com/docs/oceanbase-database-cn
-
9.https://redis.io/docs/latest/operate/oss_and_stack/management/sentinel/ done
-
ceph-mon之Paxos算法
- https://bean-li.github.io/ceph-paxos/
- https://bean-li.github.io/ceph-paxos-2/
- https://segmentfault.com/a/1190000010417185
- pg组
- https://www.xiaobo.li/notes/archives/1004
- #杨传辉:从一体化架构,到一体化产品,为关键业务负载打造一体化数据库
小贴士
一、这个技术出现的背景、初衷和要达到什么样的目标或是要解决什么样的问题
二、这个技术的优势和劣势分别是什么
三、这个技术适用的场景。任何技术都有其适用的场景
四、技术的组成部分和关键点。
五、技术的底层原理和关键实现
六、已有的实现和它之间的对比