oceanbase源码阅读(1)程序启动

文章目录
【注意】最后更新于 June 22, 2021,文中内容可能已过时,请谨慎使用。
慢慢来,多看、多问、多总结,肯定是可以攻克的。
沟通步骤
-
准备好一个ppt,在写代码之前演示最终目标 和架构设计 就是如何去实现的 【不要说公司部门环境不对 着就是最终结果,不要试着看看,一定是可以完全上线的项目,非demo和一个知识点。自己认为真的 不是闹着玩的。。】
一、这个技术出现的背景、初衷和要达到什么样的目标或是要解决什么样的问题
二、这个技术的优势和劣势分别是什么
三、这个技术适用的场景。任何技术都有其适用的场景,离开了这个场景
四、技术的组成部分和关键点。
五、技术的底层原理和关键实现
六、已有的实现和它之间的对比
-
经过领导,专家 进行鸡蛋里挑骨头。【自己做好了别人路了胡扯,不会对别人产生任何影响,做事和做人一样,无论熟悉人,还是老师,领导,不相关人 反对 他们反馈信号,接受质疑,经过九九八十一难考验,并且你还在坚持认为对的。】
-
最后融合别人建议,然后完善你项目。【不听老人言,吃亏在眼前,不敢接受别人批评,说明自己完全没有把握,才去否定 愤怒方式】
预备知识:
源码编译
OceanBase Deploy (简称 OBD)是 OceanBase 开源软件的安装部署工具÷÷
步骤1 源码编译OceanBase:
|
|
步骤2 将编译产物加入OBD本地仓库
|
|
说明: 步骤1和步骤2 合并一个命令 make DESTDIR=./ install && obd mirror create -n oceanbase-ce -V 3.1.0 -p ./usr/local
步骤3:centos 环境设置和部署
-
sysctl.conf添加内容
echo “fs.aio-max-nr=1048576” » /etc/sysctl.conf
配置生效 sysctl -p
-
open files参数修改
vim /etc/security/limits.conf #添加内容
1 2 3 4* soft core unlimited * hard core unlimited * soft nofile 655350 * hard nofile 655350
退出会话,重新登录,再次运行即可。
[root@oceanbase ~]#ulimit -a
-
Q: 如何指定使用特定版本的组件
-
A: 在部署配置文件中使用 package_hash 或 tag 声明。
如果您给自己编译的 OceanBase-CE 设置了t ag,您可以使用 tag 来指定。如:
oceanbase-ce:
tag: my-oceanbase
-
启动
1 2 3 4 5 6 7 8 9 10 11 12 13 14参考:https://gitee.com/oceanbase/obdeploy hostname oceanbase obd cluster deploy obtest -c mini-local-example.yaml obd cluster edit-config obtest obd cluster redeploy obtest obd cluster start obtest obd cluster stop obtest # 参看obd管理的集群列表 - obd cluster list
|
|
- obd cluster start test
|
|
- obd cluster display test
|
|
查看 lo 集群状态
obd cluster display obtest
obd cluster destroy obtest
cd /app/data 10.115.37.60
alias cdob=“obclient -u root -h 127.0.0.1 -P2881”
|
|
- select * from __all_server \G;
|
|
-
资源占用情况
select a.zone,concat(a.svr_ip,':',a.svr_port) observer, cpu_total, cpu_assigned, (cpu_total-cpu_assigned) cpu_free, mem_total/1024/1024/1024 mem_total_gb, mem_assigned/1024/1024/1024 mem_assign_gb, (mem_total-mem_assigned)/1024/1024/1024 mem_free_gb from __all_virtual_server_stat a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port) order by a.zone, a.svr_ip;
select t1.name resource_pool_name, t2.name unit_config_name, t2.max_cpu, t2.min_cpu, t2.max_memory/1024/1024/1024 max_mem_gb, t2.min_memory/1024/1024/1024 min_mem_gb, t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.svr_port) observer,t4.tenant_id, t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.resource_pool_id = t3.resource_pool_id)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.resource_pool_id, t2.unit_config_id, t3.unit_id ;
|
|
程序入口
-
main.cpp
-
observer/ob_service.h
-
observer/ob_service.cpp
|
|
看2号线程
|
|
|
|
Thread 495 日志模块
|
|
|
|
暂停 没看懂
问题:通过观察线程 无法找到sql执行过程 ?
解决办法:通过看日志方式解决,最后聚焦到stmt
|
|
|
|
任务1:Lex-and-Yacc【sql解析基础知识必须掌握】!!!
动手练习:yum -y install flex bison
- https://berthub.eu/lex-yacc/cvs/output/lexyacc.html
- https://github.com/konieshadow/lex-yacc-examples
- https://gitee.com/wan3574489/Lex-and-Yacc
- http://dinosaur.compilertools.net/
理论:
- 通过lex分析定义的词;(词是构建语法的最基本单元,语法是建立在词的基础之上)
- 通过yacc分析语法,构建语法树。
- 通过对语法树的分析,生成或计算出我们想要的结果。
任务2:pingcap/parser【很直观,必须掌握】
任务3:MySQL解析——MySQL内核源码解读【后面需要,必须掌握】
https://www.oceanbase.com/docs/oceanbase-database/oceanbase-database/V3.1.2/system-architecture
存储引擎
OceanBase 数据库的存储引擎采用了基于 LSM-Tree 的架构,把基线数据和增量数据分别保存在磁盘(SSTable)和内存(MemTable)中,具备读写分离的特点。对数据的修改都是增量数据,只写内存。所以 DML 是完全的内存操作,性能非常高。读的时候,数据可能会在内存里有更新过的版本,在持久化存储里有基线版本,需要把两个版本进行合并,获得一个最新版本。
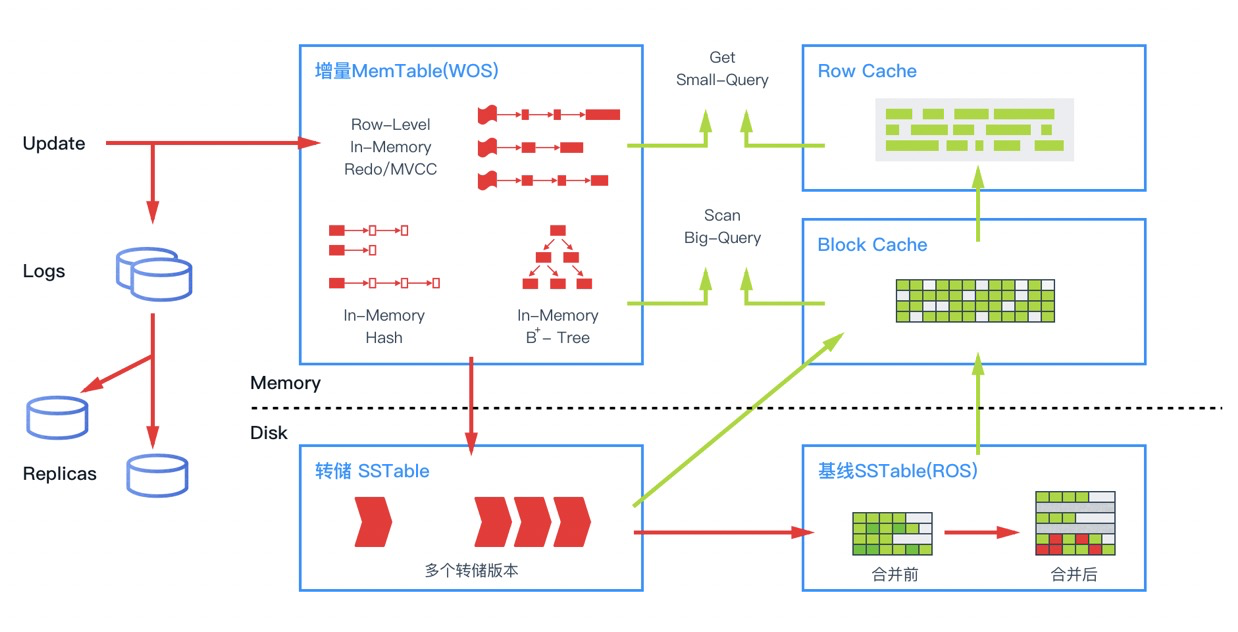
如上图所示,在内存中针对不同的数据访问行为,OceanBase 数据库设计了多种缓存结构。除了常见的数据块缓存之外,也会对行进行缓存,行缓存会极大加速对单行的查询性能。为了避免对不存在行的空查,OceanBase 数据库对行缓存构建了布隆过滤器,并对布隆过滤器进行缓存。OLTP 业务大部分操作为小查询,通过小查询优化,OceanBase 数据库避免了传统数据库解析整个数据块的开销,达到了接近内存数据库的性能。当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘。同时每天晚上的空闲时刻,系统也会启动每日合并。另外,由于基线是只读数据,而且内部采用连续存储的方式,OceanBase 数据库可以根据不同特点的数据采用不同的压缩算法,既能做到高压缩比,又不影响查询性能,大大降低了成本。
SQL 引擎
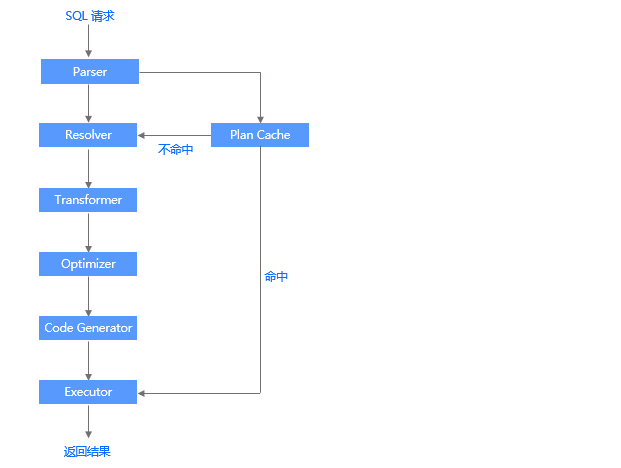
OceanBase 数据库的 SQL 引擎是整个数据库的数据计算中枢,和传统数据库类似,整个引擎分为解析器、优化器、执行器三部分。当 SQL 引擎接受到了 SQL 请求后,经过语法解析、语义分析、查询重写、查询优化等一系列过程后,再由执行器来负责执行。所不同的是,在分布式数据库里,查询优化器会依据数据的分布信息生成分布式的执行计划。如果查询涉及的数据在多台服务器,需要走分布式计划,这是分布式数据库 SQL 引擎的一个重要特点,也是十分考验查询优化器能力的场景。OceanBase 数据库查询优化器做了很多优化,诸如算子下推、智能连接、分区裁剪等。如果 SQL 语句涉及的数据量很大,OceanBase 数据库的查询执行引擎也做了并行处理、任务拆分、动态分区、流水调度、任务裁剪、子任务结果合并、并发限制等优化技术。
下图描述了一条 SQL 语句的执行过程,并列出了 SQL 引擎中各个模块之间的关系。
-
Parser(词法/语法解析模块)
Parser 是整个 SQL 执行引擎的词法或语法解析器,在收到用户发送的 SQL 请求串后,Parser 会将字符串分成一个个的单词,并根据预先设定好的语法规则解析整个请求,将 SQL 请求字符串转换成带有语法结构信息的内存数据结构,称为语法树(Syntax Tree)。
为了加速 SQL 请求的处理速度,OceanBase 数据库对 SQL 请求采用了特有的快速参数化,以加速查找执行计划的速度。
-
Resolver(语义解析模块)
当生成语法树之后,Resolver 会进一步将该语法树转换为带有数据库语义信息的内部数据结构。在这一过程中,Resolver 将根据数据库元信息将 SQL 请求中的 token 翻译成对应的对象(例如库、表、列、索引等),生成语句树。
-
Transfomer(逻辑改写模块)
在查询优化中,经常利用等价改写的方式,将用户 SQL 转换为与之等价的另一条 SQL,以便于优化器生成最佳的执行计划,这一过程称为查询改写。Transformer 在 Resolver 之后,分析用户 SQL 的语义,并根据内部的规则或代价模型,将用户 SQL改写为与之等价的其他形式,并将其提供给后续的优化器做进一步的优化。Transformer 的工作方式是在原 Statement Tree 上做等价变换,变换的结果仍然是一棵语句树。
-
Optimizer(优化器)
优化器是整个 SQL 优化的核心,其作用是为 SQL 请求生成最佳的执行计划。在优化过程中,优化器需要综合考虑 SQL 请求的语义、对象数据特征、对象物理分布等多方面因素,解决访问路径选择、联接顺序选择、联接算法选择、分布式计划生成等多个核心问题,最终选择一个对应该 SQL 的最佳执行计划。SQL 的执行计划是一棵由多个操作符构成的执行树。
-
Code Generator(代码生成器)
优化器负责生成最佳的执行计划,但其输出的结果并不能立即执行,还需要通过代码生成器将其转换为可执行的代码,这个过程由 Code Generator 负责。
-
Executor(执行器)
当 SQL 的执行计划生成后,Executor 会启动该 SQL 的执行过程。对于不同类型的执行计划,Executor 的逻辑有很大的不同:对于本地执行计划,Executor 会简单的从执行计划的顶端的算子开始调用,由算子自身的逻辑完成整个执行的过程,并返回执行结果;对于远程或分布式计划,Executor 需要根据预选的划分,将执行树分成多个可以调度的线程,并通过 RPC 将其发送给相关的节点执行。
-
Plan Cache(执行计划缓存模块)
执行计划的生成是一个比较复杂的过程,耗时比较长,尤其是在 OLTP 场景中,这个耗时往往不可忽略。为了加速 SQL 请求的处理过程,SQL 执行引擎会将该 SQL 第一次生成的执行计划缓存在内存中,后续的执行可以反复执行这个计划,避免了重复查询优化的过程。
todo- 02
基础
揭秘 OceanBase SQL 执行计划
OPERATOR 类型 常用操作算子
- TABLE GET : 指主键访问
- TABLE SCAN:表示扫描。
output
- sort_keys 表示排序列和顺序
range_cond
- T_OP_LIKE: 这是 模糊匹配的操作符
参考别人分享
-
OceanBase SQL 执行计划解读(二)──── 表连接和子查询
-
OceanBase SQL 执行计划解读(三)── 标量子查询、分析函数
-
揭秘 OceanBase SQL 执行计划(一)
日志
|
|
第一部分:源码阅读
参考别人阅读记录
-
淘宝数据库OceanBase SQL编译器部分 源码阅读–解析SQL语法树 https://blog.csdn.net/qq910894904/article/details/28658421
-
淘宝数据库OceanBase SQL编译器部分 源码阅读–生成逻辑计划 https://www.cnblogs.com/chenxueyou/p/3776203.html
-
淘宝数据库OceanBase SQL编译器部分 源码阅读–生成物理查询计划 https://blog.csdn.net/qq910894904/article/details/30215665?spm=1001.2014.3001.5501
-
淘宝数据库OceanBase SQL编译器部分 源码阅读–Schema模式
https://blog.csdn.net/qq910894904/article/details/32322909?spm=1001.2014.3001.5501
参考:
TiDB 源码阅读系列文章(六)Select 语句概览 https://pingcap.com/blog-cn/tidb-source-code-reading-6/
TiDB 源码阅读系列文章(五)TiDB SQL Parser 的实现
TiDB 源码阅读系列文章(二十三)Prepare/Execute 请求处理 https://pingcap.com/blog-cn/tidb-source-code-reading-23/
TiDB 源码阅读系列文章(四)Insert 语句概览 https://pingcap.com/blog-cn/tidb-source-code-reading-4/
开源数据库OceanBase代码导读
sql 执行过程
split_multiple_stmt
首先通过ObParser的一个快速解析入口split_multiple_stmt把每条语句拆分出来,对每条语句process_single_stmt
|
|
开源数据库OceanBase代码导读(1)
https://zhuanlan.zhihu.com/p/379437192
开源数据库OceanBase代码导读(11)
(8)分布式事务
https://zhuanlan.zhihu.com/p/385944563
(10)事务日志的提交和回放
https://www.zhihu.com/people/yang-zhi-feng-79/posts
https://zhuanlan.zhihu.com/p/389202627
(14)索引构建
https://www.zhihu.com/people/yang-zhi-feng-79/posts
https://zhuanlan.zhihu.com/p/400934816
https://zhuanlan.zhihu.com/p/400934816
create index i1 on t1(c2) –>parser和resolver–>ObRootService::create_index
void TestDDL::do_load_sql –>
nt ObIndexBuilder::create_index
int ObRootService::create_index
第一部分:代码阅读
- OceanBase原理与实现分析
https://yang.observer/2020/04/19/oceanbase/
https://docs.huihoo.com/big-data/hic2011/taobao-oceanbase.pdf
- OceanBase架构
OceanBase 源码解读(三):分区的一生
https://mp.weixin.qq.com/s/JFizlbnZMawk19exN-yOqA
table_scan
第二部分:pr
|
|
第三部分:讨论
第一题:The LSM-tree storage engine into OceanBase #66
小白提问1:
https://github.com/oceanbase/oceanbase/discussions/66
https://hub.fastgit.org/oceanbase/oceanbase/discussions/66
LSM-tree:
平时写代码都是写缓存,写磁盘。着就是常规的os的文件系统。
这个和 LSM-tree有区别?
青铜理解
一个文件(inode) 数据内部分为很多block,这些block 分散不同地方,然后通用block快 也合并多个请求,最后batch 操作!
- mysql inno的delete比insert慢得多[ 删除操作啥东东???]
为了理解这个问题 我阅读了 资料:
- the Log structured Merge-Tree(LSM-Tree
https://kernelmaker.github.io/lsm-tree
-
LSM Tree 架构
https://www.oceanbase.com/docs/oceanbase-database/oceanbase-database/V3.1.2/lsm-tree-architecture
-
为了理解这个问题 我阅读了redo 日志管理控制 https://open.oceanbase.com/docs/community/oceanbase-database/V3.1.0/redo-log-management-and-control
-
为了理解这个问题 我阅读了 内存表 MemTable https://www.bookstack.cn/read/oceanbase-2.2.30-zh/30085c9e2371ac1c.md
https://www.oceanbase.com/community/articles/200130
https://www.oceanbase.com/docs/oceanbase-database/oceanbase-database/V3.1.2/memory-table
tak
- OS 有自己的内存管理策略。 page cache 利用率到了一定程度也会刷脏。另外也有定时(秒级)刷脏策略。 OS 的策略是通用的策略,它并不熟悉 具体是什么样的程序在写文件。是代码还是办公应用,或者数据库。
数据库是特殊的应用,特殊在数据的价值、重要性,普通的文件不满足数据库的需求。所以数据库软件会有自己的内存管理策略和读写模型。 LSM-Tree 就是一种读写模型,传统的关系数据库读写模型是 BTree 那种。 oB的 LSM-Tree 创新之处还在于 level 不会很高,并且增量会尽可能的在内存,延迟刷脏。OB的刷脏有 转储(类比oracle的checkpoint,ob叫 minor freeze)以及默认每天一次的 合并(merge,major freeze)
-
操作系统的文件缓存 只能说有一定的相似度, 但算法是有很大区别
-
https://www.zhihu.com/question/20545708 02-17
请问我这样理解对吗?红黑树相比AVL主要优点是旋转次数少了,在并发情形下,AVL和红黑树的旋转操作都需要加锁,而红黑树的重染色过程不需加锁,所以在并发情形下红黑树的旋转操作少导致其并发性能比AVL高?
https://github.com/torvalds/linux/blob/master/Documentation/core-api/rbtree.rst
obd cluster display obtest
obdeploy 文档
第二题:一次性说清楚 Paxos、Raft 等算法的区别
使用 OBD 扩容
https://open.oceanbase.com/docs/videoCenter/5900009
OB社区版(单服务器3副本)
obd cluster list
|
|
问:数据文件大小不是 datafile_size控制的吗?datafile_disk_percentage 这个2个参数优先使用那个呀?
答: