从青铜到王者系列:深入浅出理解 DeepSeek 3FS(1)
 次阅读
次阅读
文章目录
【注意】最后更新于 August 11, 2023,文中内容可能已过时,请谨慎使用。
如果不好老外交流,只背诵单词 怎么背也不得要领。 如果没有真实项目场景,虽然大量项目代码怎么看网络知识,c++知识也不理解背后含义
这里从零实现一个3FS文件系统开始。 探讨 讲背后计算网络,内存,文件,cpu串联起来。 请警惕 幻觉,也可能胡说八道。
什么是3FS? Fire-Flyer File System (3FS):一套基于现代 SSD 与 RDMA 网络全部带宽的并行文件系统
我可以看 deepseek-ai/3FS吗? 它就在哪里,为什么不能。
-
我问的是没有GPU设备情况 还可以看吗? 依然可以,既然无法安装就看背后设计原理。
-
3FS出现的背景是什么? 3FS 专为应对 AI 训练和推理工作负载的挑战而设计。 分布式文件系统成为 AI 训练中一项关键的存储技术
-
AI训练过程是什么?
TensorFlow MNIST 手写数字识别整理训练过程
|
|
重点说明:
-
批量读取加载
利用tf.data.Dataset接口,对预处理后的数据执行shuffle()(随机打乱数据)和batch(batch_size)操作。 这样每个训练步骤都会以一个固定大小的批次(batch)输入模型,不仅能加速训练,还能稳定梯度更新。 -
Checkpoint(检查点)
使用 TensorFlow 提供的tf.train.Checkpoint对象保存模型权重和优化器状态。 通过在训练过程中定期调用checkpoint.save()来存储当前状态,可以在训练中断后,通过checkpoint.restore()恢复模型, 从而实现断点续训并保证模型训练的连续性与稳定性。
- 对存储服务要求是什么?
- 小文件批量随机读取
- 大文件读写操作。高带宽
AI 训练对存储系统的需求大致如下:
-
Shuffle 阶段(元数据操作)
- 主要涉及 文件系统元数据请求,包括
readdir和getattr:readdir获取目录下子文件的 dentry(目录项)元数据信息。(大目录)getattr获取文件的 inode 信息,以便后续读写操作。
- 这个阶段主要考验 存储系统的元数据处理能力。
- 主要涉及 文件系统元数据请求,包括
-
数据读取阶段(读性能要求)
- 训练数据读取主要考验 存储系统的读能力。
- 训练数据是 大文件 时,存储系统的 读带宽 是关键。
- 训练数据是 大量小文件 时,存储系统的 随机读 IOPS 变得重要。
-
Checkpoint(大模型训练的存储挑战)
- Checkpoint 文件通常是大文件,
- 单个节点可达 几十到上百 GB,并行训练时每个 GPU 可能有独立的 Checkpoint。
- 写入 Checkpoint 时,存储系统需要 高写带宽。
- 恢复 Checkpoint 时,存储系统需要 高读带宽。
AI 训练存储需求总结
- Shuffle 阶段:考验 元数据处理能力。
- 数据读取:考验 读带宽(大文件) 或 随机读 IOPS(小文件)。
- Checkpoint:考验 写带宽(写入时) 和 读带宽(恢复时)。
- 小文件的随机写能力不是最重要的,而 元数据处理能力、读写带宽、随机读 IOPS(针对小文件) 才是关键。
- 现有的硬件理论上可行吗?
| 集群规模 | 每个存储节点配置 | 网络配置 | 说明 | 理论总带宽 | 实际测得吞吐量 |
|---|---|---|---|---|---|
| 180 个存储节点 | 每节点配备 16 个 14TiB NVMe SSD,总存储容量约 2240 TiB | 每节点配备 2×200Gbps InfiniBand 网卡 | 专门用于存储模型训练所需样本数据,提供极强的读取吞吐能力 | 整体9 TB/s | 整体6.6 TiB/s |
| 600台计算节点 | 本地可选NVMe SSD(用于数据缓存加速) | 高速网络接口(如25-100GbE或RDMA) | 存储服务节点分离,主要负责模型训练/推理,依赖高速网络访问数据 | 单个峰值可达 40+ GiB/s | |
| IB交换机 | 每个端口的传输速率为200Gb/s | 40个端口 | 所有端口的总聚合数据吞吐量高达16Tb/s | ||
| 可以先做个理论计算: |
- 每个节点的 InfiniBand 网卡总带宽为 2×200Gbps = 400Gbps。
- 将 400Gbps 转换成字节速率:
400Gbps ÷ 8 = 50GB/s(理论值) - 180 个节点的总理论带宽为:
180 × 50GB/s = 9000GB/s,即 9TB/s
1字节(byte)由8比特(bit)
-
Gbps:通常用于描述网络带宽、数据传输速率等,尤其是在网络设备、通信协议和宽带服务中。例如,光纤网络的带宽、Wi-Fi的传输速率等常用Gbps作为单位。
-
GB/s:更多地用于描述存储设备的读写速度、内存带宽等。例如,固态硬盘(SSD)的读写速度、内存模块的数据传输速率等常用GB/s作为单位
根据 https://nvdam.widen.net/s/zmbw7rdjml/infiniband-qm8700-datasheet-us-nvidia-1746790-r12-web
Mellanox QM8790-HS2F:这是一款高性能的InfiniBand交换机,具有40个200Gb/s的端口, 支持无阻塞数据传输,总聚合吞吐量达到16Tb/s。它采用QSFP56连接器,支持被动或主动铜缆和光纤电缆,适用于高性能计算和数据中心等场景
- InfiniBand 网线,交换机什么样?


- 直接用Google文件系统(GFS)满足?取舍是什么?
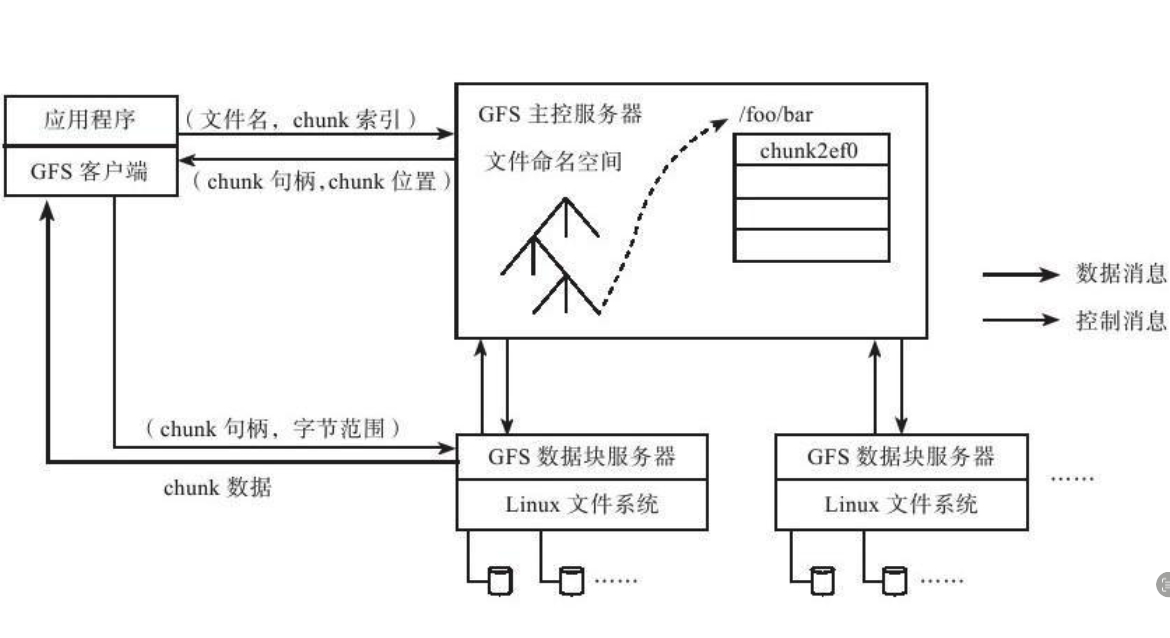 Google文件系统(GFS)是构建在廉价服务器之上的大型分布式系统。
比如廉价的SATA盘,这大大降低了云服务的成本,在和其他厂商的竞争中表现出价格优势
Google的邮箱服务,由于基础设施成本低,Gmail服务能够免费给用户提供更大的容量,
令其他厂商望尘莫及(对比163邮箱)
Google文件系统(GFS)是构建在廉价服务器之上的大型分布式系统。
比如廉价的SATA盘,这大大降低了云服务的成本,在和其他厂商的竞争中表现出价格优势
Google的邮箱服务,由于基础设施成本低,Gmail服务能够免费给用户提供更大的容量,
令其他厂商望尘莫及(对比163邮箱)
我们根据业务负载场景和技术环境,重新审视了分布式文件系统的设计取舍, 把component failure作为常态处理,并面向 大文件、追加写、顺序读 场景做优化, 放松了标准文件系统接口实现。
GFS 读写性能适用场景
适合的场景(性能优异)
✅ 大文件的顺序读写(如日志存储、数据分析)
✅ 大规模数据处理(如 MapReduce、分布式计算)
✅ 追加写入(Append Write)(如日志、数据流写入)
不适合的场景(性能较差)
❌ 小文件存储(因 64MB Chunk 导致存储和 IO 开销大)
❌ 频繁的随机读写(因大块存储导致延迟高)
❌ 高并发的单个 Chunk 访问(容易出现热点问题)
特点如下
-
Google的成功经验也表明了一点:单Master的设计是可行的。 单Master的设计不仅简化了系统,而且能够较好地实现一致性 内存占用:1PB占用多大元数据呃内容
GFS系统中每个chunk大小为64MB,默认存储3份,每个chunk的元数据小于64字节。 那么1PB数据的chunk元信息大小不超过1PB×3/64MB×64=3GB
GFS中的文件一般都是大文件,因此,文件命名空间占用内存不多。
-
GFS中的客户端不缓存文件数据,只缓存主控服务器中获取的元数据, 使用场景,MapReduce,GFS客户端使用方式为顺序读写,没有缓存文件数据的必要
谷歌的文件系统GFS中的文件一般都是大文件,因此,文件命名空间占用内存不多。 这句话对吗?
是的,这句话是正确的。 在 Google 文件系统(GFS) 中,文件通常是 大文件,通常是多个 GB 甚至 TB 级别的存储单位,而不是小文件。 GFS 主要面向大规模数据处理应用(如分布式计算、日志存储、数据分析等) ,这些应用通常会生成并处理超大规模的数据集。
由于 GFS 采用 树形层次结构 维护文件命名空间(类似 UNIX 文件系统),并且 元数据(如文件名、目录结构、文件块映射)是由单独的 Master 服务器维护的,因此:
-
文件数量相对较少
由于 GFS 主要存储大文件,而不是大量小文件,因此文件命名空间(目录和文件名)占用的内存不会太多。 -
Master 服务器的内存占用可控
GFS 设计时,Master 服务器会将元数据存储在 内存 中,以提高访问速度。如果文件数量巨大(例如有数十亿个小文件),Master 服务器的内存占用会迅速膨胀,影响性能。而在 GFS 的大文件场景下,文件数量通常较少,因此命名空间的元数据占用的内存较少,可被 Master 服务器高效管理。
因此,这句话是正确的。
GFS 在大规模数据处理和存储领域表现优秀,但并不适用于小文件和低延迟应用(如传统数据库)。
9 . 直接使用Ceph可以吗?
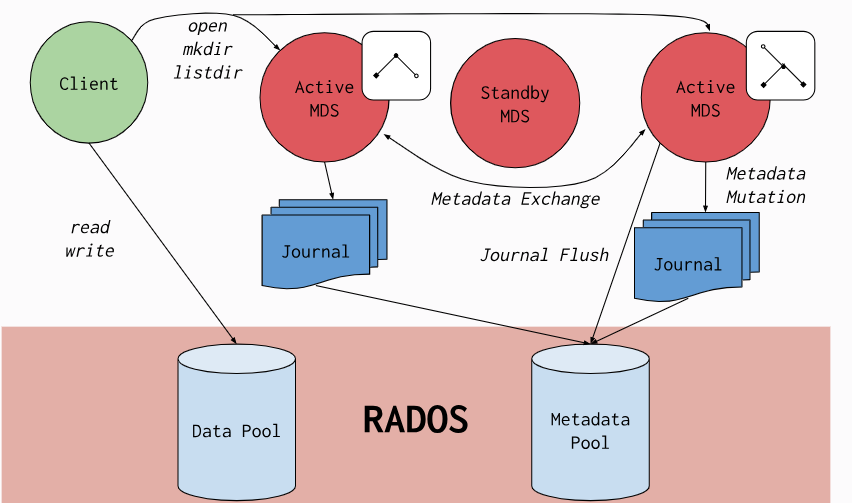
| 问题类别 | 描述 | 影响 | 备注 |
|---|---|---|---|
| 元数据一致性问题 | 多个客户端访问同一文件时,需强制flush写buffer,导致锁等待 | 可能导致高延迟,产生“fail to lock”告警 | 受网络和存储性能影响 |
| MDS 单线程问题 | MDS 处理 I/O 为单线程,所有元数据请求需排队 | 高并发下性能瓶颈明显 | 影响大规模并发场景 |
| 元数据扩展性问题 | 元数据无法线性扩展,多 MDS 负载均衡不稳定 | 影响大规模存储场景 | 需要手工 pin,增加运维复杂度 |
| 小 IOPS 读写时延高 | OSD 侧链路长,存在锁与单线程 flush 限制 | 影响小 IOPS 场景 | 对 AI 训练影响较小 |
mds在主处理流程中使用了单线程,这导致了其单个MDS的性能受到了限制,最大单个MDS可达8k ops/s,CPU利用率达到的 140%左右
以单个 CephFS MDS 在理想硬件环境下的基准测试为例,常见的近似性能指标如下:
| 操作类型 | Ops/s(近似值) | 备注说明 |
|---|---|---|
| 文件创建 | 15,000 – 20,000 | 仅限于纯元数据操作,测试环境为高性能 CPU/SSD 等配置 |
| 文件读取 | 10,000 – 15,000 | 受缓存命中率、元数据复杂性影响 |
| 文件写入 | 8,000 – 12,000 | 写操作中若涉及大写 buffer flush,性能可能进一步下降 |
MDS 单线程的处理架构,导致对小文件高OPS需求的并发处理能力不足
参考
-
幻方力量 | 高速文件系统 3FS https://www.high-flyer.cn/blog/3fs/
-
深入理解计算机系统 CSAPP(原书第三版)
-
BeeGFS并行文件系统体系结构 https://doc.beegfs.io/latest/architecture/overview.html
-
TensorFlow
-
https://github.com/tensorflow/tensorflow/blob/r0.7/tensorflow/examples/tutorials/mnist/input_data.py
-
InfiniBand,到底是个啥?
-
大规模分布式存储系统:原理解析与架构实战