从三万英尺介绍:文件系统Ceph架构
 次阅读
次阅读
文章目录
【注意】最后更新于 August 11, 2023,文中内容可能已过时,请谨慎使用。
把面试官当陪练,在找工作中才会越战越勇 把面试官当陪练,在找工作中才会越战越勇
大家好我是小义同学,这是大厂面试拆解——项目实战系列的第3篇文章,如果有误,请指正。
本文主要解决的一个问题,Ceph为例子 如何描述项目的架构。
画外音:
- 这里假设 面试官可能 本不了解Ceph,更不懂自己 日常工作中哪些"黑话"
- 这并不意味就可以瞎忽悠,他们眼睛就是尺,他们更清楚岗位需什么人。
用户故事:从什么角度描述项目(可跳过)
小义:
先开枪,后瞄准 ,
第一次尝试:不用做任何准备,直接去面试,小义获取项目如何设计,优化的才是取胜的关键。 第二次尝试:面试官问了第二个项目系统设计的,优化的,结果 不到5分钟,回去等消息了。 第三次尝试:面试官回到第一项目怎么设计的,怎么优化的,结果不到5分钟,回去等消息了。 第四次 …… 第五次…. …
这是为何,怎么被同一个问题反复绊倒,
原因1:在准备面试过程中,我大量时间用在算法,和基础知识准备上, 虽然知道项目才是取胜关键,但是根本没有拿出时间来准备。
解决办法:
- 走暗路、耕瘦田、进窄门、见微光
- 专注项目设计,系统优化才是 最重要事情,优先级最高
- 做一次博弈:算法和基础知识必须停止,遇到不会时候在深入研究。
原因2:在日常工作中,我不知道项目模块社交,项目代码,生产bug更重要吗? 但是
- 任务不明确情况下,通过不同做更多任务换取功劳。
- 在代码完成情况下,不停重复人工测试保证质量。
解决办法:
- 走暗路、耕瘦田、进窄门、见微光,
- 专注项目设计,系统优化才是 唯一要做最重要事情
- 做一次博弈: 自己完全想多了,项目架构不了解,模块设计不清楚,代码讲不明白,自己bug解决不了,别人根本不让你测试,找你帮助呢。
画外音:
- 知道什么是最重要事情后,其他事情。能快速投入战斗,速撤离战斗
越战越勇 不是它不是简单地重复一个动作或任务
而是通过专注于自己的薄弱环节,
- 设定明确的目标
- 专注练习
- 并且不断地挑战自己的舒适区
- 及时反馈(如老师、教练、同行,或者是自己通过录像、录音等方式进行自我观察)
- 反复练习改进 从而实现技能的持续提升。
老王:
打住,你想的太复杂了,
先看一下 从什么角度描述一个项目
这是美国著名时间管理大师戴维·艾伦的《搞定3》(英文名:Get things done)。


从第14章 3万英尺来描述,原因如下
- 无论自己学的太差,在不行,至少在项目范围内。
- 自己 跳一跳,向上够一够,让别人稍微弯一下腰,
- 这样达到你知道,我也知道,有话题聊状态。
符合维基百科定义的

下面是最基本沟通方式。为了基本事情达成一致 需要做 什么事情(这个日常工作一样的)
| 象限名称 | 定义 | 我的面试沟通方式 |
|---|---|---|
| 开放区(Open Area) | 自己知道 × 他人知道 | 1. 这是唯一得分地方,想想成一个题目就是10万元奖励,必须结合之前项目经理总结 有效回答.2. 日常听到看到方式在这里全部失灵,八股文毫无价值,必须深入理解经典题目 |
| 盲区(Blind Area) | 自己不知道 × 他人知道 | 1. 就是榆木疙瘩,没有临场发挥,认真记住面试官给你提示,就让游戏到此。2. 有敢于失败勇气,继续原来那一套回答毫无价值,如果有机会反问一次。 |
| 隐藏区(Hidden Area) | 自己知道 × 他人不知道 | 1. 无法税符别人,不去讨论2. 哪怕自己了解c++知道奇淫巧技也也不去说,这个不是面试重点,别人不需要我普及(套方案除外) |
| 未知区(Unknown Area) | 自己不知道 × 他人不知道 | 1. 如实说 不知道,不去探讨。2. 及时听说过一些概念,没有深入研究,坚决不要说,说出来就是瞎胡扯,没人愿意听 |
什么是Ceph
我的回答:
- Ceph是 支持EB数据 高性能,可扩展的 统一的分布式存储平台(参考TDengine宣传,一句话描述)
- 提供支持快,对象,文件(CephFS)服务
- Ceph 项目起源 于 2003 年 Sage 就读博士期间的研究课题(Lustre 环境中的可扩展问题)
- Ceph 使用 商用硬件和以太网 IP 复制数据,并具备容错功能 无需任何特殊硬件支持。
- Ceph 不再依赖任何其他传统文件系统,而是使用其自身的存储后端 BlueStore 直接管理 机械硬盘HDD 和 固态硬盘SSD
对比其他产品宣传:
- TDengine 是一款高性能、分布式的 物联网、工业大数据平台。(一句话介绍)
- TDengine 是一款专为物联网、工业互联网等场景设计并优化的大数据平台,
- 其核心模块是高性能、集群开源、云原生、极简的时序数据库。
- 它能安全高效地将大量设备每天产生的高达 TB 甚至 PB 级的数据进行汇聚、存储、分析和分发,
- 并提供 AI 智能体对数据进行预测与异常检测,提供实时的商业洞察。
面试官视角:
这是20年前的产品:
- 使用的机械硬盘,数百IOPS ,400MB/s带宽,10G容量
- 互斥锁
- 条件变量 ,
- 线程,队列,异步处理
现在都是小儿科了,如果这样回答 是上学背诵的,还是已经理解了 换需要换个问法,马上验证出来了
现在:
- NVMe设备能够提供数百万的IOPS读写,并支持TB级的磁盘容量,大于1G带宽,
- 带宽 200Gbps
- 文件系统平均需要十年的时间才能适应新兴硬件,内核根部无法满足
如果海量请求 , Ceph软件 的性能要跟上硬件发展的速度?为什么。
划重点:英文第一手资料(耗子叔叔推荐方法)
- 高扩展的新一代 Ceph OSD Crimson: Next-generation Ceph OSD for Multi-core Scalabilit
- Ceph近10年来重构心路历程: File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution
Ceph架构是什么
我的回答:
- Ceph这一套存储系统,同时提供对象存储、块存储和文件系统存储三种功能,
- 这极大地简化了不同应用需求下的部署和运维工作
图片来源:From Wikipediahttps://en.wikipedia.org/wiki/Ceph_(software)
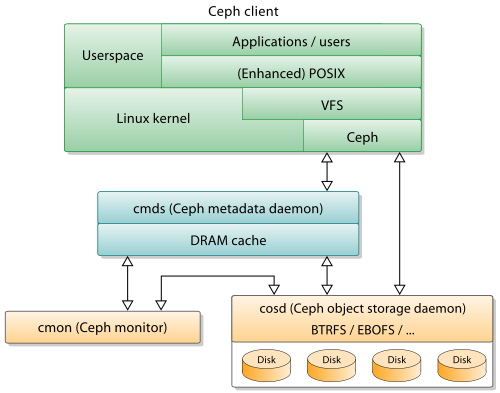
统一存储架构
Ceph最初设计的RADOS是为其实现一个高性能的文件系统服务的, 并没有考虑对于块设备、对象存储的支持, 也就没有什么RBD、RADOS GateWay,跟别提OpenStack和qemu之类的了。
但谁想无心插柳柳成荫, 由于 RADOS 出色的设计和独立简洁的访问接口, 再加上Sage敏锐的眼光, Ceph社区果断推出了用于支持云计算的分布式块存储RBD和分布式对象存储RADOS GateWay, 并将开发中心全面转向云计算领域。
**从架构上来看,RBD和RADOSGateWay实际上都只是RADOS的客户端而已
但得益于RADOS的优秀设计,RBD和RADOSGateWay的设计和实现都很简单,
- 不需要考虑横向扩展、冗余、容灾、负载平衡的等复杂的分布式系统问题,
- 同时能够提供足够多的特性和足够优秀的性能,因此迅速得到了社区的认可。
Ceph的设计思想
Ceph 的设计旨在实现以下目标:
每一组件皆可扩展
无单点故障
基于软件(而非专用设备)并且开源(无供应商锁定)
在现有的廉价硬件上运行
尽可能自动管理,减少用户干预
模块
这些理念使 Ceph 区别于当时的其他存储方案,如 Lustre、Google File System (GFS) 和 Parallel Virtual File System (PVFS)。它包含了以下特性:
-
分布式对象存储:Ceph 从一开始就被设计为一个分布式对象存储系统——名为可靠的自主分布式对象存储(RADOS),而非传统的文件系统。这使得它能够在多个节点上扩展到更大的存储容量。
-
数据与元数据解耦:Ceph 将文件元数据的管理与文件数据的存储分离。这种做法使得元数据和数据操作可以独立处理,从而提高了系统的可扩展性。
-
动态分布式元数据管理:Ceph 采用了一种名为动态子树分区(DSP)的新方法,自适应地在服务器之间分配元数据管理。这使得系统能够在扩张时同步扩展元数据性能。
-
CRUSH 算法:Ceph 引入了可扩展散列下的受控复制(CRUSH)算法,用于确定性地在集群中放置数据。这消除了对集中式数据分配表的需求。
-
智能分布式对象存储:Ceph 将数据迁移、复制、故障检测和恢复等任务委托给存储节点自身,从而使系统更加自主和可扩展。
-
统一存储:Ceph 旨在通过一个平台提供对象存储、块存储和文件存储接口,而不是为每种存储类型提供独立的系统。 高性能
a. 摒弃了传统的集中式存储元数据寻址的方案,采用 CRUSH 算法,数据分布均衡,并行度高。
b. 考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
c. 能够支持上千个存储节点的规模,支持 TB 到 PB 级的数据。
高可用性
a. 副本数可以灵活控制。
b. 支持故障域分隔,数据强一致性。
c. 多种故障场景自动进行修复自愈。
d. 没有单点故障,自动管理。
高可扩展性
a. 去中心化。
b. 扩展灵活。
c. 随着节点增加而线性增长。
特性丰富
a. 支持三种存储接口:块存储、文件存储、对象存储。
b. 支持自定义接口,支持多种语言驱动。
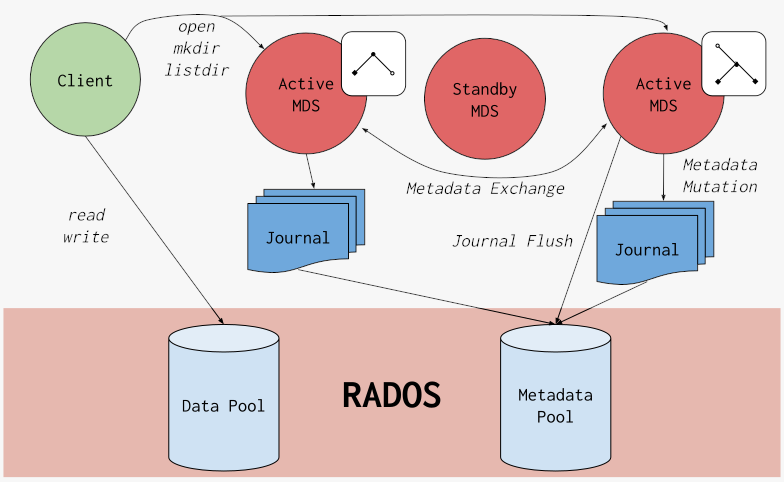
mds
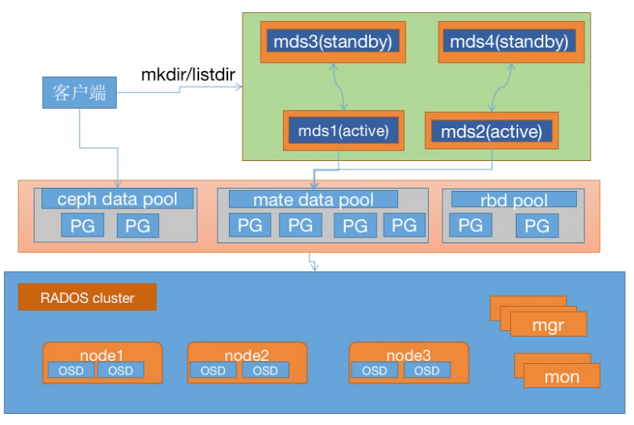
https://static001.geekbang.org/infoq/03/03ede846165b33438d4c2f3eef1ce11c.png
{kind=link}
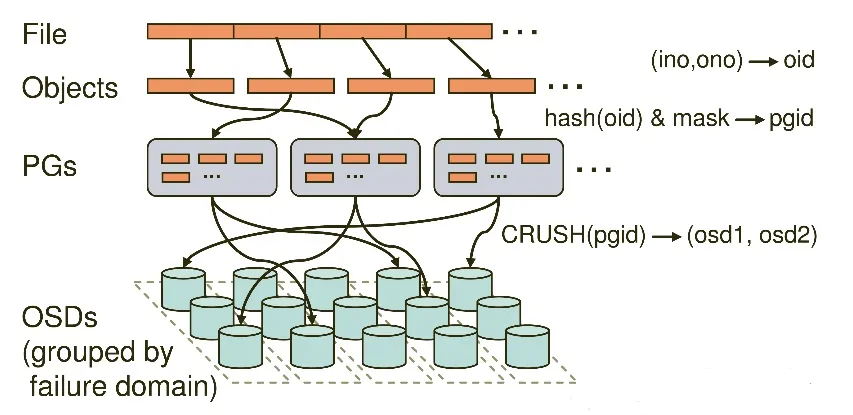
存储文件过程:
第一步: 计算文件到对象的映射:
计算文件到对象的映射,假如 file 为客户端要读写的文件,得到 oid(object id) = ino + ono
ino:inode number (INO),File 的元数据序列号,File 的唯一 id。
ono:object number (ONO),File 切分产生的某个 object 的序号,默认以 4M 切分一个块大
第二步:通过 hash 算法计算出文件对应的 pool 中的 PG:
通过一致性 HASH 计算 Object 到 PG, Object -> PG 映射 hash(oid) & mask-> pgid
第三步: 通过 CRUSH 把对象映射到 PG 中的 OSD
通过 CRUSH 算法计算 PG 到 OSD,PG -> OSD 映射:[CRUSH(pgid)->(osd1,osd2,osd3)]
在线进制转换:https://tool.oschina.net/hexconvert
其他产品
GFS是一个可扩展的大型数据密集型应用的分布式文件系统,该文件系统可在廉价的硬件上运行,并具有可靠的容错能力,该文件系统可为用户提供极高的计算性能,而同时具备最小的硬件投资和运营成本 https://static001.infoq.cn/resource/image/d2/48/d21a15b94b73f116fd914d90b9692248.png
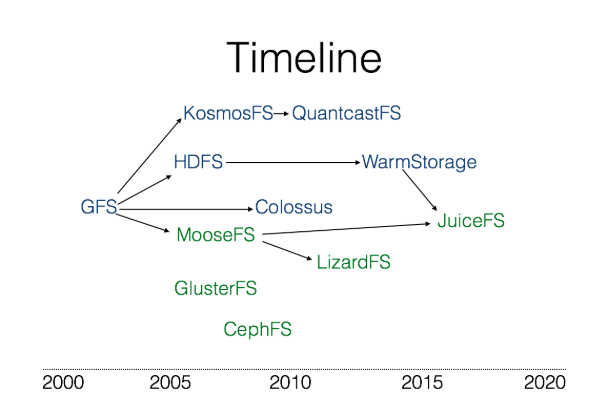{kind=link}
JuiceFS 通过将数据存储到对象存储的方式,有效避免了使用以上分布式文件系统时的双层冗余(块存储的冗余和分布式系统的多机冗余)导致的成本过高问题。JuiceFS 还支持所有的公有云,不用担心某个云服务锁定,还能平滑地在公有云或者区之间迁移数据。
参考资料
【1】 # 分布式存储 Ceph 介绍及原理架构分享(上)完成 https://www.infoq.cn/article/brjtisyrudhgec4odexh [2] https://zhuanlan.zhihu.com/p/68085075 【看完 】 【3】 Ceph 十周年历史 【4】https://www.yuandangsheng.top/?p=3657 【完成】 【5】# 滴滴 Ceph 分布式存储系统优化之锁优化
当应用并发负载较高时,Ceph 很容易出现延迟的 造成延迟的一个重要原因就是代码中锁的使用问题
【5】numve 【完成】
传统存储系统的瓶颈:
- HDD: ~100-200MB/s
- S3对象存储: 受网络带宽限制
- NVMe (Non-Volatile Memory Express)
- 超高读写速度: ~3000-7000MB/s
- 极低延迟: ~10-20μs
- 高IOPS: 数十万至百万级
- 优势:
- 本地存储,无网络开销
- S3: 100GB数据 ≈ 数分钟
- NVMe: 100GB数据 ≈ 数十秒
【7】https://www.cnblogs.com/jhxk/articles/1893314.html https://zhuanlan.zhihu.com/p/545311134
市售的基于NVMe硬盘动辄可达到单盘GB级的读写带宽和十万量级的随机IOPS,为SATA固态硬盘的5~10倍。然而,由于Linux内核驱动实现与调度机制的限制,一般存储软件的表现,相对于NVMe来说,在整个IO事务中消耗的时间百分比就显得太多了