面试题:系统慢 怎么优化
 次阅读
次阅读
文章目录
坚持思考,就会很酷, 大家好,这是大厂面试拆解–项目实战系列的第2篇文章。
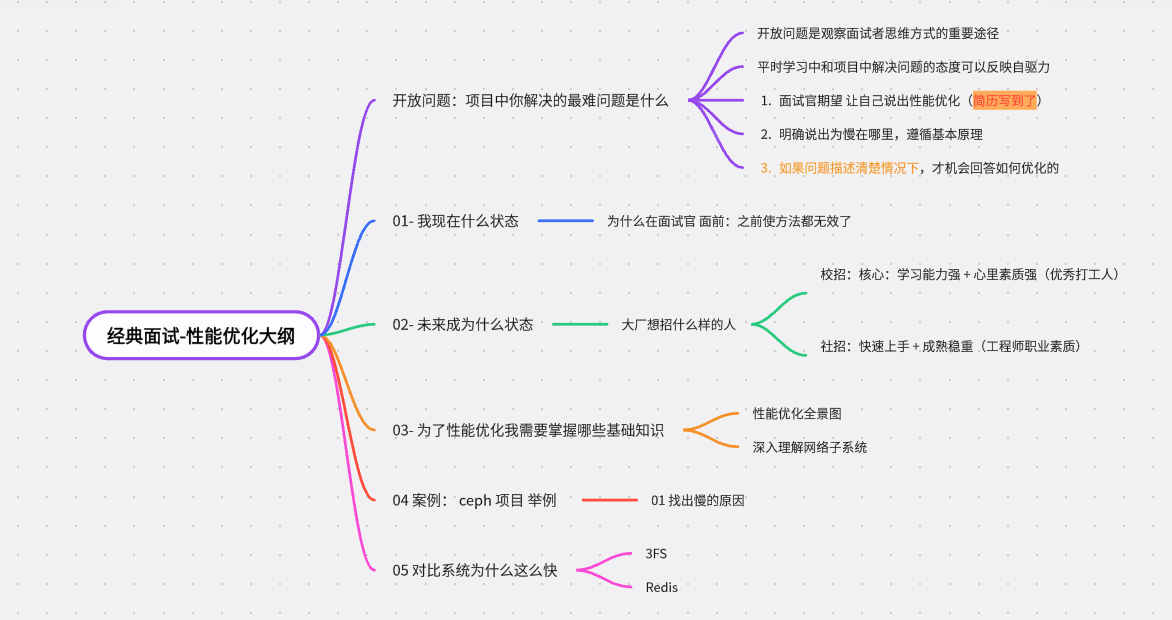
本文通过分布式文件系统ceph 服务 为例子 描述 性能优化的一般过程?
思考 60秒,先别急着划走
- 不了解文件系统没关系,想象成任何你开发一个服务。
- 即使暂时不打算找工作,继续往下阅读,也会有意想不到的收获。
时间到,无论 脑中一片空白 还是 胸有成竹 都没关系。
重要的是 面试官 怎么想
- 工作12年经验,至少P7标准来判断,月薪至少4万 ,无论是单线程改为多线程,单节点升级集群,都是粗暴加机器,和刚毕业生回答没区别,不行,我还需要在考察考察。
- 假如这就是候选人最"熟悉方案呀",面对 质疑,候选人开始 抛弃原来方案,无论怎么回答,这正进入面试设计的坑,这是面试官强项,双11,秒杀 大流量考验,无论怎么回答,候选人都批的体无完肤,一开口就露馅。
这个时候就需要博弈一次,面试官也知道,候选人知道,就在这样事情 在进一步思考 因此,
假如采用最好设备配置
| 硬件配置 | 详情 |
|---|---|
| 场景 | 高性能计算(HPC),企业级服务器 |
| CPU | Intel(R) Xeon(R) Gold 5218R 支持20 个物理核,40个线程 |
| 内存 | 192G(6 * 32G) |
| 网卡 | 1 张 4 口千兆 + 2 张双口 25GE |
| 磁盘 | HDD:36 个 4T SATA 盘SSD: NVME SSD |
根据«每个程序员都应该知道的延迟数字»
- 缓存:访问 L1、L2 缓存时,只有 KB,物理核访问它们的延迟不超过 10 纳秒,速度非常快
- L1,L2为物理核私有,L3为不同的物理核私有,L3的存在是为了让物理核尽量避免访问内存。
- (NVMe)SSD 顺序读取 1 MB, 0.049 ms,转换成秒 就是 带宽 20.41 GB/s, 裸盘性能 至少 7 GB/s,我的服务能达到这样速度吗?不能 为什么。
- 2k数据在千兆网卡 0.02ms,转换成秒 ,一个RPC请求1k大小,QPS大约为10万请求/秒,我的Ceph服务能达到这样速度吗?不能 为什么。
- 如果是万兆网卡,传输速率是1Gbps, 如果 InfiniBand网卡(高性能) 200Gbps,
- 放心 NVIDIA 的 InfiniBand(IB)交换机,40个端,每个端口 200Gb/s 大聚合带宽40Tb/s,Ceph 服务能达到这样速度吗?不能 为什么。
本文思路已经产生了, 分布式存储系统在高性能硬件上,甚至很难将硬件的性能发挥到其1/10 就是深入理解 瓶颈在哪里
本文内容2万字左右,
- 其中 第一 第二部分 为介绍 面试官为什么这问
- 真实项目:ceph 为什么这么慢,如何优化分析
这个不是投机取巧,正如
魔兽争霸3-冰封王座 不死族(UD)选手 现役最强的Happy,绝对S+级别存在(moo不是了),但是被整活哥"Lawliet" 打败过 ,why ,战术博弈成功,哪怕失败了,游戏可以game over后重新再来,
本文最想表达意思,
- 把面试官当初陪练,你才是主角,才会越战越勇。
- 先三开枪,再瞄准(最好找小公司试试)。
一、目前我什么状态。
一天中午,小义 和老王 在餐厅相遇
小义:开始老王吐槽最近面试烦恼
小义眼中的试官
面试官假设一个情景
- 例如 假如你重新开发 一个系统,你如何设计?
- 假如海量并发,你如何优化? 我犹豫一下,然后真实项目方案说一下。
- 如何利用缓存,如何利用并发,如何利用集群,如何拆分数据。
面试官重复描述一下问题是什么? 我还是依旧回答,紧张。 面试官说 我还没听明白 ,不到5分钟本次面试结束。
在老王眼中 看到小义:不知道每天在忙碌什么
小义同学 进入 百人团队,公司有无数的集团大客户,每年不停做千万项目
每天努力干活,却发现在公司有这么多奇怪的现象
- 项目成立,别人完成的
- 系统设计完成了,别人设计的。
- bug解决了,完成的 认真思考时候
- 根本不知道需求是什么 。
- 根本不知道场景是什么。
- 根本不知道发生什么变化。 期待有一天能有时间把源码、框架、问题都搞明白,却始终抽不出时间,
二、未来我要成为什么状态
2.1 了解企业对岗位招聘标准




2.2 熟悉职场晋升打怪升级规则(为什么B类人才这么卷)
S、A、B、C级人才感性上定义
-
S级人才 心里有火,眼里有光,找方向、带队伍、卷出一片天。
不用告诉他干什么,他会主动告诉你该干什么。
-
A级人才**,能打胜仗,作风优良。
- 抓结果:很清楚老板交代任务你后的原因和交付物,及时同步,老板不用追截止日期和进度;
- 发现问题,会和leader确认优先级和方案以后解决问题,之后会复盘如何改进。
-
B类人是各公司内卷和衰落之源(在及格边缘徘徊)
公司加速招聘,都会堆积很多B类人,产出不稳定,及格边缘徘徊。
- 不清楚自己当前任务是什么,不问不会同步进展;
- 发现问题等着别人给流程/推动,leader给了解决方案以后,就照做;
- 不太喜欢学新东西,偶尔学;
-
C类打工人:推三下,动两下,牢骚一句(危险)
-
经常自己独立搞不定,需要别人盯很紧和协助;
-
发现问题就抱怨leader能力不够,抱怨公司不重视,吐槽流程吐槽管理,自己就是不去推动;
-
发到眼前的学习材料也都懒得点开看,封闭/躺平心态;
2.3 为什么有人晋升,有人裁员
| 结果 | 采取有效行动 |
|---|---|
| 有效产出 | 1. 做公司需要的事:专注于公司主路径/目标的事情,避免做对公司不重要的事。(不重要事情坚决不做这个不是小事)2. 让产出可量化,尽量可归因:项目开发多少功能,需要多少时间,提交多少代码,解决多个bug3. 从重要的小事做起:主动争取核心任务,积累信任积分,提升贡献和认可度。不然扣上好高骛远帽子 |
| 眼里有活,主动争取机会 | 1. 主动发现机会:从小事做起,做到极致,为下一步铺路。例如,将贴发票做到分类整理,提出财务建议,最终成为高管。2. 主动研究方向:如主动研究A方向,完成文档上线,带来项目收入。 |
| 主动往前走一步 | 1. 主动接近领导:吃饭时候,开会时候,看到领导要主动打招呼,躲在一边肯定不行 2. 抓住细节机会:文档,邮件,代码 ,具体数字 清楚明白。 |
| 厚脸皮 | 1. 不怕犯错:勇敢面对错误,积极成长。2. 不懂就问:敢于提问,不怕嘲笑。3. 积极求助:遇到困难主动寻求帮助。4. 约见大佬:多次尝试约见行业前辈,用心准备自我介绍,获得学习机会。 |
| 让你的产出被看到 | 1. 及时同步产出:主动汇报工作内容、结果、困难和计划,让领导了解进展。2. 避免形式主义:不搞花哨汇报,注重实际成果。一页纸汇报3. 注意存在感:让产出被看到,而非单纯刷工时,领导关注功劳而非苦劳。纯加班,无产出,也不行 |
为什么每天努力还是无晋升,甚至被裁员 自测一下
-
leader有没老追你进度?提醒你要做xxx?
-
你了解公司、团队和你个人近期最重要的目标是什么吗?
-
你有没主动去和leader对齐过目标?
-
过去3-6个月,做出了啥成绩没?
-
你最近心里/私下的吐槽,有没主动尝试去解决推动?
2.4 匹配:年龄,等级,薪酬之间关系。
产品经理(Product Manage)
角色:产品经理是为终端用户服务
系统工程师(System Engineer)
角色:提供系统软件解决方案
职责:
- 与客户及项目团队进行深入沟通,明确项目需求,并将其转化为技术规格和要求
-
系统工程师,负责系统软件开发、系统软件实施
-
组内各模块骨干做模块设计
能力: SE是一个养成游戏,积累比较快,纯技术,后期是架构师(SA)
项目经理(PM):
角色:
- 轮盘游戏,擅长向上,向下管理,管理岗,完全具备开发能力
职责:
- 管理,日常事务主要是组内员工日常事务,
- 任务分配,
- 项目进度跟踪,风险把控,以及资源协调
能力: - 要带队(开发重要项目),要救火(解决生产问题),要PUA基层(向下)
约束:35岁后没有向上的坑
开发岗位 或者ob
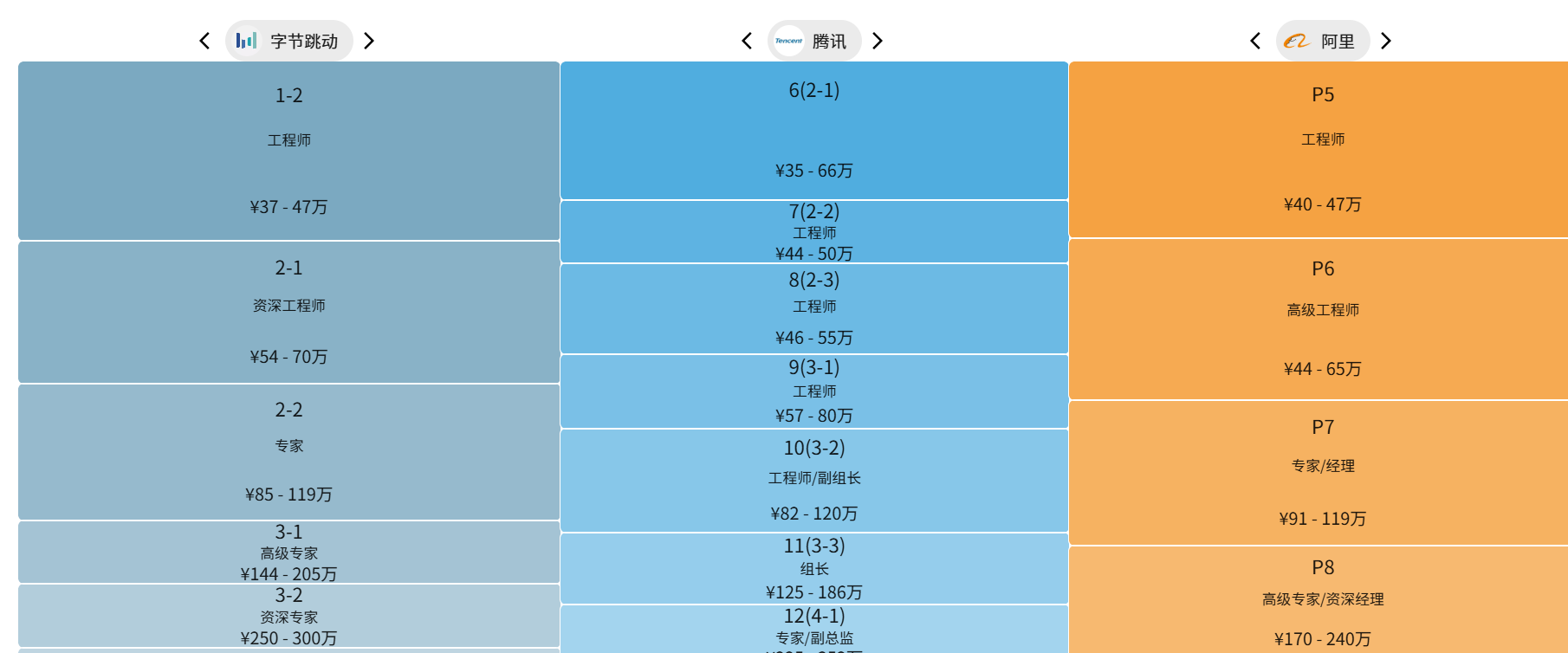
阿里巴巴研发职级体系(C++方向)仅供参考
| 职级 | 能力要求 | 工作年限 | 典型薪资范围(年薪,含股票) |
|---|---|---|---|
| 新手村 P5 | 1. 掌握C++11/17标准及基础数据结构/算法 2. 在指导下完成模块开发(如日志系统) 3. 熟悉Linux开发环境及GDB调试 | 0-2年 | 25-35万(平均月薪21.8K) |
| 大头兵 P6 | 1. 独立开发高并发中间件(如RPC框架) 2. 掌握多线程/内存优化技术 3. 主导中型项目(日请求量百万级) | 3-5年 | 40-60万(平均月薪29.1K) |
| 主力军 P7 | 1. 设计分布式存储系统(如KV数据库) 2. 解决C++内存泄漏/性能瓶颈 3. 管理5-10人团队,制定代码规范 | 5-8年 | 60-150万(平均月薪39.5K) |
| 老油条P8 | 1. 主导亿级QPS系统架构(如交易核心链路) 2. 开发高性能网络库(如DPDK应用) 3. 管理50人团队 | 8-12年 |

三、为了解决这个问题,我需要准备什么
3.1 大局观 不同并发不同技术方案
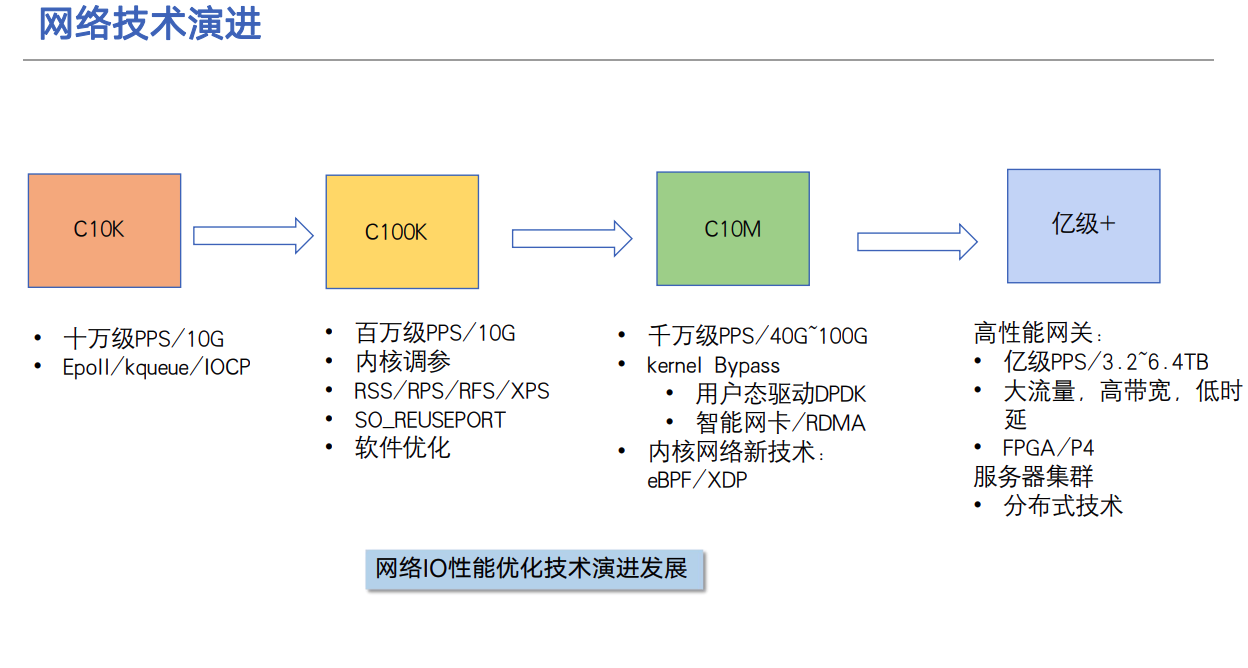
C10K(万)解方法
- 背景:C10K 是指如何单机同时处理 1 万个请求。
- 背景:瓶颈不在物理资源:Dan Kegel 在 1999 年提,2GB内存 和千兆网卡完全满足,当时Linux 2.2 版。
- 内核:Linux 2.6 中引入的 epoll,完美解决了 C10K 的问题
- 产品: Nginx,主进程 + 多个 worker 子进程
- 优化1:内核解决epoll惊群问题,到了 Linux 4.5 ,才通过 EPOLLEXCLUSIVE 解决
- 优化2:监听到相同端口的多进程模型。SO_REUSEPORT 选项,用 Linux 3.9 以上的版本才解决
- I/O 模型的优化,是解决 C10K 问题的最佳良方。
C1000K(百万)解决方法
- 背景:随着摩尔定律带来的服务器性能提升,以及互联网的普及,C10K 已经不能满足需求C1000K 则是单机支持处理 100 万个请求
- 遇到挑战:千兆网卡满足不了,100 万个请求,假设只有 20% 活跃连接,即使每个连接只需要 1KB/s 的吞吐量,总共也需要 1.6 Gb/s,千兆网卡显然满足不了这么大的吞吐量,所以还需要配置万兆网,多网卡 Bonding 承载更大的吞吐量
- 遇到挑战:大量的连接也会占用大量的软件资源,假设每个请求需要 16KB 内存的话,那么总共就需要大约 15 GB 内,网络协议栈的缓存大小(比如套接字读写缓存、TCP 读写缓存)
- 遇到挑战:大量请求带来的中断处理,需要多队列网卡、中断负载均衡、CPU 绑定、RPS/RFS(软中断负载均衡到多个 CPU 核上),以及将网络包的处理卸载(Offload)到网络设备(如 TSO/GSO、LRO/GRO、VXLAN OFFLOAD)等各种硬件和软件的优化。
- RPS/RFS 功能是在Linux- 2.6.35中有google的工程师提交的两个补丁,由于过多的网卡收包和发包中断集中在一个CPU上,在系统繁忙时,CPU对网卡的中断无法响应,这样导致了服务器端的网络性能降低
- 解决方案:本质上还是构建在 epoll 的非阻塞 I/O 模型,基于 C10K 的这些理论,但是从应用程序到 Linux 内核、再到 CPU、内存和网络等各个层次的深度优化,特别是需要借助硬件
C10M (千万)解决方法
- 背景:http://c10m.robertgraham.com/p/blog-page.html、随着数据中心的飞速发展,高性能网络不断挑战着带宽与时延的极限,网卡带宽从过去的 10 Gb/s 、25 Gb/s 到如今的 100 Gb/s、200 Gb/s 再到下一代的 400Gb/s 网卡,其发展速度已经远大于 CPU 发展的速度
- 遇到的挑战1:在 C1000K 问题中,各种软件、硬件的优化很可能都已经做到头了。特别是当升级完硬件(比如足够多的内存、带宽足够大的网卡、更多的网络功能卸载等)后,你可能会发现,无论你怎么优化应用程序和内核中的各种网络参数,想实现 1000 万请求的并发,都是极其困难的。【原理方式已经不能在使用了】
- 遇到挑战2:多核可扩展,单个任务必须分散到多个 CPU 上执行。这需要彻底的重新思考,例如,如何实现永远不会导致线程停止和等待的同步
- 遇到的挑战2:内存问题,128GB 相比 15 年前,加了一千倍,L1 和 L2 缓存的大小却保持不变,L3(即最后一级)缓存的大小仅增加了 10 倍。这意味着在大规模情况下,每个指针都会导致一次缓存未命中。为了解决这个问题,代码必须关注缓存和分页的问题。
- 原因分析:还是 Linux 内核协议栈做了太多太繁重的工作。从网卡中断带来的硬中断处理程序开始,到软中断中的各层网络协议处理,最后再到应用程序,这个路径实在是太长了,就会导致网络包的处理优化,到了一定程度后,就无法更进一步了。
- 解决办法1 :最重要就是跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里。

-
第一种机制,DPDK,是用户态网络的标准。它跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收
-
为什么真全闪分布式存储离不开 RoCE/RDMA 流控技术? 可靠性指标提升 在有 RDMA 流控的情况下,故障切换规格可控制在 2 秒内,有效降低了业务中断风险 在使用 RDMA 流控时,网络带宽利用率可高达 90%,从而加快了数据恢复进程。
敲黑板:思维方式变迁
- 十年前,应用程序异步编程 + 内核支持方式 ,工程师们解决了c10k 问题。
- 现在C10M 中,在内核无法支持的情况下,在异步的基础上,用内核态转型用户态。
3.2 性能优化技术全景图
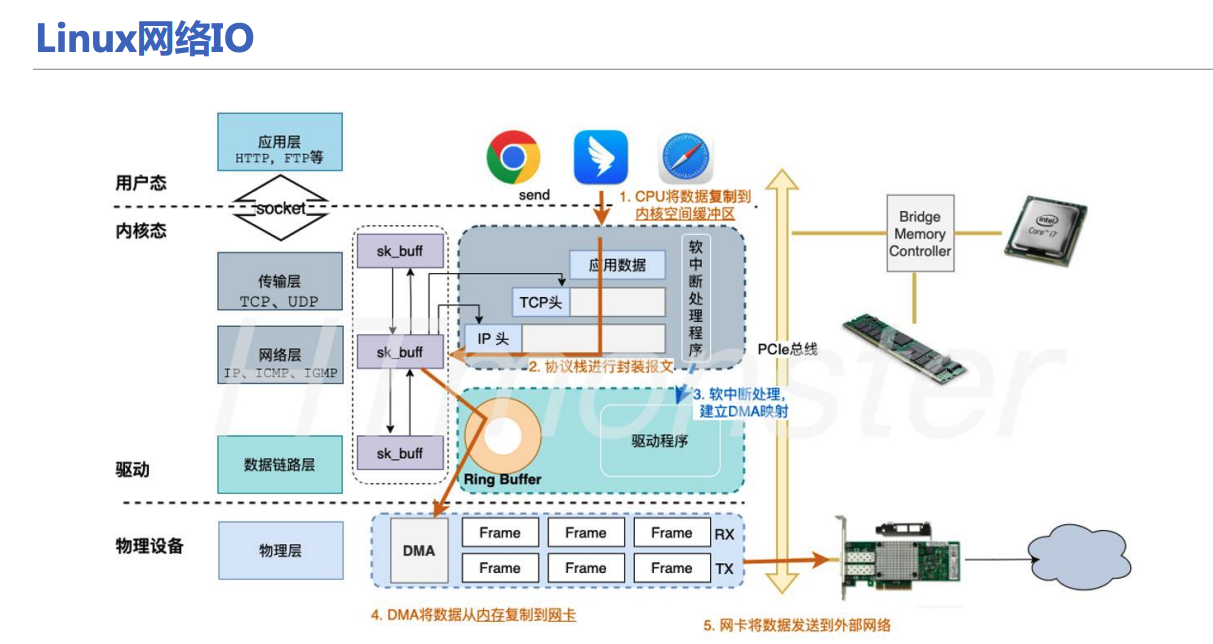
3.3 性能优化工具景图
来源:https://www.brendangregg.com/linuxperf.html

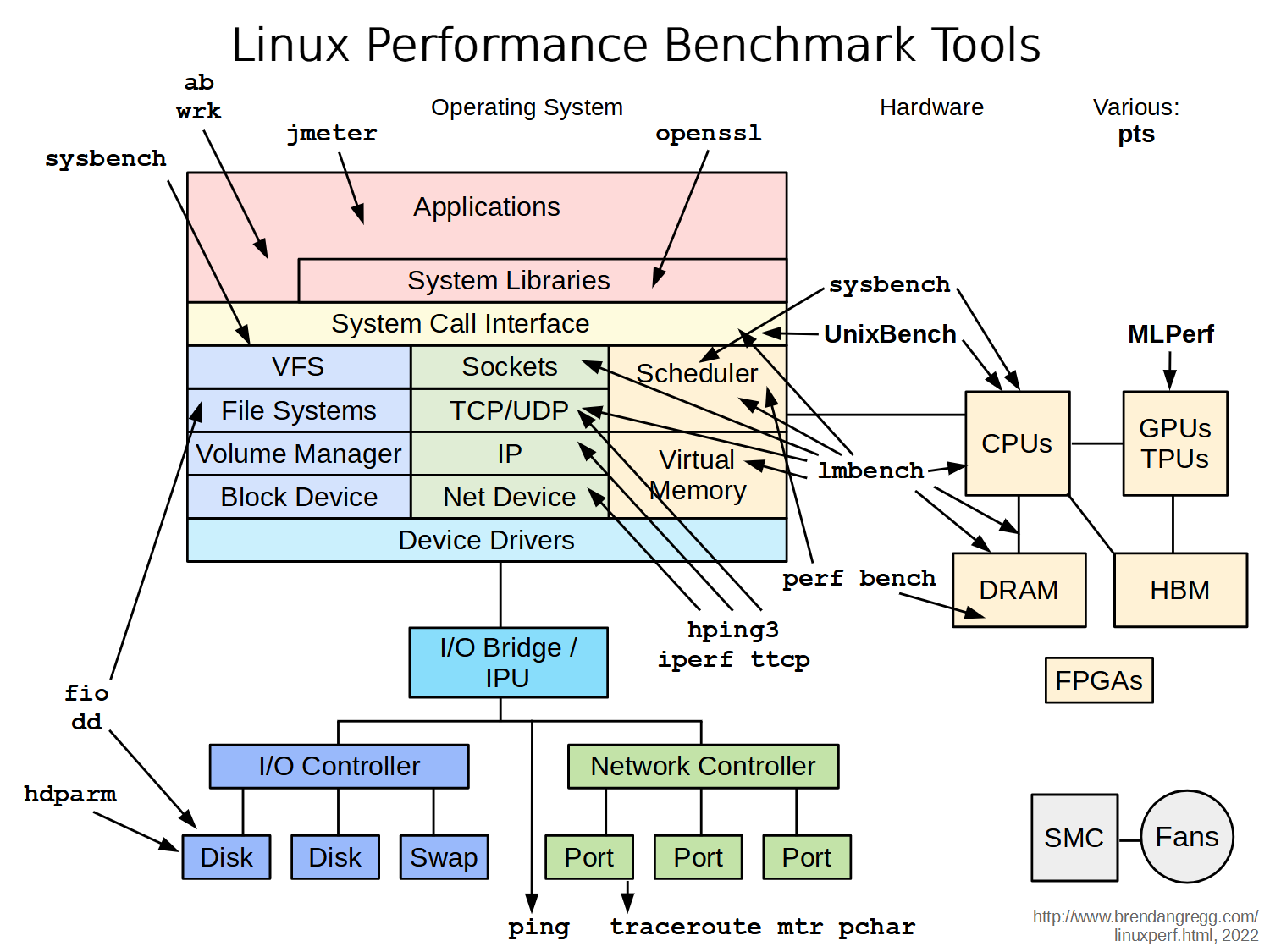
3.4 熟悉基本命令
—————————–才刚刚开始———————————
四、必须清楚原来IO流程是什么
cpu
每个 OSD 拥有 2-4 个核心时,Ceph 在小规模读取和写入操作中几乎可以充分利用所有核心。添加更多核心(每个 OSD 甚至最多 16 个以上)可以提高性能,但每个核心带来的收益会降低。
✅ 多核扩展性测试分析:
- 现象:在 16 核服务器上,OSD IOPS 随 CPU 核数增加而非线性提升。
- 表现:
- 4 核时接近线性提升,说明资源尚未饱和,扩展性较好。
- 超过 8 核后增速骤降至 30% 以下,表明扩展性受到瓶颈限制。
- 原因:
-
锁竞争:多线程操作共享数据结构时争用锁资源,CPU 越多竞争越激烈。
-
线程切换开销:线程之间频繁切换带来上下文切换、CPU缓存失效等开销。
-
这种现象在高并发 IO 密集型系统(如 Ceph OSD)中是常见的,称为多核扩展性退化(Scalability Bottleneck)。
✅ 线程切换次数统计:
-
工具:你提到的
perf是标准的 Linux 性能分析工具,适合监控上下文切换等低层事件。 -
观察:
- 每次 4KB 随机写触发 约 12 次线程切换。
- 包含:
- 用户态 <-> 内核态切换(syscall)
- 线程池内部任务移交(如线程从处理网络收包,交由另一个线程写磁盘)
-
结论:高线程切换频率意味着调度器负担重、上下文切换成本高,是导致性能下降的关键因素之一。
一、底层机制:为什么共用CPU会导致瓶颈?
1. 软中断(SoftIRQ)的特性
- 触发场景:网卡接收/发送数据包时,会通过硬件中断通知CPU(硬中断耗时极短),随后内核触发软中断(SoftIRQ)完成实际的数据包处理(如TCP/IP协议栈解析、内存拷贝等)。
- CPU消耗:单个千兆网卡满负载时,软中断可能占用1个CPU核心的30%以上;万兆/25G网卡可达单个核心100%。
- 不可抢占性:软中断在Linux内核中具有高优先级,会抢占用户态进程(如Ceph OSD/RGW)。
2. Ceph进程的CPU需求
- OSD进程:负责数据副本读写、一致性校验(如PG的Scrub)、CRUSH计算等,需要持续CPU算力。
- RGW进程:处理S3/Swift API请求(JSON解析、SSL加解密),属于CPU密集型+延迟敏感型任务。
3. 冲突的本质
当软中断和Ceph进程共享同一个物理CPU核心时:
- 资源竞争:二者争夺CPU时间片,内核调度器频繁进行上下文切换(Context Switch)。
- 缓存污染:软中断处理的数据包会占用CPU缓存(L1/L2/L3),导致Ceph进程的缓存命中率下降。
- 延迟放大:软中断的高优先级导致Ceph进程被频繁抢占,表现为I/O延迟抖动(Latency Spikes)
其他产品 redis
为什么CPU结构也会影响Redis的性能?
CPU 多核对 Redis 性能的影响

why
Redis 总是在不同 CPU 核上来回调度执行。 于是,我们尝试着把 Redis 实例和 CPU 核绑定了, 让一个 Redis 实例固定运行在一个 CPU 核上。


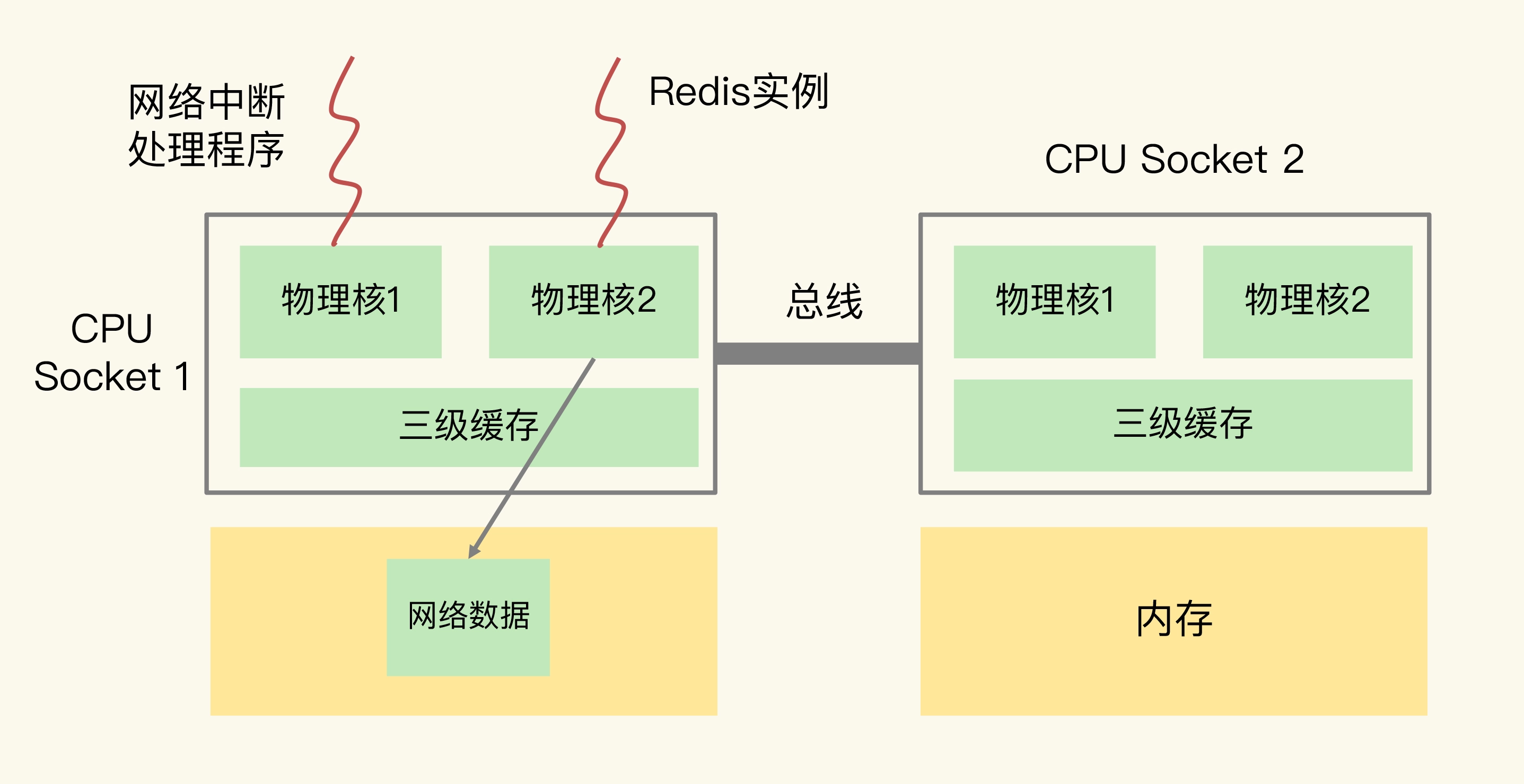
方案一:一个 Redis 实例对应绑一个物理核 taskset -c 0,12 ./redis-server
和只绑一个逻辑核相比,把 Redis 实例和物理核绑定,可以让主线程、子进程、后台线程共享使用 2 个逻辑核,可以在一定程度上缓解 CPU 资源竞争
方案二:优化 Redis 源码这个方案就是通过修改 Redis 源码,把子进程和后台线程绑到不同的 CPU 核上。
参考资料
-
测试块存储性能https://www.alibabacloud.com/help/zh/ecs/user-guide/block-storage-performance
-
调优 Ceph 可能是一项艰巨的挑战。在 Ceph、RocksDB 和 Linux 内核之间,有成千上万个选项可供调整,以提高性能和效率,在 BlueStore 的开发初期,我们观察到将元数据存储在 RocksDB 中的开销对性能有巨大影响。对于小型随机写入尤其如此
-
BlueStore 不仅将对象元数据写入 RocksDB,还存储 BlueStore 的内部状态,包括 pglog 更新、数据区和磁盘分配等数据。其中一些数据的生命周期非常短:它们可能被写入后几乎立即被删除。RocksDB 处理这种情况的方式是,首先将数据写入内存中的 memtable,然后将其附加到磁盘上的预写日志 (write-ahead-log)。当请求删除该数据时,RocksDB 会写入一个“墓碑”,指示该数据应该被移除。当写入和随后的删除同时被刷新时,只有最近的更新会持久化到数据库中
-
将OSD和RGW进程绑定到固定CPU核上,避免个别CPU压力过大 就像给高速公路划分了货车专用道和小客车专用道,各走各的不堵车,整个系统的网络处理和存储性能都会更稳定!
- 性能测试必备知识(9)- 深入理解“软中断”
- https://wenfh2020.com/2021/10/11/thundering-herd-nginx-epollexclusive/ 探索惊群
链接我
坚持思考,方向比努力更重要。
关注公共号:后端开发成长指南 回复电子书
如果更进一步交流 添加 微信:wang_cyi

我是小王同学,
希望帮你深入理解分布式存储系统3FS更进一步 , 为了更容易理解设计背后原理,这里从一个真实面试场故事开始的。
阅读对象(也是我正在做事情)
1. 目标:冲击大厂,拿百万年薪
- 想进入一线大厂,但在C++学习和应用上存在瓶颈,渴望跨越最后一道坎。
2. 现状:缺乏实战,渴望提升动手能力
-
公司的项目不会重构,没有重新设计的机会,导致难以深入理解需求。
-
想通过阅读优秀的源码,提高代码能力,从"不会写"到"敢写",提升C++编程自信。
-
需要掌握高效学习和实践的方法,弥补缺乏实战经验的短板。
3. 价值:成为优秀完成任务,成为团队、公司都认可的核心骨干。
优秀地完成任务= 高效能 + 高质量 + 可持续 + 可度量
错误示范:
- 不少同学工作很忙,天天加班,做了很多公司的事情。 但是 不是本团队事情,不是本部门事情,领导不认可,绩效不高
- 做低优先级的任务,无法利他,绩效不高
- 招进来最后变成了随时被裁掉的一些征兆
- 刻意提高工作难度
- 工作中不公平对待
- 制造恶性竞争
- 捧杀