深入浅出理解DeepSeek 3FS (3) 步步引导轻松理解内存管理,面试必看
 次阅读
次阅读
文章目录
PART 01 概念:分布式存储存储服务(CEPH,NAS),SMB,和CTDB 之间什么关系
1. 什么是Samba服务,使用场景
使用场景
随着智能化互联时代的来临,家中的智能设备越来越多:电视机、平板、游戏主机、电脑、手机等遍及家中各个角落,同时设备之间共享数据的需求变的越来越强烈, 这时候在家中搭建一台 NAS(Network Attached Storage:网络附属存储)存储服务器, 或者其他分布式存储服务 CephFS
NAS 常见的共享访问协议:NFS、SMB。
NFS(网络文件系统 Network File System)是一种分布式文件系统协议,力求客户端主机可以访问服务器端文件,并且其过程与访问本地存储时一样
-
NFS 的优点是内核直接支持,部署简单、运行稳定,协议简单、传输效率高。
-
NFS 的缺点是没有加密授权等功能,仅依靠 IP 地址或主机名来决定用户能否挂载共享目录
FUSE,implementing filesystems in user space,在用户空间实现文件系统 简单讲,用户可通过fuse在用户空间来定制实现自己的文件系统。
问 NFS-Ganesha 和FUSE关系: NFS-Ganesha就是实现FUSE的一种方式。
NFS-Ganesha是一个用户态的支持NFS协议(NFSv3/NFSv4,NFSv4.1)的文件服务器,
它为Unix和类Unix的操作系统提供了FUSE(Filesystem in Userspace)兼容的接口FSAL(File System Abstraction Layer) 。
这样用户通过NFS Client可以访问自己的存储设备

问:nfs-ganesha and CephFS关系是什么?
- 通过NFS-Ganesha 访问CephFS提供的文件

主要区别:NFS 与SMB
官方文档: https://www.samba.org/samba/ Samba is the standard Windows interoperability suite of programs for Linux and Unix. Samba 是适用于 Linux 和 Unix 的标准 Windows 互操作性程序套件。
SMB(Server Message Block,服务器消息块)是一种网络文件共享协议,主要用于在不同计算机之间共享文件, 它由 IBM 的 Barry Feigenbaum 于 1983 年发布,适用于 DOS 操作系统,即 Windows 的前身。通过与 Windows 产品套件深度集成,SMB 仍然作为 Windows 操作系统的默认文件共享协议
客户端-服务器通信的过程大体上与 NFS 类似,区别在于前者的细节和操作机制更加精细
| NFS | SMB | |
| 它是什么? | 网络文件系统。 | 服务器消息块。 |
| 最适合 | 基于 Linux 的网络架构。 | 基于 Windows 的架构。 |
| 共享资源 | 文件和目录。 | 广泛的网络资源,包括文件和打印服务、存储设备和虚拟机存储。 |
| 客户端的通信对象 | 服务器。 | 服务器,客户端可以通过将服务器用作调解器来与其他客户端通信。 |
CTDB 与SMB关系,使用场景
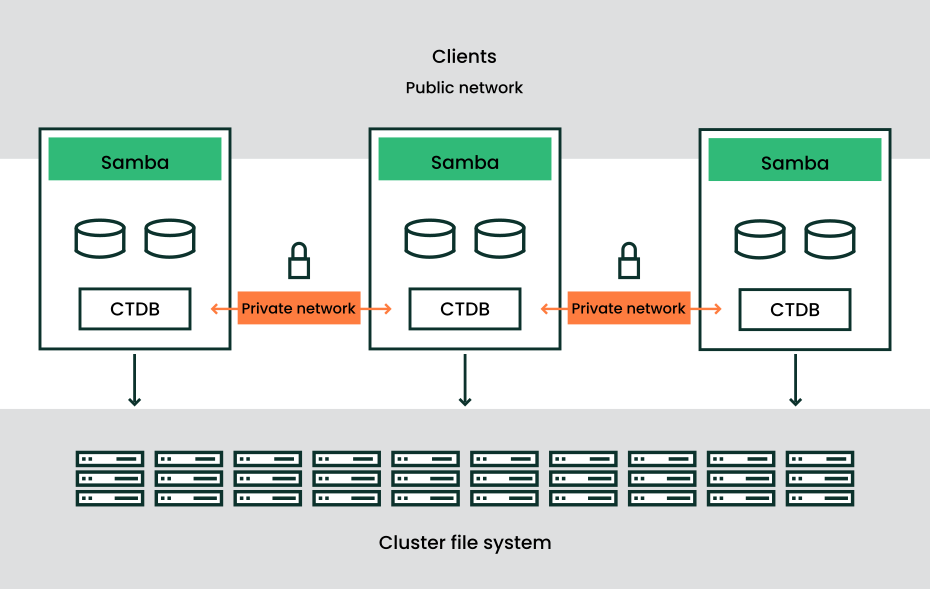
ctdb作用1:提供虚拟ip供客户端访问使用。虚拟ip可以在ctdb节点间漂移,实现高可用
ctdb作用2:管理其他服务。如smb、ganesha、tgt、rgw等,监控到服务异常时进行一些处理,如尝试重新拉起服务,将该节点虚拟ip飘走
- CTDB是Samba3/4的一个核心组件
CTDB (clustered trivial database,轻量级集群数据库)作为一种集群高可用管理软件,用于 监控集群节点状态,多个启动CTDB的节点构成一套CTDB集群,集群中所有节点会选举出一 个主节点,用于故障恢复
- CTDB非常快速
- CTDB可以提供为应用指定特定的管理脚本,使得应用能够实现高可用
- CTDB提供可热拔插的后端传输通道,目前实现了TCP和IB
- CTDB提供高可用特性,例如节点监控、节点切换、IP切换;
- CTDB提供一个横跨多个节点的并且数据一致、锁一致的TDB数据库
- CTDB节点之间需要通过一个共享的存储来实现其基于锁机制的选举过程。
划重点: 要使用 CTDB条件,则必须有一个可用的集群文件系统, 且该文件系统可为该集群中的所有节点共享
CTDB模块目前已经在NAS、SAN、对象集群中作为高可用模块广泛使用,提供虚拟IP漂移、节点监控管理、模块监控等
说明:
CTDB本身不是HA解决方案,但与集群文件系统相结合,
它可以提供简单且高效的HA集群解决方案:
- 集群配置两组IP:Private IP用于heartbeat和集群内部通信。
- Public IP用于对外提供虚拟访问IP,
- 当内部的节点发生宕机故障时,C
TDB将调度其他可用节点接管其原先分配的Public IP,
故障节点恢复后,漂移的Public IP会重新被接管,保证服务不中断。
这个过程对客户端是透明的,保证应用不会中断,也就是我们这里所说的高可用HA
CTDB的运行机制
为了使用CTDB,需要一个分布式文件系统(比如:GFS、CephFS、OCFS2等)为集群中的所有节点共享。CTDB 管理节点成员、执行恢复/故障切换、IP 重新定位以及监控管理服务的状态。
集群中每个节点都运行了一个CTDB的守护进程ctdbd,以Samba为例,应用服务并不是直接向其TDB数据库写入数据,而是与它的本地ctdbd守护进程进行交互,守护进程会通过网络与TDB数据库中的元数据进行交互。但是对于具体的数据写和读操作,一般是在本地存储上维护一个本地的副本。
CTDB拥有两种TDB文件:普通的和持久性的。根据不同的需求,CTDB对这两种TDB文件的处理方式完全不同:
1) 持久性的TDB文件会实时更新,并在每个节点上存储一个最新的副本。为了读写性能的考虑,持久性的TDB文件保存在本地存储上而不是共享存储中。数据在写入持久TDB时,它会锁定整个CTDB数据库,然后执行读/写操作,事务提交操作最终会被分发到所有节点,并在每个节点的本地写入。
2) 普通TDB文件是临时维护的,其原则是:每个节点不必知道数据库中的所有记录,只需知道影响它自己的客户端连接的记录就足够了。所以,即使某个节点宕机,丢失了此节点相关的所有普通TDB记录,也不会影响其他节点。
ctdb为3秒内检测故障,做什么优化
下面是基本背景
CTDB(Clustered Trivial Database)的通信方式主要包括以下几种:
1. TCP 通信
- 工作原理 :CTDB 支持通过 TCP 进行节点间的通信。每个节点上的 ctdb daemon 进程会通过 TCP 建立与其他节点的连接。例如,进程会创建一个 TCP 监听套接字,等待其他节点的连接请求。当有节点发起连接时,会接受连接并建立通信链路。同时,进程还会主动向其他节点发起 TCP 连接,以便与其他节点进行数据交互。
- 应用场景 :适用于集群节点之间跨越不同网络环境或需要通过标准网络协议进行通信的场景,是 CTDB 最常用的通信方式之一。
2. Unix 域套接字通信
- 工作原理 :在同一节点内部,ctdb daemon 进程与 ctdb recoverd 进程以及其他本地进程(如监控脚本等)之间通过 Unix 域套接字进行通信。进程会绑定一个 Unix 域套接字,用于监听来自本地其他进程的连接请求。当收到连接请求后,会接受连接并进行数据交互。
- 应用场景 :主要用于节点内部进程之间的通信,具有高效、低延迟的特点,适合在同一台主机上不同进程间快速传递信息。
3. Infiniband 通信(可选)
- 工作原理 :CTDB 还支持 Infiniband 作为通信后端。Infiniband 是一种高速、低延迟的网络技术,能够提供比传统 TCP/IP 网络更高的数据传输速率和更低的延迟。在使用 Infiniband 通信时,CTDB 会利用 Infiniband 提供的高效通信机制,实现集群节点之间的快速数据交互。
- 应用场景 :适用于对性能要求极高的集群环境,如高性能计算集群或需要快速数据同步的存储集群等。通过使用 Infiniband,可以显著提高集群的整体性能和响应速度。
4. 集群文件系统通信
- 工作原理 :CTDB 依赖于集群文件系统来实现数据的一致性和共享。集群文件系统本身提供了一种机制,使得多个节点可以同时访问和操作共享存储中的数据。CTDB 在集群文件系统的基础上,通过在文件系统中存储和管理 TDB 数据库文件,实现集群节点之间的数据共享和同步。
- 应用场景 :适用于需要在多个节点之间共享和访问同一数据集的场景,如分布式存储系统、高可用文件服务器等。通过与集群文件系统结合,CTDB 可以实现数据的高可用性和一致性。
CTDB(Clustered Trivial Database)的选举机制依赖于共享存储来实现基于锁的协调,这是因为共享存储提供了一个所有集群节点都能访问的“公共区域”
[cluster] recovery lock = /mnt/ctdb/.ctdb.lock 在这种情况下,锁文件位于集群文件系统中,所有节点通过访问同一个锁文件来协调选举。
假设一个 CTDB 集群中有三个节点:Node A、Node B 和 Node C。以下是基于锁机制的选举过程示例:
-
触发选举:Node A 发现当前主节点故障,触发选举。
-
尝试获取锁:Node A 尝试在共享存储的锁文件上获取锁。
-
其他节点响应:Node B 和 Node C 也尝试获取锁,但发现锁文件已被 Node A 占用。
-
锁的优先级判断:Node A 根据规则(如启动时间最早)确认自己有资格成为主节点。
-
通知其他节点:Node A 成功获取锁后,向 Node B 和 Node C 发送通知,告知自己成为新的主节点。
-
更新状态:Node B 和 Node C 释放锁文件,并更新自己的状态信息,承认 Node A 为新的主节点。
5. 为什么需要锁机制?
-
互斥性:锁机制确保同一时间只有一个节点可以成为主节点,避免多个节点同时认为自己是主节点,从而导致数据不一致或冲突。
-
同步性:锁机制通过共享存储提供了一种同步机制,确保所有节点在选举过程中能够协调一致地行动。
通过共享存储和锁机制,CTDB 能够在分布式环境中高效地协调主节点的选举过程,确保集群的高可用性和一致
# Under standing BlueStore, Ceph’s New Storage Backend
https://www.youtube.com/watch?v=kzTgIcp4FfY https://docs.redhat.com/zh-cn/documentation/red_hat_ceph_storage/4/html/administration_guide/ceph-bluestore-caching_admin
bluestore 的诞生是为了解决 filestore 自身维护一套journal 并同时还需要基于文件系统的写放大问题,并且 filestore 本身没有对 SSD 进行优化,因此 bluestore 相比于 filestore 主要做了两方面的核心工作:
- 去掉 journal ,直接管理裸设备
- 针对 SSD 进行单独优化
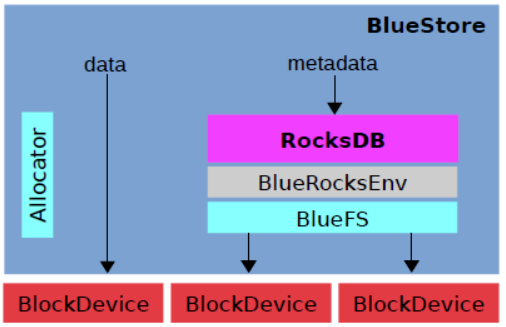 通过Allocator(分配器)实现对裸设备的管理,直接将数据保存到设备上;同时针对 metadata 使用 RocksDB 进行保存,底层自行封装了一个BlueFS用来对接RocksDB 与裸设备
通过Allocator(分配器)实现对裸设备的管理,直接将数据保存到设备上;同时针对 metadata 使用 RocksDB 进行保存,底层自行封装了一个BlueFS用来对接RocksDB 与裸设备
模块划分
核心模块
- RocksDB: 存储预写式日志、数据对象元数据、Ceph的omap数据信息、以及分配器的元数据(分配器负责决定真正的数据应在什么地方存储)
- BlueRocksEnv: 与RocksDB交互的接 Understanding BlueStore, Ceph’s New Storage Backen
参考资料
-
NAS存储卷概述 https://help.aliyun.com/zh/ack/serverless-kubernetes/user-guide/nas-volume-overview-3 【done】
-
https://patents.google.com/patent/CN109379238A/zh# 一种分布式集群的ctdb主节点选举方法、装置及系统
-
https://wiki.samba.org/index.php/Configuring_the_CTDB_recovery_lock 【完成】‘
-
ctdb
-
BlueStore是 Ceph 的下一代存储实施。作为存储设备的市场,存储设备的市场现在包括固态驱动器或 SSD,以及 PCI Express 或 NVMe 的不易失性内存
https://www.youtube.com/watch?v=kuacS4jw5pM
链接我
如果对上面提到c++学习路径 推荐书籍感兴趣
关注公共号:后端开发成长指南 回复电子书
如果更进一步交流 添加 微信:wang_cyi

我是小王同学,
希望帮你深入理解分布式存储系统3FS更进一步 , 为了更容易理解设计背后原理,这里从一个真实面试场故事开始的。
阅读对象(也是我正在做事情)
1. 目标:冲击大厂,拿百万年薪
- 想进入一线大厂,但在C++学习和应用上存在瓶颈,渴望跨越最后一道坎。
2. 现状:缺乏实战,渴望提升动手能力
-
公司的项目不会重构,没有重新设计的机会,导致难以深入理解需求。
-
想通过阅读优秀的源码,提高代码能力,从“不会写”到“敢写”,提升C++编程自信。
-
需要掌握高效学习和实践的方法,弥补缺乏实战经验的短板。
3. 价值:成为优秀完成任务,成为团队、公司都认可的核心骨干。
优秀地完成任务= 高效能 + 高质量 + 可持续 + 可度量
错误示范:
- 不少同学工作很忙,天天加班,做了很多公司的事情。 但是 不是本团队事情,不是本部门事情,领导不认可,绩效不高
- 做低优先级的任务,无法利他,绩效不高
- 招进来最后变成了随时被裁掉的一些征兆
- 刻意提高工作难度
- 工作中不公平对待
- 制造恶性竞争
- 捧杀