面试题:Redis为何突然变慢了
 次阅读
次阅读
文章目录
把面试官当陪练,在找工作中才会越战越勇
大家好我是小义同学,这是大厂面试拆解——项目实战系列的第4篇文章。
大家都是知道Redis纯内存数据库,处理速度很快,CPU架构,也会影响到 Redis 的性能
本文主要解决的一个问题在 Redis 为什么变慢,如何解决的?
一句话描述:Multi-Core CPU Optimization
- 【what】在多 CPU 插槽服务器上,Redis 的性能取决于 NUMA 配置和进程位置。
- 【how】Redis6.0通过配置文件对不同功能线程绑定不同cpu的物理核,对应命令 taskset 或 numactl,benchmarks 测试在同一个cpu,不同核效果最佳。
- 【why】:
- 为了解决SMP架构(2-4个最佳)下不断增多的CPU Core导致的性能问题,NUMA架构应运而生
- NUMA架构,数据缓存到不同cpu上不同核上 来回切换。
- two different cores of the same CPU to benefit from the L3 cache
| Redis线程类型 | 配置 | 功能描述 | CPU 绑定核心 |
|---|---|---|---|
| 主线程 | server_cpulist 0-7:2 | 事件循环,处理客户端连接和命令调度 | 0, 2, 4, 6 |
| I/O 线程 | server_cpulist 0-7:2 | 解析客户端的读写操作 | 0, 2, 4, 6 |
| BIO 线程 | bio_cpulist 1,3 | 执行耗时的后台任务(关闭文件、AOF fsync) | 1, 3 |
| AOF 重写子进程 | aof_rewrite_cpulist 8-11 | 重写 AOF 文件,优化日志 | 8, 9, 10, 11 |
| BGSAVE 子进程 | bgsave_cpulist 1,10-11 | 保存内存快照到磁盘(RDB 文件) | 1, 10, 11 |
下面是分析过程
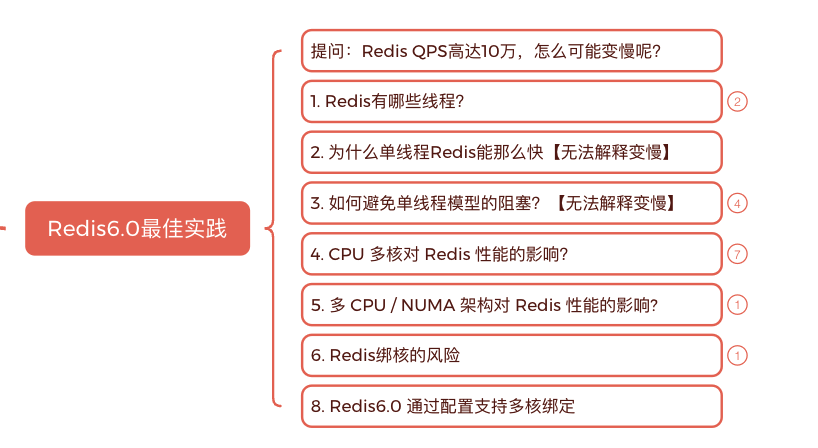
你会疑问:Redis大家都说它快,什么情况变慢
- Redis 作为优秀的内存数据库,其拥有非常高的性能,单个实例的 OPS 能够达到 10W 左右
- Redis 事件循环基于 epoll/kqueue, 具有相当强的可扩展性。 Redis 已在超过 60,000 个连接的情况下进行了基准测试, 并且仍然能够维持 50,000 q/s 的吞吐量。
怎么会变慢呢?
一、确定Redis是否真的变慢了
1. 排查思路1: 看延迟
- redis-cli 命令提供了–intrinsic-latency 120 选项, 该命令打印 120 秒内监测到的最大延迟,
|
|
- 输出结果显示,60 秒内的最大响应延迟为 119 微秒(0.119 毫秒)
观察到的 Redis 运行时延迟是其基线性能的 2 倍及以上,就可以认定 Redis 变慢了
2. 排除思路:检查 网络是否瓶颈(排除不是)
- 一般要求:Redis 中,以 100000 q/s 的速率运行 4 KB 字符串的基准测试,实际将消耗 3.2 Gbit/s 的带宽,这很可能适合 10 Gbit/s 的链路。 ```shell 工具提供了服务器和客户端模式,来在两个主机之间执行网络吞吐量测试。
在服务端运行iperf,以在本机端口12345上启用iperf
输入命令iperf –s –p 12345 –i 1 –M
iperf: option requires an argument – M
iperf -c server IP -p 12345 -i 1 -t 10 -w 20K
Client connecting to 172.20.0.113, TCP port 12345 TCP window size: 40.0 KByte (WARNING: requested 20.0 KByte)
[ 3] local 172.20.0.114 port 56796 connected with 172.20.0.113 port 12345 [ ID] Interval Transfer Bandwidth [ 3] 0.0- 1.0 sec 614 MBytes 5.15 Gbits/sec [ 3] 1.0- 2.0 sec 622 MBytes 5.21 Gbits/sec [ 3] 2.0- 3.0 sec 646 MBytes 5.42 Gbits/sec [ 3] 3.0- 4.0 sec 644 MBytes 5.40 Gbits/sec [ 3] 4.0- 5.0 sec 651 MBytes 5.46 Gbits/sec [ 3] 5.0- 6.0 sec 652 MBytes 5.47 Gbits/sec [ 3] 6.0- 7.0 sec 669 MBytes 5.61 Gbits/sec [ 3] 7.0- 8.0 sec 670 MBytes 5.62 Gbits/sec [ 3] 8.0- 9.0 sec 667 MBytes 5.59 Gbits/sec [ 3] 9.0-10.0 sec 668 MBytes 5.60 Gbits/sec 带宽满足
|
|
2.1 代码如何实现的
|
|
2.2 如何验证绑定生效
查看 NUMA 与核心分布
|
|
确认核心 8–11 属于同一 NUMA 节点,以保证内存本地性。
触发 AOF 重写 redis 127.0.0.1:6379> BGREWRITEAOF Background append only file rewriting started
查找子进程 PID
|
|
三、 为什么多核多Cpu会影响Redis的性能
直接看结果

✅ 什么是尾延迟?
假设你在点外卖,前 99 次下单都只用了 1 秒,但第 100 次突然用了 10 秒。虽然大多数时候都很快,但偶尔慢一下,这“偶尔的慢”就是所谓的尾延迟(Tail Latency)。
假如 Redis 一共处理了 10000 个请求:
- 9990 个用了 1 毫秒
- 10 个用了 30 毫秒
那我们说:
- 平均延迟 ≈ 1.03 毫秒(听起来很快)
- P99 延迟 ≈ 30 毫秒(最慢的 1% 就是那几个拖后腿的) 在技术里,常用 P99
- P99 延迟 = 99% 的请求比它快,它是最慢的 1%
✅ 什么是NUMA?
Non-uniform memory access (NUMA) is a [computer memory] design used in [multiprocessing], where the memory access time depends on the memory location relative to the processor.
非均匀内存访问 ( NUMA ) 是一种用于多处理系统的计算机内存设计,其内存访问时间取决于内存相对于处理器的位置
✅ 发生了什么,为什么程序偶尔慢的情况
从网卡读取请求,到处理请求举例,看数据的位置
- 曾经做过测试,和访问 CPU Socket 本地内存相比,跨 CPU Socket 的内存访问延迟增加了 18%,这自然会导致 Redis 处理请求的延迟增加 哪里做验证【来自Redis核心技术与实战】
|
|
-
测试数据:

-
绑定方式与收益:相同cpu相同的核 <不同的的cpu,不同的核 < 相同的cpu
-
two different cores of the same CPU to benefit from the L3 cache
使用 Swap 会导致 Redis 性能下降
- swap 除非磁盘IO
- swap 触发后影响的是 Redis 主 IO 线程,这会极大地增加 Redis 的响应时间
- 一旦发生内存 swap,最直接的解决方法就是增加机器内存
感谢阅读,如果你觉得这节课对你有一些启发,也欢迎把它分享给你的朋友。
参考
-
Is Your Redis Slowing Down? – Part 1: Determining Slowdown
-
Is Your Redis Slowing Down? – Part 2: Optimizing and Improving Performance
- Redis核心技术与实战
- https://redis.io/docs/latest/operate/oss_and_stack/management/optimization/benchmarks/
- https://gist.github.com/neomantra/3c9b89887d19be6fa5708bf4017c0ecd
坚持思考,方向比努力更重要。
关注公共号:后端开发成长指南 回复电子书
如果更进一步交流 添加 微信:wang_cyi

我是小王同学,
阅读对象(也是我正在做事情)
1. 目标:冲击大厂,拿百万年薪
- 想进入一线大厂,但在C++学习和应用上存在瓶颈,渴望跨越最后一道坎。
2. 现状:缺乏实战,渴望提升动手能力
-
公司的项目不会重构,没有重新设计的机会,导致难以深入理解需求。
-
想通过阅读优秀的源码,提高代码能力,从"不会写"到"敢写",提升C++编程自信。
-
需要掌握高效学习和实践的方法,弥补缺乏实战经验的短板。
3. 价值:成为优秀完成任务,成为团队、公司都认可的核心骨干。
优秀地完成任务= 高效能 + 高质量 + 可持续 + 可度量
错误示范:
- 不少同学工作很忙,天天加班,做了很多公司的事情。 但是 不是本团队事情,不是本部门事情,领导不认可,绩效不高
- 做低优先级的任务,无法利他,绩效不高
- 招进来最后变成了随时被裁掉的一些征兆
- 刻意提高工作难度
- 工作中不公平对待
- 制造恶性竞争
- 捧杀