【注意】最后更新于 August 7, 2024,文中内容可能已过时,请谨慎使用。
点击蓝色关注。
文末有福利,先到先得
大厂面试手撸算法题已经是标配 ,
本文描述从青铜到王者不同阶段如何理解LRU缓
如果有更多疑问请留言
历史题目:
Ceph MDS 路径解析场景:
输入:/mnt/data/project1/report.docx
输出:逐级路径 [“mnt”, “data”, “project1”, “report.docx”]
一、剧情回顾
面试官: 你能手写个LRU缓存吗?
小义: LRU是什么东西?(一脸懵逼状)
面试官: LRU全称Least Recently Used(最近最少使用),用来淘汰不常用数据,保留热点数据。
写了10分钟,然而只写了个get和put方法体,里面逻辑实在不知道咋写。`
面试官: 今天的面试先到这吧,有其他面试我们会再联系你。
我信你个鬼,你个糟老头子坏滴很,还联系啥,凉凉了。
别担心,再有人问你LRU,就把这篇文章丢给他,保证当场发offer。

二、 倔强青铜: 会做Leetcode原题
面试官可能就直接拿出 LeetCode 上原题让你来做的
https://leetcode.cn/problems/lru-cache-lcci/description/
运用你所掌握的数据结构,设计和实现一个 LRU(最近最少使用)缓存机制。它应该支持以下操作:
- 获取数据 get(key):如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
- 写入数据 put(key, value) :如果密钥不存在,则写入其数据值。
- 当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
1
2
3
4
5
6
7
8
9
10
11
12
|
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
|
分析上面的操作过程,要让 put 和 get 方法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:
1、显然 cache 中的元素必须有时序,以区分最近使用的和久未使用的数据,当容量满了之后要删除最久未使用的那个元素腾位置。
2、我们要在 cache 中快速找某个 key 是否已存在并得到对应的 val;
3、每次访问 cache 中的某个 key,需要将这个元素变为最近使用的,也就是说 cache 要支持在任意位置快速插入和删除元素。
那么,什么数据结构同时符合上述条件呢?
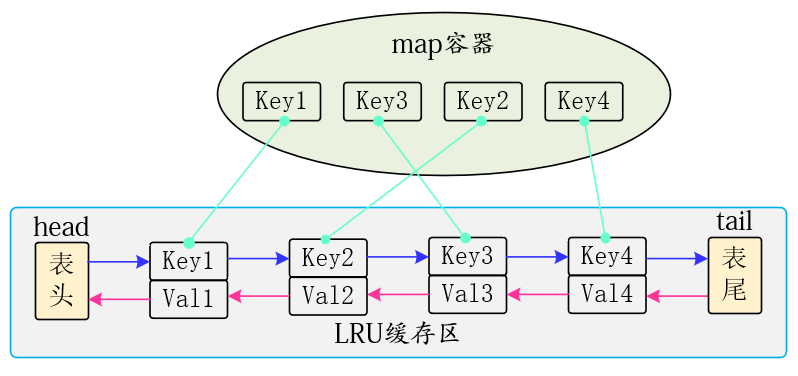
常用的数据结构有数组、链表、栈、队列,考虑到要从两端操作元素,就不能使用栈和队列。
每次使用一个元素,都要把这个元素移到末尾,包含一次删除和一次添加操作,使用数组会有大量的拷贝操作,不适合。
又考虑到删除一个元素,要把这个元素的前一个节点指向下一个节点,使用双链接最合适。
链表不适合查询,因为每次都要遍历所有元素,可以和HashMap配合使用。
双链表 + HashMap
put 新节点时应先淘汰,再插入
正确顺序:
- 如果 key 存在,更新值并移到头部,直接返回。
- 如果 key 不存在,且容量已满,先淘汰尾部节点(ptail->prev)。
- 插入新节点到头部,size++。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
|
class LRUCache
{
//01-定义数据结构
private:
int MaxCapacity; // 缓冲区的最大容量
int size; // 缓冲区使用的大小
struct DoubleListNode {
int key;
int value;
DoubleListNode* prev;
DoubleListNode* next;
DoubleListNode(int k,int v) : key(k), value(v), prev(nullptr), next(nullptr) {}
};
map<int,DoubleListNode*> cache; // 缓存,key为数据的key,value为双向链表节点
DoubleListNode* phead; // 头结点
DoubleListNode* ptail; // 尾结点
//02 定义算法
public:
LRUCache(int capacity)
{
MaxCapacity = capacity;
size = 0;
phead =new DoubleListNode(0, 0); // 初始化头结点
ptail = new DoubleListNode(0, 0); // 初始化尾结点
phead->next =ptail; // 头结点的下一个指向尾结点
ptail->prev =phead; // 尾结点的前一个指向头结点
//这样设计好处,不用判断是否空节点
}
int get(int key)
{
if (cache.find(key) == cache.end())
{
return -1; // 如果key不存在,返回-1
} else {
DoubleListNode *node = cache[key]; // 获取节点
deleteNode(node);
insertToHead(node);
return node->value; // 返回节点的值
} //思考如何避免频繁的移动节点
}
void put(int key, int value) {
//判断key存在
if (cache.find(key) != cache.end()) {
DoubleListNode *node = cache[key]; // 获取节点
node->value = value; // 更新节点的值
deleteNode(node);
insertToHead(node);
return ;
}
//超过最大容量,删除不经常使用的节点
//链表最后最后一个节点是不经常使用的节点
if (size >= MaxCapacity) {
DoubleListNode *pcur = ptail->prev; // 获取尾结点的前一个节点
deleteNode(pcur);
cache.erase(pcur->key);
delete pcur; // 删除节点
size--; // 缓冲区大小减1
}
//插入一个元素
DoubleListNode *ptemp = new DoubleListNode(key,value);
cache[key] = ptemp; // 将新节点加入缓存
//将新节点插入到头结点后面
insertToHead(ptemp);
size++; // 缓冲区大小加1
}
private:
void deleteNode(DoubleListNode* cur) {
if (nullptr == cur) return;
cur->prev->next = cur->next;
cur->next->prev = cur->prev;
// cache.erase(cur->key); // 从缓存中删除
// delete cur; // 删除节点
// size--; // 缓冲区大小减1
}
void insertToHead(DoubleListNode* cur) {
cur->next = phead->next; // 新节点的下一个指向头结点的下一个
phead->next->prev = cur; // 头结点的下一个的前一个指向新节点
phead->next = cur; // 头结点的下一个指向新
cur->prev = phead; // 新节点的前一个指向头结点
// size++; // 缓冲区大小加1
}
};
|
三、荣耀黄金:使用STL 容器(提供武器)实现
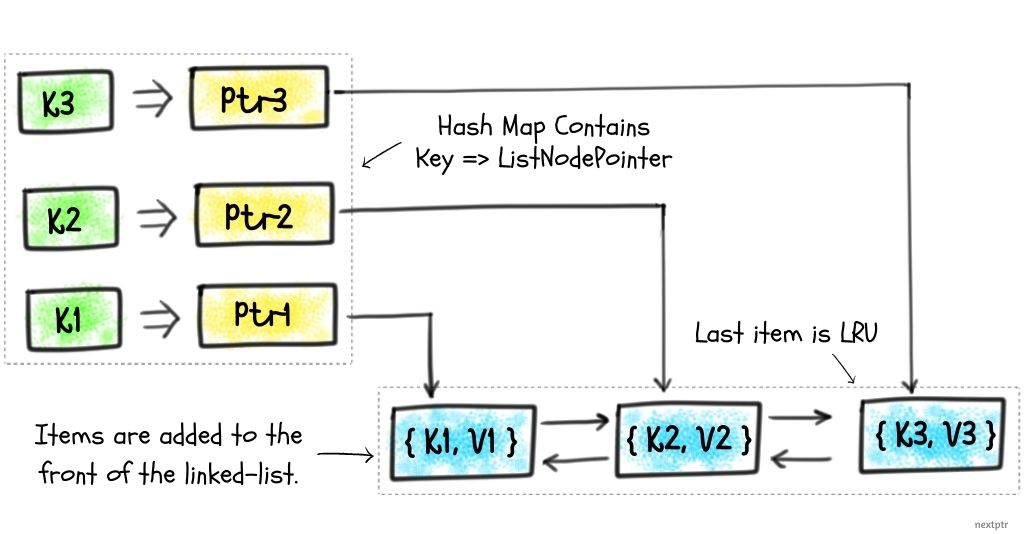 参考:# 用std::list的splice接口来实现LRU Cache
参考:# 用std::list的splice接口来实现LRU Cache
推荐用 std::list 作为双向链表,std::unordered_map 作为哈希表。
std::list<pair<int,int>> 存储缓存内容,头部是最新,尾部是最久未用。std::unordered_map<int, list<pair<int,int>>::iterator> 存储 key 到 list 节点的映射。
提示:java中的LinkedList 底层是基于双向链表实现的
这样可以避免手写链表节点和指针操作,代码更简洁安全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
#include <list>
#include <unordered_map>
using namespace std;
class LRUCache {
int capacity;
list<pair<int, int>> cache; // {key, value}
unordered_map<int, list<pair<int, int>>::iterator> map;
// key -> list迭代器
//https://en.cppreference.com/w/cpp/container/list.html
//std::list 是一个容器,
//它支持从容器中的任何位置插入和删除元素的恒定时间。
//不支持快速随机访问。它通常实现为双向链表
public:
LRUCache(int capacity) : capacity(capacity) {}
int get(int key) {
auto it = map.find(key);
if (it == map.end()) return -1;
// 移动到头部
cache.splice(cache.begin(), cache, it->second);
return it->second->second;
}
void put(int key, int value) {
auto it = map.find(key);
if (it != map.end()) {
// 更新并移到头部
it->second->second = value;
cache.splice(cache.begin(), cache, it->second);
} else {
if (cache.size() == capacity) {
// 淘汰尾部
int oldKey = cache.back().first;
cache.pop_back();
map.erase(oldKey);
}
cache.emplace_front(key, value);
map[key] = cache.begin();
}
}
};
https://www.nextptr.com/tutorial/ta1576645374/stdlist-splice-for-implementing-lru-cache
https://leetcode.cn/problems/lru-cache-lcci/solutions/3617249/clrushi-xian-by-ooo-4h-5qff/
|
| 场景 |
splice 优点 |
| 高效合并两个链表 |
不需要拷贝元素 |
| 实现排序算法(归并) |
直接移动元素 |
| 自定义容器缓存(LRU) |
把元素移到前面/后面 |
| 实现 list 中元素的重新排序 |
常数时间插入 |
四、最强王者:遇到并发怎么处理
在面试者回答出黄金级的问题了以后,
面试官可能会继续追问一个更高级的问题。
“如何实现一个高并发且线程安全的 LRU 呢?
误区:上来直接考虑并发问题,不是最佳选择,会让自己陷入思维上误区,因为数据结构和算法没有开始设计
- 更主要的自己在白板上写不出来。
std::list 和 unordered_map 都不是线程安全的
1
2
3
4
5
6
7
8
9
10
|
struct Node {
Key key;
Value value;
std::atomic<Node*> prev, next;
std::atomic<bool> valid;
};
std::atomic<Node*> head, tail;
std::unordered_map<Key, Node*> index; // 需要替换成 lock-free map
|
- 直接使用 Facebook 的 CacheLib 或 Memcached slab allocator。
五、荣耀王者:理论和实际的差距
5.1 Redis
参考:Redis 源码剖析与实战 深入源码底层实现,轻松通关 Redis 面试
为什么LRU算法原理和代码实现不一样

而具体来说,LRU 算法会把链表的头部和尾部分别设置为 MRU 端和 LRU 端。
- 其中,MRU 是 Most Recently Used 的缩写,
- MRU 端表示这里的数据是刚被访问的。而 LRU 端则表示,这里的数据是最近最少访问的数据。
介绍过LRU 算法的执行过程,这里,我们来简要回顾下。LRU 算法的执行,可以分成三种情况来掌握。
- 情况一:当有新数据插入时,LRU 算法会把该数据插入到链表头部,同时把原来链表头部的数据及其之后的数据,都向尾部移动一位。
- 情况二:当有数据刚被访问了一次之后,LRU 算法就会把该数据从它在链表中的当前位置,移动到链表头部。同时,把从链表头部到它当前位置的其他数据,都向尾部移动一位。
- 情况三:当链表长度无法再容纳更多数据时,若再有新数据插入,LRU 算法就会去除链表尾部的数据,这也相当于将数据从缓存中淘汰掉。
下图就展示了 LRU 算法执行过程的第二种情况,你可以看下
其中,链表长度为 5,从链表头部到尾部保存的数据分别是 5,33,9,10,8。
假设数据 9 被访问了一次,那么 9 就会被移动到链表头部,
同时,数据 5 和 33 都要向链表尾部移动一位。
提问:Redis 采用什么数据结构存储数据?
Redis 的 LRU(Least Recently Used,最近最少使用)淘汰策略主要采用了以下数据结构:
双向链表(Linked List)
用于维护键的访问顺序。最近访问的元素会被移动到链表头部,最久未访问的元素在链表尾部,便于快速淘汰。
- ==Redis LRU 淘汰没有用全局双向链表,而是用对象的
lru 字段 + 哈希表采样实现近似 LRU==。
- 哈希表(Hash Table)
用于存储实际的键值对,实现 O(1) 的查找和插入操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// ...existing code...
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
// ...existing code...
} redisDb;
C 语言没有这种数据结构, 需要自定义
typedef struct dictEntry {
void *key; // 指向 key 的指针(通常是 sds 类型)
void *val; // 指向 value 的指针
struct dictEntry *next; // 用于处理哈希冲突的链表指针
} dictEntry;
|
- 所有数据(无论什么类型)都是存储在一个全局 dict 中,这个 dict 就是 Redis 的主字典结构
redisDb.dict。
- 抽样算法(Sampling)
为了性能,Redis 并不是严格意义上的全局 LRU,而是采用了“近似 LRU”策略。它会从一定数量的键中随机抽样,选择其中最久未使用的进行淘汰
每个键值对象(robj)都包含一个 lru 字段,用于记录上次访问时间戳(抽象为 LRU 时钟):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
struct redisObject
{
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
unsigned iskvobj : 1; /* 1 if this struct serves as a kvobj base */
unsigned expirable : 1; /* 1 if this key has expiration time attached.
* If set, then this object is of type kvobj */
unsigned refcount : OBJ_REFCOUNT_BITS;
void *ptr;
};
|
提问: Redis 没有采用双链链表存储key,怎么选出最久未用的淘汰
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 伪代码,实际实现更复杂
dictEntry *dictGetFairRandomKey(dict *d) {
dictEntry *entry = NULL;
int tries = 100; // 最多尝试次数
while (tries--) {
// 随机选一个哈希桶
unsigned long idx = random() % d->ht[0].size;
entry = d->ht[0].table[idx];
if (entry) break;
}
// 如果没采到,fallback 到 dictGetRandomKey
if (!entry) return dictGetRandomKey(d);
// 桶内有冲突链表,随机选一个
int listlen = 0;
dictEntry *e = entry;
while (e) { listlen++; e = e->next; }
int skip = random() % listlen;
e = entry;
while (skip--) e = e->next;
return e;
}
|
dictGetFairRandomKey
通过多次采样和桶内随机,
保证哈希表中每个 key 被选中的概率尽量均匀,
适合 LRU/LFU 采样和 RANDOMKEY 等场景
提问:为什么不需要加锁?
| 问题 |
Redis 设计 |
| 多客户端并发访问 |
串行处理,单线程安全 |
| rehash 是否加锁 |
不加传统锁,靠事件驱动串行保证 |
| 如何保证一致性 |
查询/写时查两个表,rehashidx 控制进度 |
| 数据会不会丢? |
不会,迁移桶时所有 entry 被完整转移 |
|
|
5.2 Mysql
对比传统 LRU vs InnoDB LRU
| 维度 |
传统 LRU |
InnoDB 改进版 LRU |
| 数据结构 |
双向链表 + 哈希表 |
增加 Old/Young 区分 + 时间戳字段 |
| 新页插入位置 |
链表头 |
插入 Old 区头 |
| 热点访问处理 |
移至链表头 |
Young 区头或满足晋升条件后移动 |
| 淘汰策略 |
链表尾部淘汰 |
仅淘汰 Old 区尾,大页扫描不影响 Young |
| 支持预读避免污染 |
不支持(直接入链表头) |
支持(插入 Old 区,可延迟淘汰) |
提问:你的业务有大表顺序扫描的操作吗? → 会不会出现命中率骤跌现象?
以下用一个完整流程拆解一轮访问与淘汰:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
1. 系统启动
→ Buffer Pool 初始化
→ LRU 链表为空,old/young 未构建成功
2. 访问数据页 P
→ 不存在缓冲中,加载到内存
→ 插入 Old 区头
→ LRU 链表增长
3. 重复大表扫描
→ 访问各页,均插到 Old 区头
→ 1 秒内访问同页多次也不晋升
→ LRU 震荡在 Old 区
4. 内存满了,触发淘汰
→ 淘汰 Old 区尾部页
→ Hot 页留在 Young,未被影响
5. 热点访问重现
→ 访问 Young 或晋升 Old 页
→ Hot 页集中,系统恢复响应率
|
可以看出,热点与扫描区被明显隔离,互不干扰。
5.3 levelDB
LevelDB 使用了一种基于 LRUCache 的缓存机制,用于缓存:
- 已打开的 sstable 文件对象和相关元数据;
- sstable 中的 dataBlock 的内容。
这种缓存机制使得对热数据的读取尽量在 cache 中命中,避免 IO 调用。
Leveldb 实现了key-value形式的缓存,淘汰算法是LRU。
实现代码在 leveldb/util/cache.cc,一共400行,非常简洁
提问:LevelDB是如何应用这个数据结构的。

LevelDB的LRUCache设计有4个数据结构,是依次递进的关系,分别是:
- LRUHandle(LRU节点,也就是LRUNode)
- HandleTable(哈希表)
- LRUCache(关键,缓存接口标准和实现)
- ShardedLRUCache(用于提高并发效率)
LRUHandle 是一个双向循环链表,存储缓存中的 entry,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
struct LRUHandle {
// 存储的 value 对象的指针,可以存储任意类型的值
void* value;
// 当引用计数 `refs` 降为 0 时的清理函数
void (*deleter)(const Slice&, void* value);
// 哈希表通过链地址法解决哈希冲突,发生哈希冲突时指向下一个 entry
LRUHandle* next_hash;
// LRU 链表双向指针
LRUHandle* next;
LRUHandle* prev;
// 分配的可以消耗的内存量
size_t charge;
// key 的字节数
size_t key_length;
// entry 是否存在缓存中
bool in_cache;
// 引用计数,记录 entry 被不同缓存的引用,用于 entry 删除
uint32_t refs;
// `key()` 对应的哈希,用于快速分区和比较
uint32_t hash;
// 存储 key 的开始地址,结合 `key_length` 获取真正的 key
// GCC 支持 C99 标准,允许定义 char key_data[] 这样的柔性数组(Flexible Array)。
// C++ 标准并不支持柔性数组的实现,这里定义为 key_data[1],这也是 c++ 中的标准做法。
char key_data[1];
Slice key() const {
// 只有当当前节点是空链表头时,`next` 才会等于 `this`
// 链表是循环双向链表,空链表的头节点 next 和 prev 都指向自己构成环
// 链表头是冗余的 handle,不存储数据,只利用它的 next 和 prev
assert(next != this);
return Slice(key_data, key_length);
}
};
参考:https://blog.mrcroxx.com/posts/code-reading/leveldb-made-simple/7-cache/
|
5.4 Ceph
Ceph 的 LRU(Least Recently Used,最近最少使用)缓存管理在 lru.h中
提问:采用什么数据结构存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
LRU算法的实现
class LUR
{
using LRUList = xlist<LRUObject*>;
LRUList top, bottom, pintail; //定义三个链表,而不是一个链表
}
`top`链表代表最近访问的对象链表。当缓存对象被插入/访问时,这个对象会被放到`top`链表的头部。
`bottom`链表代表较早之前访问过的对象列表。当`top`链表满了或达到某这阈值,就会把`top`链表尾部的对象添加到`bottom`链表的头部。从缓存中淘汰对象时,从`bottom`尾部开始淘汰。
// insert at top of lru
void lru_insert_top(LRUObject *o)
{
o->lru = this; //class LUR
top.push_front(&o->lru_link);
}
|
提问5:xlist<LRUObject*>::item作用是什么
参考:第三章节设计
1. 节点信息和对象解耦 链表节点(xlist<LRUObject*>::item)需要保存前驱、后继指针、所属链表等信息。
2. 如果直接用对象地址(如 LRUObject*),就无法在对象本身里存储这些链表管理信息,链表操作就不方便。
3. 支持多链表挂载 一个对象可以有多个 item 成员,挂载到不同的链表(比如 Ceph 的 top/bottom/pintail)。 如果只用对象地址,只能挂在一个链表上,无法支持多链表结构。
4. 操作安全和高效 lru_link 作为成员变量,生命周期和对象一致,不需要额外分配内存,避免悬挂指针和内存泄漏。 链表操作(插入、删除、移动)只需操作 lru_link,效率高且安全。
LRUObject
所有需要缓存的对象都需继承自 LRUObject,这样可以被 LRU 管理。
class MyCacheEntry : public LRUObject
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class LRUObject {
public:
friend class LRU;
private:
class LRU *lru; // LRU算法的真正实现者
xlist<LRUObject *>::item lru_link; // 记录自己在双向链表里的位置,移动或删除对象时,操作会很快
bool lru_pinned;
inline LRUObject::~LRUObject()
{
if (lru) {
lru->lru_remove(this);
}
}//# c++ new(this)
};
|
提问: 如何理解下面这句话
只要你的对象继承了 LRUObject,
就能被 LRU 缓存自动管理,
无需自己手动维护链表节点和指针,
使用起来非常方便和安全。
- 高性能:
采用链表结构,插入、移动、删除操作复杂度为 O(1),适合高并发场景。
- 灵活性:
支持多种 touch 策略和分层淘汰,适应不同业务冷热数据分布。
- 可扩展性:
通过继承 LRUObject,任何类型对象都可被 LRU 管理,易于集成到 Ceph 各类缓存场景(如元数据、对象缓存等)。
- 线程安全:
LRU 本身不加锁,线程安全需由上层调用者保证,便于灵活集成到不同并发模型。
总结
- Redis LRU:每个对象用
lru 字段记录访问时间,所有键值对存储在哈希表(dict)中,淘汰时通过采样若干 key 的 lru 字段近似实现 LRU,无全局链表。
- LevelDB LRU:通常用 C++ STL 的
std::list(双向链表)+ std::unordered_map(哈希表)实现,链表维护访问顺序,哈希表 O(1) 查找,严格 LRU。
- LeetCode 刷题 LRU:经典实现也是“哈希表+双向链表”,链表维护顺序,哈希表加速查找和插入,常见于 LRU Cache 题目。
最动人的作品,为自己而写,刚刚好打动别人
我在寻找一位积极上进的小伙伴,
一起参与神奇早起 30 天改变人生计划,做一个伟大产品取悦自己,不妨试试
1️⃣关注公众号:后端开发成长指南(回复"面经"获取)获取过去我全部面试录音和面试复盘

2️⃣ 感兴趣的读者可以通过公众号获取老王的联系方式。
加入我的技术交流群Offer 来碗里 (回复“面经”获取),一起抱团取暖
本群目标是:
抬头看天:走暗路、耕瘦田、进窄门、见微光
- 不要给自己这样假设:别人完成就等着自己完成了,大家都在一个集团,一个公司,分工不同,不,这个懒惰表现,这个逃避问题表现。
- 别人不这么假设,至少本月绩效上不会写成自己的,至少晋升不是你,裁员淘汰就是你。
- 目标:在跨越最后一道坎,拿百万年薪,进大厂。
低头走路:一次专注做好一个小事
- 不扫一屋 何以扫天下。
- 让自己早睡,早起,锻炼身体,刷牙保持个人卫生,多喝水 ,表达清楚 基本事情做好。
