从零开发分布式文件系统(一) :100G读写带宽,百万IO请求文件系统怎么实现的

文章目录
【注意】最后更新于 August 7, 2024,文中内容可能已过时,请谨慎使用。
https://wnso49yyot.feishu.cn/base/Wi37bwBTiaCpEZsFxavckkV5nbb?table=tblPUqR3ZoqKKLNW&view=vew40mV0G2
书接上回:
从零实现分布式文件系统(二) 如何在不升级硬件的前提下,小文件并发读写性能提升十倍
*C++周刊系统设篇 目标:
-
不是让你成为C++专家, 而是让你成为C++面试专家。
-
不是让你疯狂学习新知识, 而是帮你重新整理已有知识, 让你的能力与面试题精准对齐。。
知识地图:
- 操作系统–文件子系统–AI时时代分布式文件系统
- 计划安排:
本期任务:
- 从零开发分布式文件系统(一) :100G读写带宽,百万IO请求文件系统怎么实现的?
- 思考1:可扩展哈希(Extendible Hashing)与普通的哈希有什么区别?
- 思考2:对象和条带有什么区别?
一页 ppt 汇报:
- 方法: 竞标分析 要求:准确说清楚 文件系统系统 具体公司 具体机型 具体指标
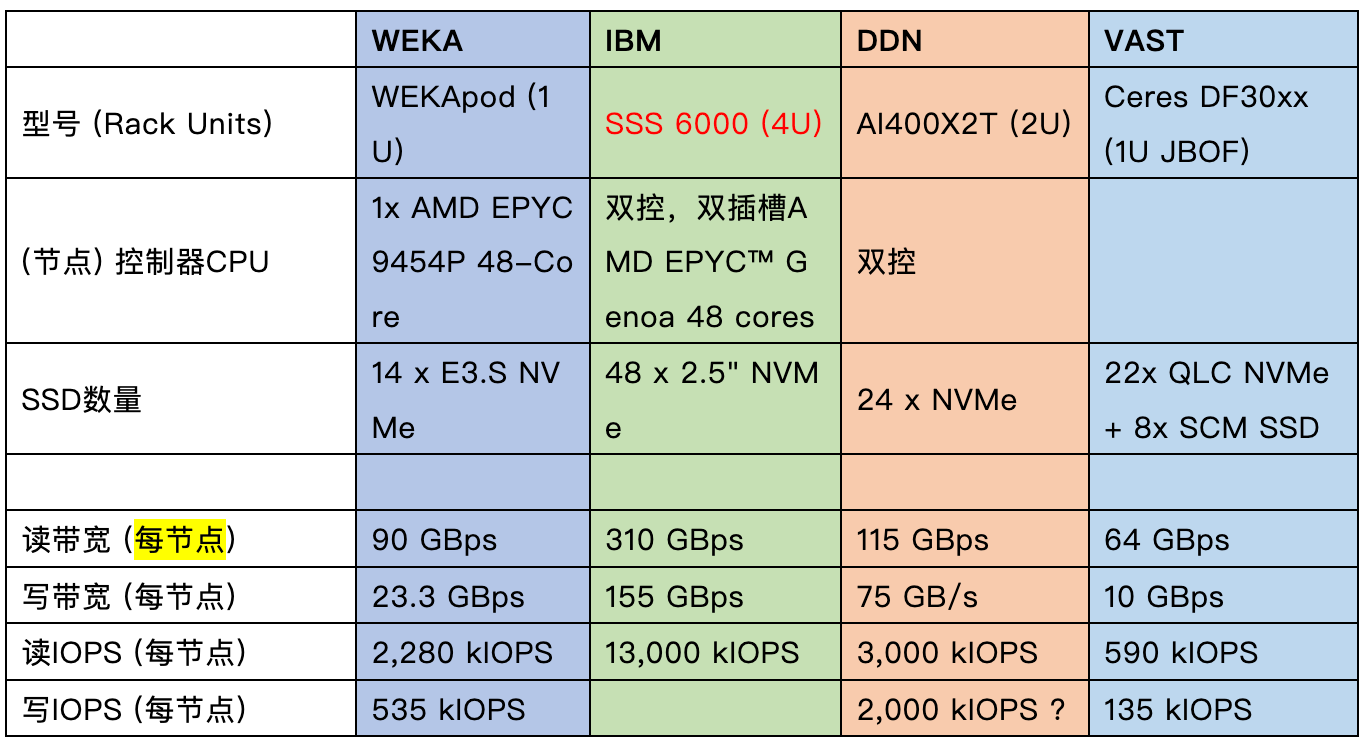
| 类型 | 厂商 | 文件系统 | 机型 | 关键配置 | 单节点聚合带宽 |
|---|---|---|---|---|---|
| 读 | |||||
| 全闪 | DDN | Lustre | SFA200NVX2E | 双控双路,24×NVMe SSD | 48 GB/s |
| IBM | GPFS (GNR模式) | ESS 3500 | 双控双路,24×NVMe SSD | 80 GB/s | |
| 浪潮 | GPFS (ECE模式) | HN12 | 8×NVMe SSD | 21.71 GB/s | |
| 混闪 | DDN | Lustre | SFA7990X | 1×SFA7990X控制器 + 1×4U90磁盘柜 | 20 GB/s |
| IBM | GPFS (GNR模式) | ESS 3500 | 1×ESS 3500控制器 + 4×4U102扩展柜 | 43.2 GB/s | |
| 浪潮 | GPFS (ECE模式) | H60 | 60×HDD(无SSD缓存) | 5.65 GB/s | |
- 结论:
- 带宽王者:IBM ESS 3500 全闪以 80 GB/s 读带宽位居榜首(需 200Gb 网络支持)。
- 混闪均衡:DDN SFA7990X 读写对称(20 GB/s),适合平衡型负载。
- 低成本方案:浪潮 H60 纯 HDD 配置成本最低,但性能仅为混闪方案的 1/4。
一、 DDN公司的Lustre文件系统
1. 性能数据汇总:
| 机型 | 类型 | 厂商 | 文件系统 | 单节点聚合带宽 | 元数据OPS | 关键限制与适配场景 | 核心优势 |
|---|---|---|---|---|---|---|---|
| SFA7990X | 混闪 | DDN | Lustre | 读:20 GB/s 写:20 GB/s | 20万 OPS | 必须配 SSD 元数据盘 适用:归档、冷数据处理 | 高容量性价比、70万 IOPS |
| SFA200NVX2E | 全闪 | DDN | Lustre | 读:48 GB/s 写:38 GB/s | 200万 OPS | 单网卡带宽≤25GB/s 适用:AI推理、中型 HPC | 极致低延迟、高吞吐 |
| SFA400NVX2E | 旗舰全闪 | DDN | EXAScaler | 读:≥80 GB/s 写:56–72 GB/s | ≥1.2M | 需 200Gb EDR 双网卡聚合 适用:AI训练、超算 | 厂商白皮书 + 行业测试 |
参考:陈道碧_DDN 持续支持 Lustre 社区发展
2. DDN 全闪存存储机型对比表
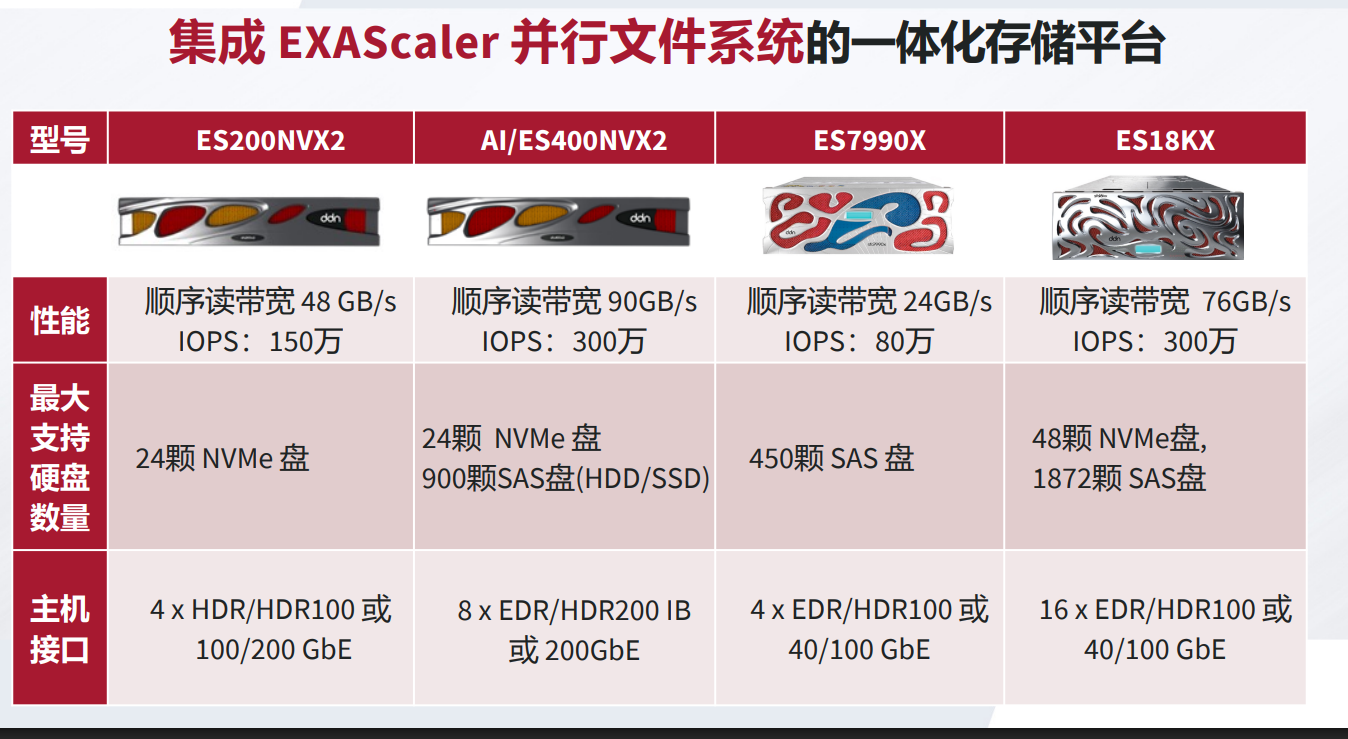
| 配置项 | ES200NVX2 机型 | ES400NVX2 机型 | 性能差异 |
|---|---|---|---|
| 架构设计 | 双控双路 | 双控四路 | CPU 性能翻倍 ↑↑ |
| 处理器 | 2× 第三代英特尔®至强®可扩展处理器 | 4× 第三代英特尔®至强®可扩展处理器 | 计算密度 +100% |
| 主机端口 | 4× HDR/HDR100 或 200/100GbE | 8× HDR/HDR100 或 200/100GbE | 网络带宽翻倍 ↑↑ |
| 驱动器支持 | 24× 2.5" 双端口热插拔 NVMe SSD | 24× 2.5" 双端口 NVMe SSD + SAS-4扩展(支持900块HDD/SSD) | 容量扩展能力 ↑↑ |
| 顺序读带宽 🔥 | 48 GB/s | 90 GB/s | +87% |
| 顺序写带宽 ⚡ | 38 GB/s | 65 GB/s | +71% |
| 随机IOPS 💥 | 150万 | 300万 | +100% |
| RAID特性 | 解耦式RAID (DCR): 支持 RAID 6/5/1 多种纠删码 | 同左 | 相同 |
| 文件系统型号 | EXAScaler ES200NVX2 | EXAScaler ES400NVX2 / AI400X2(AI专用优化) | 场景适配扩展 ↑ |
SFA200NVX2E机型
-
24×NVMe SSD(单PCIe 5.0SSD百万ops, 实际10–14 GB/s)
-
200Gb InfiniBand(单网卡最多25GB/s带宽)
-

- 追求极致性能 → ES400NVX2:
四路CPU + 8×200Gb端口 + 300万IOPS,适配超90GB/s带宽场景。 - 性价比之选 → ES200NVX2:
双路CPU + 全闪配置,满足中等规模HPC需求(≤50GB/s)。 - AI专属优化 → AI400X2型号:
深度集成NVIDIA GPUDirect,减少数据搬移延迟,提速训练效率。
3 符合常识吗?
关键数据一致性验证
| 参数 | SFA200NVX2E(原始值) | SFA400NVX2E(升级验证) | 逻辑关系 |
|---|---|---|---|
| 单NVMe SSD带宽 | 2 GB/s (读) ×24盘 | PCIe 5.0单盘≈14 GB/s | ✅ 合理 |
| 总读带宽 | 48 GB/s | ≥80 GB/s | ✅ 翻倍提升 |
| 网卡限制 vs 需求带宽 | 25 GB/s « 48 GB/s | 50 GB/s ≥ 80 GB/s* | SFA400需多链路聚合 |
注:SFA400NVX2E 的80GB/s带宽需依赖多网卡负载均衡(如4×200Gb EDR = 100GB/s理论值)。
4. Lustre文件系统架构图
- Lustre 是一款专为高性能计算(HPC)环境设计的并行分布式文件系统,最初在美国政府资助下,由多个国家实验室联合开发,旨在支持大规模科学研究和工程计算任务。当前,Lustre 的主要开发与维护由 DDN(DataDirect Networks) 负责,广泛应用于超算中心、科研机构及企业级 HPC 集群中
- Lustre 为扩展性和性能目的设计。它的存储容量和聚合性能随着服务器增加不断扩展,并且提供给并行应用的性能可以随着客户端的增加而增长 【疑问】
为什么Lustre文件系统 性能随着 服务器增加不断扩展,
客户端的增加而增长?这个不符合常理, 例如单机下无能无限增加线程个数?
|
|
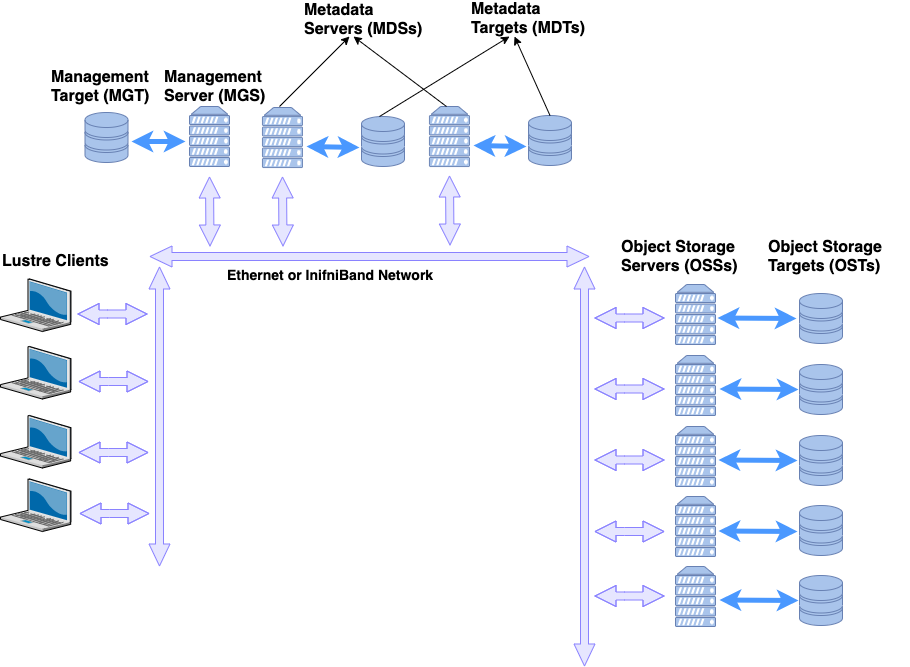
| 组件 | 功能与说明 |
|---|---|
| Client | 提供用户访问接口,支持 POSIX 文件语义,与 OSS/MDS 通信 |
| LNet | 网络通信层,支持高吞吐与 RDMA,连接所有 Lustre 架构节点 |
| MGS + MGT | 系统配置中心,负责节点启动和配置同步 |
| MDS + MDT | 管理文件系统命名空间和元数据,只在打开等元操作时被访问 |
| OSS + OST | 存储实际文件数据,处理高并发 I/O,并可扩展横向容量与性能 |
疑问:MDS 与 MDT、OSS 与 OST:关系总结
| 层面 | 管理者(Server) | 存储目标(Target) | 数量关系 | 是否独立进程 |
|---|---|---|---|---|
| 元数据 | MDS 进程 | MDT 磁盘卷 | 通常 1:1,可通过 DNE 扩展到 1:N | MDS 是进程,MDT 是磁盘卷 |
| 数据 | OSS 进程 | OST 磁盘卷 | 通常 1:N,典型一台 OSS 挂 4-16 个 OST | OSS 是进程,OST 是磁盘卷 |
| 1. OSS + OST:数据面 |
Lustre 的数据读写路径由 Object Storage Server (OSS) 和 Object Storage Target (OST) 共同完成。
| 角色 | 类型 | 部署形态 | 功能 |
|---|---|---|---|
| OSS | 进程 | 运行在服务器上 | 接收客户端 I/O 请求,将其映射到 OST |
| OST | 磁盘卷(target) | 通常是挂载在 OSS 上的一块文件系统 | 存储实际的数据对象 |
-
OSS 是进程,是
lustre核心模块的一部分,负责协议处理。 -
OST 是磁盘卷,是 OSS 管理的存储目标,通常格式化成 ldiskfs 或 ZFS。
-
1 台 OSS 通常管理多个 OST,例如一台 OSS 服务器挂载 8 块 OST 磁盘卷。
并发优化
每个 OST 独立处理 I/O,客户端可并行访问多个 OST,因此 Lustre 能横向扩展读写性能。
2. MDS + MDT:元数据面
元数据操作由 Metadata Server (MDS) 和 Metadata Target (MDT) 完成。
| 角色 | 类型 | 部署形态 | 功能 |
|---|---|---|---|
| MDS | 进程 | 运行在元数据服务器上 | 处理目录操作、文件名、inode、权限等 |
| MDT | 磁盘卷(target) | 挂载在 MDS 上的元数据存储卷 | 存储 inode、dentry、ACL 等元数据信息 |
-
MDS 是进程,负责管理客户端的元操作。
-
MDT 是磁盘卷,存储实际元数据,格式通常是 ldiskfs 或 ZFS。
-
一个 MDS 通常管理一个 MDT,但 Lustre 2.7+ 开始支持 DNE(Distributed Namespace Environment):
- 多个 MDT 可以并行服务,命名空间分布到多个 MDT 上。
- 客户端会根据路径自动访问对应的 MDT。
- 类似“目录级别分片”,显著扩展元数据吞吐。
疑问:为什么Lustre文件系统 性能随着 服务器增加不断扩展,客户端的增加而增长?这个不符合常理,例如单机下无能无限增加线程个数?
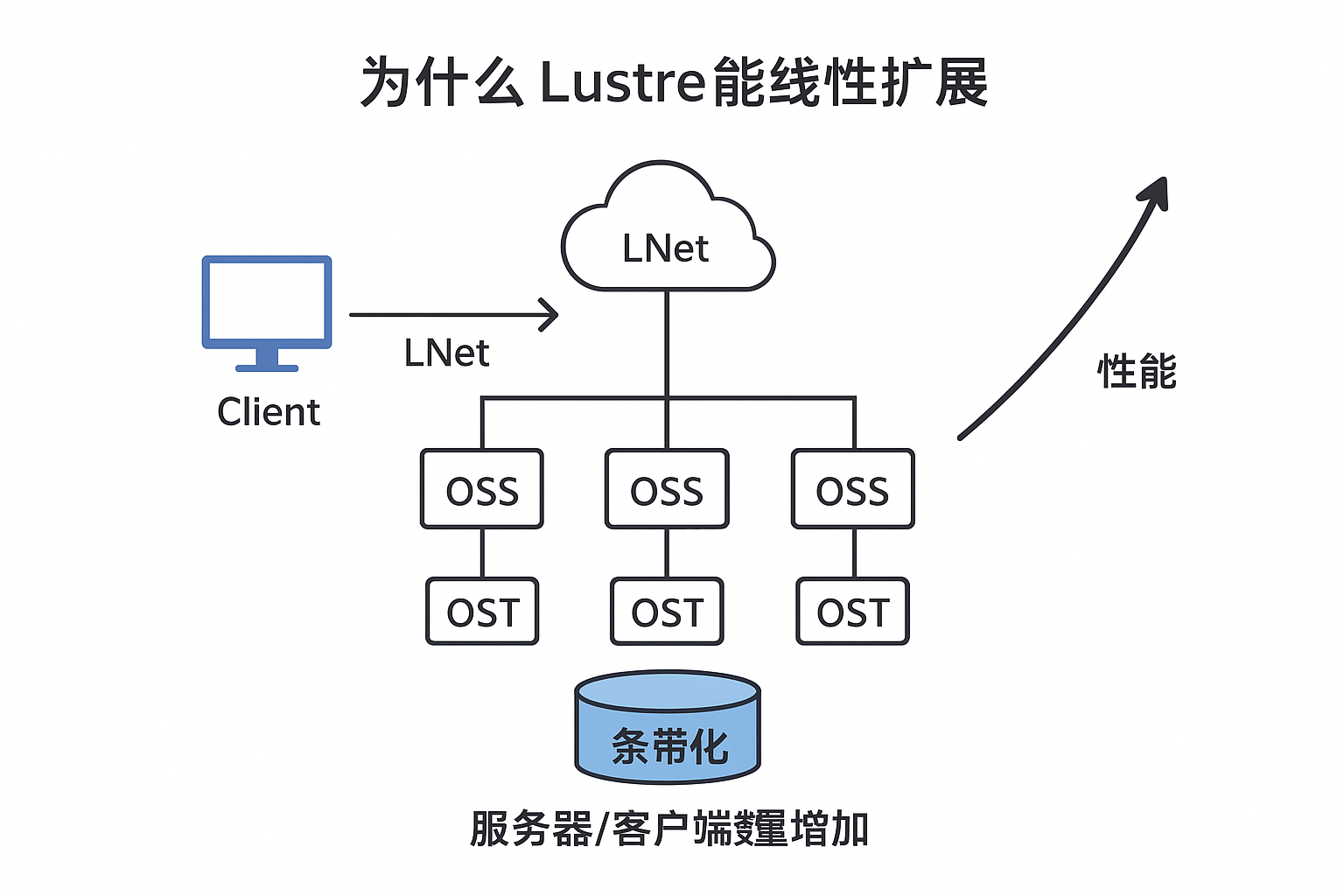
直观理解:HPC 实例
例如 DDN EXAScaler(DDN 商业化 Lustre):
- 1 个 OSS:4 块 OST,每 OST 10GB/s → 单节点带宽 ≈ 40GB/s
- 4 个 OSS:≈ 160GB/s
- 32 个 OSS:≈ 1.28TB/s
如果客户端也有足够多计算节点,整个系统总吞吐量可以接近线性扩展
Lustre 性能随服务器和客户端数增加而扩展,原因在于:
-
元数据与数据面解耦 → 消除单点瓶颈。
-
文件条带化 → 单文件可并行跨 OST 访问。
-
Lustre 的文件不是放在一台服务器上,而是被 条带化 存放在多个 OST 上:
-
当创建大文件时,客户端从 MDS 获取到 文件条带布局。
-
文件被切分为一系列固定大小的“条带”(Stripe),每个条带写入不同的 OST。
-
客户端在写入或读取时,直接并行访问所有相关的 OST
-
多 OSS/OST 架构 → 数据 I/O 可以横向扩展。
-
客户端并发利用更多 OSS → 随客户端数增加而扩展。
-
高性能网络 LNet → 支撑海量并行 I/O。
与ceph 设计有什么区别?
为什么 Lustre 性能能随服务器与客户端线性扩展,而 Ceph 不一定
| 对比维度 | Lustre(高性能并行文件系统) | Ceph(分布式对象/块/文件存储) | 影响性能线性扩展的原因 |
|---|---|---|---|
| 核心设计目标 | HPC + AI + 大规模并行计算场景 | 云存储 + 海量数据可靠性 + 灵活性 | Lustre 为高并发优化,Ceph 为一致性优化 |
| I/O 模型 | POSIX 文件系统语义,强条带化(striping),直接访问 OST | 基于 RADOS 对象存储,客户端 I/O 通过 CRUSH 算法路由到 OSD | Ceph 的对象访问存在更多逻辑层和元数据处理开销 |
| 数据分布方式 | 显式条带化:同一个大文件被拆分到多个 OST,客户端并行读写 | CRUSH 哈希分布:每个对象落在单个 OSD 上,单对象无法多 OSD 并行 | Lustre 可天然利用更多存储节点;Ceph 需要多对象并行 |
| 元数据服务器 (MDS) | 元数据集中管理,但支持多 MDS 扩展,元数据和数据分离 | 元数据嵌入到对象映射,依赖 CRUSH 算法,扩展性受限 | Ceph 元数据分布较好,但每次访问仍需计算 CRUSH |
| 网络层 | LNet 高性能网络,支持 RDMA,带宽与 OSS/客户端线性扩展 | 使用 TCP/IP + librados,支持 RDMA 但协议栈复杂 | Lustre 网络更薄更快,Ceph 协议栈更重 |
| 性能瓶颈 | 理论上无中心瓶颈,主要瓶颈在单 OST 硬件带宽 | PG(Placement Group)重平衡、OSD 内部一致性、写放大 | Ceph 为高可靠设计,性能受一致性与复制牵制 |
| 典型场景 | HPC、AI 训练、科学计算、TOP500 超算 | 云对象存储、K8s 持久卷、海量备份、视频平台 | 目标不同导致架构取舍不同 |
核心原因总结
-
Lustre 条带化 + 并行访问
- 单个大文件被切分到多个 OST。
- 多客户端可同时并行访问文件的不同块,几乎线性扩展。
-
Ceph 单对象单 OSD
- 单个对象只能落在一个 OSD 上,无法像 Lustre 那样在对象内部并行。
- 即使有 100 个 OSD,访问一个 1TB 文件仍然是单对象单 OSD。
- 想并行只能手动切分对象,增加复杂度。
-
网络协议栈不同
-
Lustre 的 LNet 专为 HPC 优化。
-
Ceph 基于 librados + TCP,协议更通用但开销更大。
-
-
一致性 vs 吞吐量
- Lustre 追求极致吞吐,牺牲数据可靠性(一般依赖 RAID 层解决)。
- Ceph 追求强一致 + 高可靠,天然限制了线性扩展。
疑问:条带化 和对象区别?
困惑:
你觉得 Ceph 一个文件被切成多个对象,这些对象分散在不同的 PG,不同的 OSD 上,所以理论上不是应该可以并行读写吗?
答案是:可以并行,但并行度和 Lustre 的架构比起来有本质差异,并不是“自动无限扩展”,原因主要在于 条带化 vs. 对象分布策略。
1. Ceph:文件 → RADOS 对象 → PG → OSD
- Ceph 的存储核心是 RADOS,它把上层文件(或块)切分成 对象,默认大小常见是 4MB。
- 每个对象通过 CRUSH 算法映射到某个 PG(Placement Group)。
- PG 再映射到 1~3 个 OSD(取决于副本数)。
- 这意味着:
- 一个对象只能被一个主 OSD 管理
- 同一个对象的读写是串行的,不会跨 OSD 并行
- 文件的并行度上限 = 文件被切分的对象数 =
文件大小 / 对象大小
例子
假设你有一个 1TB 的大文件:
- 默认对象大小 4MB → 会切成 25 万个对象
- 这 25 万个对象分布到不同的 OSD → 理论上可并行
- 但是:
- 客户端 IO 请求是顺序的 → 大多数应用一次只读一小段
- 如果应用没有并行访问多个对象,RADOS 本身不会帮你并行
- 每个对象落到单一 OSD 上,不会条带化
因此,如果应用不显式多线程并行读写,性能不会线性扩展。
2. Lustre:文件 → 条带化 → OST → OSS
Lustre 的核心是 条带化(striping):
- 写文件时,Lustre 会把文件切成固定大小的条带(stripe),每个条带交错分布到不同的 OST(Object Storage Target)。
- 与 Ceph 最大不同:
- 同一个文件的单个大对象可以跨 OST 条带化
- 客户端访问一个大文件时,Lustre 会自动并行调度多个 OST
- 不需要应用层显式并行
例子
同样是 1TB 文件:
- 条带大小 1MB,条带数 8
- 意味着 第 1MB → OST1,下一条 1MB → OST2,依次循环
- 如果有 100 个 OSS/OST,客户端可以一次并行打开 100 条 TCP 连接同时拉数据 → 性能近似线性扩展
3. Ceph vs Lustre 的关键区别
| 对比点 | Ceph | Lustre |
|---|---|---|
| 数据分布 | 文件 → 对象 → PG → OSD | 文件 → 条带 → OST |
| 单对象并行 | 不支持,一个对象只落一个 OSD | 支持,单文件的条带跨多个 OST |
| 并行度 | = 文件对象数 / 应用线程数 | = 条带数 × OSS 数量 |
| 客户端自动并行 | 不会,应用需显式多线程 | Lustre 客户端自动并行 |
| 典型应用 | 大量小对象存储、云存储、虚拟化盘 | HPC、大文件高吞吐 |
总结一句话:
Ceph 的并行度是“对象级”的,而 Lustre 的并行度是“条带级”的
如果应用本身是顺序访问,Ceph 并行度低,而 Lustre 即使单线程也能自动并行调度。
“Ceph 一个文件多个对象,多个对象落在不同 PG 组里,这不是并行吗?”
-
如果应用同时读写多个对象 → 是并行的
-
但默认情况下,客户端顺序读写一个文件 → 只会操作一个对象 → 并行度低
-
Lustre 不需要应用做多线程 → 天生条带化 → 自动高并发
疑问: ceph 对象和 **条带化关系?
关键点在于 Ceph 的对象切分 和 条带化(striping) 是两回事,但它们又能叠加在一起。
我们一步一步拆开来看,并举例对比 不开启 striping 和 开启 striping 的差异。
1. Ceph 默认的对象切分(Object Splitting)
在 Ceph 中,每个 RADOS 存储池(pool)会有一个 对象大小上限(通常是 4MB 或 8MB,默认 4MB)。
当你写入一个大文件,比如 1GB,Ceph 会自动把它切分成多个 对象(Object):
-
假设对象大小是 4MB
-
1GB 文件 → 256 个对象
-
每个对象通过 CRUSH 算法映射到 PG(Placement Group),再由 PG 映射到具体的 OSD。
🔹 效果:
-
不用任何条带化配置,你就已经有了 多对象、多 OSD 并行。
-
但注意:同一个对象还是只在 一个 OSD 上,不会跨 OSD 并行。
2. 开启条带化(Striping)
条带化是 在对象内部再切片,目的是让单个大对象的内容跨 OSD 分布,从而进一步提升并行读写性能。
它由 librados 和 CephFS / RBD 提供,核心配置有两个参数:
-
stripe_unit(条带大小):一次写入的最小块,比如 1MB。
-
stripe_count(条带数):每轮写入几个条带,比如 8。
2.1 举例:不开启 striping
假设:
-
对象大小:4MB
-
文件大小:16MB
-
共有 4 个 OSD
写入逻辑:
- Ceph 把 16MB 文件切成 4 个对象,每对象 4MB。
- 这 4 个对象被 CRUSH 分布到 4 个 OSD(假设每个 OSD 恰好得到一个对象)。
📌 写 4MB 对象时,只能走 单 OSD 单线程,无并行。
并行度 = 对象数量,与 对象大小强相关。
开启 striping**
假设:
- stripe_unit = 1MB
- stripe_count = 8
- 对象大小 = stripe_unit × stripe_count = 8MB
写入逻辑:
-
16MB 文件会切为 2 个对象,每个对象 8MB。
-
对象内部再分成条带:每个对象 8MB → 8 个 1MB 条带。
-
这 8 个条带轮流落在 8 个不同的 OSD 上(只要 CRUSH 足够分散)。
📌 优势:
- 即使是一个对象,也能利用多个 OSD 同时写。
- 并行度 = 对象数 × 条带数,显著提升。
3. 为什么条带化有用
如果文件足够大,且对象大小设置得小(比如 4MB),不开启 striping 也能获得不错的并行度,因为会有很多对象。
但如果场景是:
- 大文件数少
- 对象大小很大(比如 128MB 或 256MB)
- 单对象读写很频繁
这时不开启条带化,单对象性能会被单 OSD 限制,开启 striping 后则能并行。
5. 总结对比
| 特性 | 不开启 striping | 开启 striping |
|---|---|---|
| 大文件切分 | 按 对象大小切 | 先按对象切,再对象内部切条带 |
| 单对象落点 | 单个对象只在 1 个 OSD | 单对象内部跨 多个 OSD |
| 并行度 | ≈ 对象数量 | ≈ 对象数量 × 条带数 |
| 适用场景 | 小文件多、默认场景 | 大文件少、追求单文件高带宽 |
5回答你的疑问
“Ceph 一个文件多个对象,多个对象落在不同 PG → 这不是并行吗?”
是并行,但并行度受限于对象数量。
如果:
- 文件大、对象数多 → 自动并行,striping 可有可无。
- 文件大、对象数少(比如对象 256MB)→ 不开启 striping 会受限,
- 开启 striping 可以在对象内部也做到并行,性能更好。
| 场景 | 是否条带化 | 单对象大小 | 并行度 | 单文件读写速度 |
|---|---|---|---|---|
| 默认 | 否 | 4MB | 1 OSD | ~1× OSD 带宽 |
| 条带化 | 是 | 1MB | 8 OSD | ~8× OSD 带宽 |
所以,条带化的意义是:
-
让同一个大文件在对象层面并行
-
打破“单对象只能在单 OSD 上访问”的瓶颈
-
类似 Lustre 的 OST 条带分布,但是在 对象级别 而不是文件级
二、 GPFS文件系统机型性能
2.1 性能数据汇总:
| 机型 | 类型 | 厂商 | 文件系统 | 单节点聚合带宽 | 元数据OPS(估算) | 关键配置 |
|---|---|---|---|---|---|---|
| ESS 3500 | 全闪 | IBM | GPFS | 读:80 GB/s 写:52 GB/s | ≥1.5M | 双控双路,24×NVMe SSD |
| ESS 3500 | 混闪 | IBM | GPFS | 读:43.2 GB/s 写:29.7 GB/s | 80K–120K | 1×ESS 3500 + 4×4U102磁盘柜 |
- IBM SSS 6000 是目前该系列中性能最高的型号

SSS 6000
-
每 Rack U 的性能:读带宽为 77.5GB/s(更接近 Weka),
-
写带宽 38.75GB/s(略微超过 DDN AI400X2T),读 IOPS 3,250 k 也算超过 Weka 了吧。
2.2 机型配置
IBM Storage Scale 系统规格对比
来源:https://www.ibm.com/cn-zh/products/storage-scale-system
| 规格 | Storage Scale System 3500 | Storage Scale System 6000 |
|---|---|---|
| 尺寸 | 2U | 4U |
| 支持驱动器 | 24 × 30.72 TB TLC NVMe | 24 × 61.44 TB QLC + 24 × 30.72 TB TLC NVMe 或 48 × 30.72 TB TLC NVMe 或 48 × 38.4 TB FCM |
| 最大原始容量 | 737.28 TB | 2,211.84 TB(混合 QLC + TLC) |
| 最大吞吐量 | 126 GB/s | 330 GB/s |
| 扩展 | 多达 4 个直连 JBOD | 多达 9 个直连 JBOD |
| 数据传输接口 | 12 GB SAS | 24 GB SAS |
参数解读
- 尺寸 (U)
- 3500:2U,更紧凑,适合机房空间有限或中小规模部署
- 6000:4U,空间占用大,但提供更高性能和更大容量。
- 驱动器类型与配置
- 3500:全 NVMe(TLC),强调高性能随机 I/O。
- 6000:
- 可混合 QLC + TLC NVMe,提高容量同时兼顾部分性能。
- 可选 FlashCore Module(FCM),进一步提升闪存性能。
- 支持更多驱动器(48 个),容量与并行吞吐能力显著提升。
- 最大原始容量
- 6000 的容量约为 3500 的 3 倍,可满足大规模数据存储需求。
- 混合 QLC + TLC 设计:成本和性能兼顾,TLC 提供高性能,QLC 提供高密度存储。
- 最大吞吐量
- 3500:126 GB/s,适合中等并行 I/O 场景。
- 6000:330 GB/s,高吞吐量,适合 HPC、大数据或 AI 训练场景。
- 扩展能力
- 3500:支持最多 4 个直连 JBOD(增加容量)。
- 6000:最多 9 个直连 JBOD,可横向扩展更大规模。
- 数据传输接口
- 3500:12 GB SAS,带宽受限于接口,适合中等负载。
- 6000:24 GB SAS,接口带宽翻倍,保证大规模并行 I/O 不受瓶颈。
简单理解:
-
3500:紧凑、高性能,适合中小规模、高性能需求场景。
-
6000:大容量、高吞吐量、可混合闪存,适合大规模集群、高并行 I/O 的 HPC/AI 数据中心。
2.3 IBM Spectrum Scale(GPFS) 架构
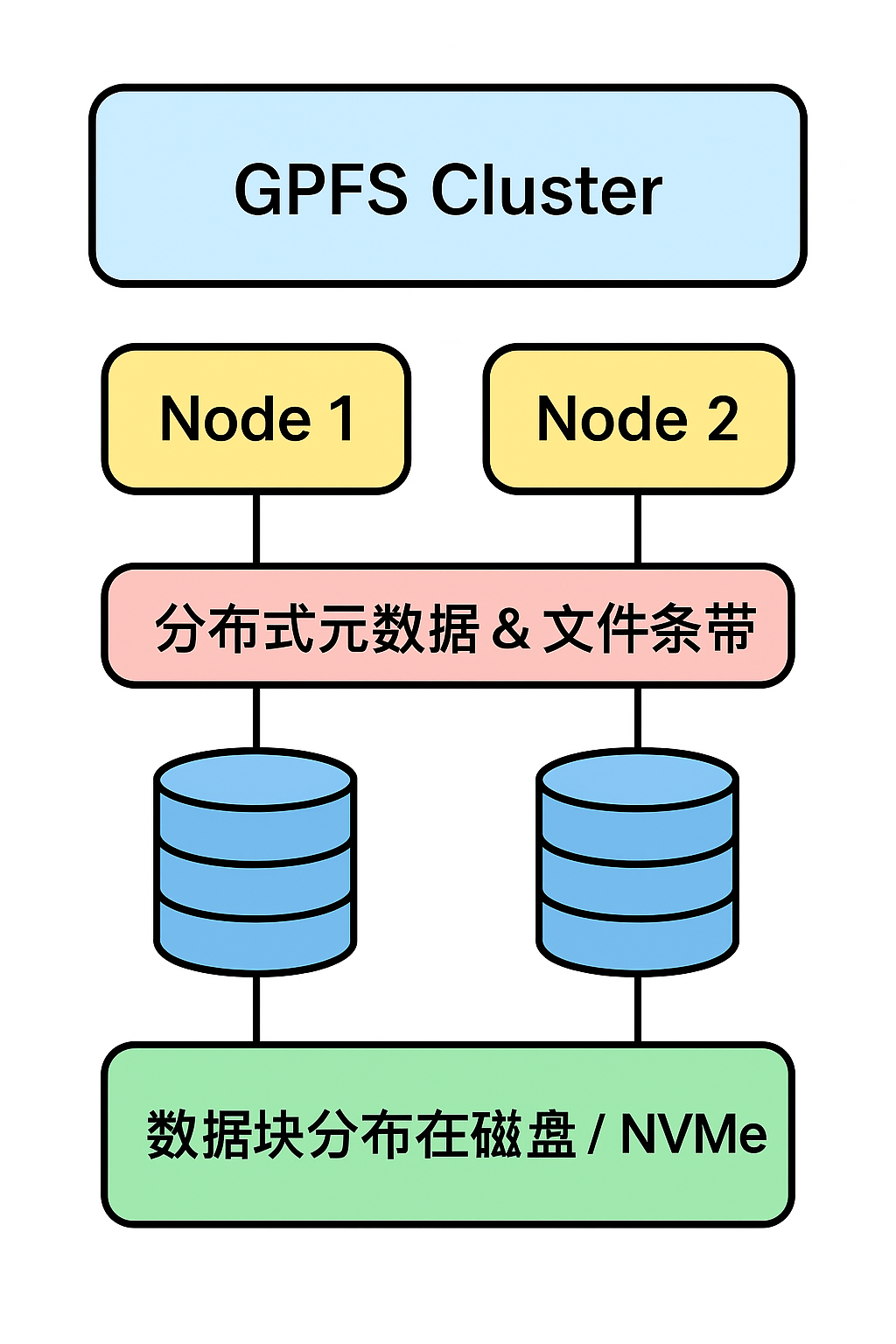
性能是架构设计的主要目标,为什么支持并发访问
架构核心思想:并行化一切可以并行的操作,尽可能消除数据从应用到磁盘之间的等待。
1. 集群化管理 (Unified Management)
- 设计要点:整个集群可以通过一个统一的界面(GUI)或者任意一个节点进行管理和操作。
- 优势:提升了系统的可维护性和易用性,管理员无需登录特定主节点,降低了运维复杂度。
2. 磁盘访问并行化 (Parallel Disk Access)
- 设计要点:所有计算节点都能够直接并行地访问后端存储设备上的数据块或元数据。
- 优势:打破了传统存储的中央网关瓶颈,实现了对存储带宽的线性扩展。存储设备越多,聚合带宽就越高。
3. 数据 IO 并行化 (Parallel Data IO)
- 设计要点:所有节点发出的数据或元数据读写请求可以同时进行处理。
- 优势:极大地提升了系统的整体吞吐量(Throughput),能够同时响应海量客户端的请求。
什么架构设计支持高性能
1️⃣ 节点角色清晰
| 节点 | 小白比喻 | 功能 |
|---|---|---|
| 计算节点 | 工人 | 处理客户端请求,执行逻辑 |
| IO节点 | 仓库管理员 | 读写文件和元数据 |
| 存储节点(Disk/NSD) | 仓库 | 存放数据块 |
| 管理节点 | 厂长/调度员 | 管理集群、分配任务、控制一致性 |
分工明确 → 避免冲突 → 并发更高
2️⃣ 数据和元数据并行化
- 元数据:Metanode 管理文件信息,多人同时修改通过 Token 避免冲突
- 数据:文件拆成小块,分布在不同磁盘,多节点可并行读写
比喻:订单表(元数据)+ 货物(数据),大家同时查表取货 → 整体效率高
3️⃣ 并发访问支持机制
| 机制 | 功能 |
|---|---|
| 分布式磁盘访问 | 所有节点直接访问存储块,利用磁盘带宽 |
| 并行数据 IO | 多个 IO 节点同时读写,提高吞吐量 |
| 一致性控制(Token) | 多节点操作同一文件时保证一致性 |
| 去中心化管理 | 任意节点都能管理集群,消除中央瓶颈 |
疑问:上面我没看懂 元数据怎么查找一个文件的
核心思想:像查字典一样找文件
GPFS 管理文件元数据(如文件名、inode号)的核心思想是:将目录变成一个高效的“字典”,而不是一个“名单”。无论目录里有一个文件还是一百万个文件,它都能让你用接近恒定的速度找到目标。
目录 Inode:元数据的“总目录”
在 GPFS 中,每个目录本身也是一个特殊的文件(sparse file)。这个文件里存储的不是普通数据,而是该目录下所有文件和子目录的条目(entries)。
目录变大怎么办?—— “扩展附录”
当一个目录下的文件超过128个,4KB的“目录页”不够写了怎么办?
GPFS 的做法是:分配额外的存储块(Block)来存放多出来的条目,并在目录 inode 中通过间接指针(Indirect) 来指向这些块。
这些被分配出来的块,专门用于存放元数据,因此被称为 子元数据块(Sub Metablock)。每个 Sub Metablock 的大小是 8KB。
三、如何快速查找?—— “神奇的哈希算法”
现在,目录的条目可能分散在多个 Sub Metablock 中。如何在上百万个条目中快速找到一个文件,而不用逐个扫描?GPFS 的答案是:可扩展哈希(Extendible Hashing)。
工作原理如下:
-
计算哈希值:当你要查找一个文件(如
myfile.txt)时,GPFS 会先计算文件名的哈希值(一个数字指纹)。 -
定位块位置:系统会根据当前目录的大小,取这个哈希值最右边的 n 个比特(bits)。这 n 个比特直接告诉系统,你要找的文件条目存放在第几个 Sub Metablock 中。
-
直接访问:系统直接去那个确定的 Sub Metablock 里寻找,只需要扫描这个块内的条目即可。
最精妙之处在于“可扩展”(动态扩容):
-
一开始目录是空的,n=1(只用1个bit,最多区分2个块:0和1)。
-
当某个 Sub Metablock 存满时,n 会变成 n+1(例如从1bit变成2bits)。
-
系统会新分配一个Sub Metablock,并将满的那个块中的条目一分为二,根据它们哈希值新增的那一位是0还是1,重新分配到老块或新块中。
-
这个过程就像书的内容变多了,附录从1卷扩展成2卷,并重新整理了一下目录的存放规则。
总结与优势
通过这种设计,GPFS 的元数据管理实现了:
| 机制 | 实现方式 | 带来的优势 |
|---|---|---|
| 结构化存储 | 目录作为稀疏文件,使用 inode + Indirect块 + Sub Metablock | 元数据存储清晰、可扩展 |
| 高速查找 | 可扩展哈希算法 | 查找速度恒定,不受目录大小影响(百万文件与千文件速度相当) |
| 动态扩容 | 按需分配 Sub Metablock,哈希地址位动态扩展 | 扩容平滑,性能无抖动 |
因此,GPFS 能够轻松应对超大规模、海量文件的场景(如AI训练、气象分析、基因测序), 这正是其作为顶级企业级文件系统的核心竞争力之一。
疑问: 如果目录大小发生了变化,不是整个数据重新分配吗?
1️⃣ 目录大小变化 ≠ 数据重新分配
-
目录(Directory)只是指针数组,每个指针指向一个桶(Bucket)
-
目录翻倍时,只是复制指针,并没有移动桶里面的数据
-
桶的数据仍然在原来的物理位置
换句话说,目录扩容只是“让指针表更大”,而实际存储的数据不动
2️⃣ 案例理解
假设全局深度 d=2,目录有 4 个指针:
|
|
-
桶 B 满了,本地深度
k = 2(等于全局深度 d) -
目录翻倍(d = 3):
|
|
-
此时数据仍在原来的桶 B 里
-
然后桶 B 执行分裂,部分数据移动到新桶 B2
-
其他桶(A、C)的数据完全不动
关键点:只有满的桶的数据才会移动,其余桶不受影响
3️⃣ 核心结论
-
目录扩容只影响指针表,不影响大部分桶的数据
-
桶满才会局部分裂 → 只移动该桶的数据
-
所以可扩展哈希可以在动态扩容时保持高效,避免整个表重新哈希
参考资料
- https://juicefs.com/zh-cn/blog/engineering/lustre-vs-juicefs# Lustre 与 JuiceFS :架构设计、文件分布与特性比较
- http://lustrefs.cn/wp-content/uploads/2023/11/CLUG2023_03_%E9%99%88%E9%81%93%E7%A2%A7_DDN%E6%8C%81%E7%BB%AD%E6%94%AF%E6%8C%81Lustre%E7%A4%BE%E5%8C%BA%E5%8F%91%E5%B1%95.pdf DDN中国 陈道碧
- AI 时代的高端文件存储系统:IBM、DDN、Weka 和 VAST https://aijishu.com/a/1060000000498772
- 【CMU15-445 FALL 2022】Project #1 - Extendable Hashing
- CMU 15445 学习笔记—5 Hash Table
- 【数据库】可拓展哈希(Extendable Hashing)