从零实现分布式文件系统(二) 如何在不升级硬件的前提下,小文件并发读写性能提升十倍
 次阅读
次阅读
文章目录
【注意】最后更新于 August 7, 2024,文中内容可能已过时,请谨慎使用。
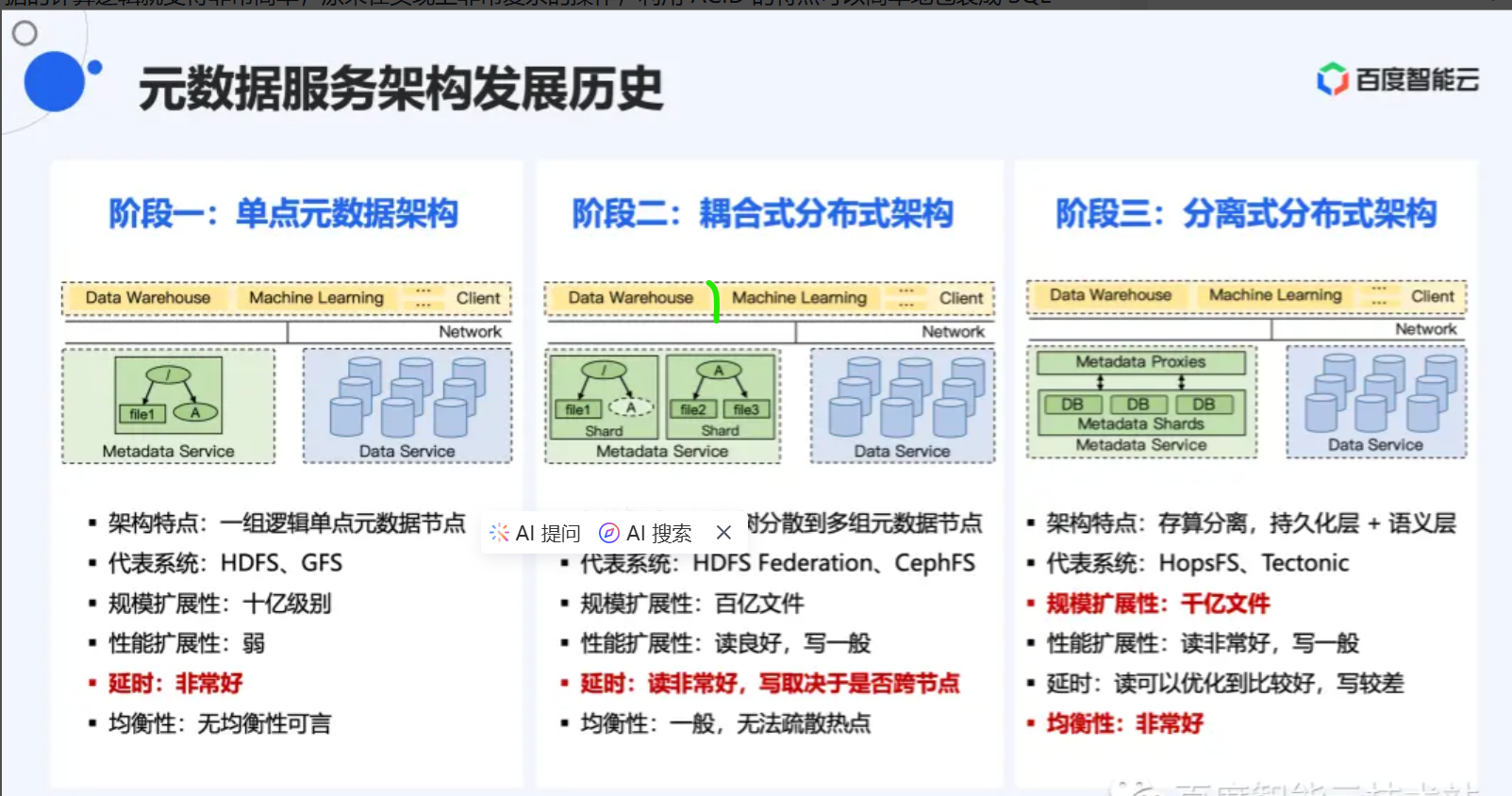
知识地图:分布式存储—元数据服务
本文版本1.0: 大约2万字,可以先点赞,收藏 在慢慢阅读。
本文版本2.0: 下篇文章更清晰 简化版对2万字进行压缩.
一、缘起:
从零实现分布式文件系统(一):100G 读写带宽、百万 IO 请求的文件系统,如何实现的?(正在酝酿中)
突然看了下评论区,有人直接问:
“在不升级硬件的前提下,怎么让小文件读写性能提升十倍?”
于是,我决定把第二文章提前发出来:
从零实现分布式文件系统(二)**——如何在不升级硬件的前提下,小文件并发读写性能提升十倍(元数据服务如何设计)
第一个感觉是什么:这怎么写我也不清楚,
既然是无法描述事情,那还担心什么,先写垃圾出来,

有不对的地方欢迎评论区一起讨论
1. 1 本文遵循两个原则 一个线索:
-
原则1 主线任务:大局观
越是复杂庞大的系统,越要先交代背景和问题。
一上来就闷头写优化代码,往往被批评成傻子?结果吃力不讨好。
就像动画《灵笼》第二季,整集都在描绘“灯塔阵营”(冰冷秩序)和“龙骨村阵营”(情感)的格局与世界背景。 -
原则2 隐藏剧情:细节决定成败
说出来大家可能都懂,但找到关键点往往要花很久。
比如:某工厂机器故障,技术人员无解,请来专家。
专家检查后,只在机器上划了一条线,工人按线拆开,果然找到并修复了问题。 专家收 1 万元——划线 1 元,知道划哪儿 9999 元。
1.2 一个线索:数据库和文件系统有相同点吗?
当然也不能想到哪里写哪里, 这样根本没有人看,更没人听,努力白费, 至少给一线索查询下去,让人感觉有理有据
(1)看到标题 在不升级硬件的前提下,小文件读写性能提升十倍
(2)我想到另外一篇文章: 不加机器,如何抗住每天百亿级高并发流量?
概念是总是混淆,这里重新澄清一下
不加机器,如何抗住每天百亿级高并发流量? 例如一个web服务,
前端:对数据库并发增删改查
- http post get delete请求
后端 :
- MVCC(Multi-Version Concurrency Control,多版本并发控制)
- ACID特性,原子性 一致性 **隔离性,持久性。
- 存储引擎,sql引擎。虽然不懂至少搜索出来一点资料 例如

- 客户端,协议层,SQL引擎,存储引擎
文件读写很模糊,操作系统封装很好,你想到
- 前端:read write rename,lseek,readdir,lookup,getattr
-
1970-1980年代,Unix衍生出System V、BSD、Solaris等多个互不兼容的版本,各厂商为竞争添加私有扩展
-
POSIX:可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),POSIX基于本地文件系统设计
- 后端:I/O 栈路径(用户态 -> VFS -> 块设备 -> 驱动 -> 硬件),
Linux Storage Stack Diagram

Linux存储栈采用分层设计,自上而下分为四层:
- 应用层:进程通过系统调用(如
read/write)发起I/O请求。 - 文件系统层:包括VFS(虚拟文件系统)和具体文件系统(ext4/XFS/Btrfs等),处理文件逻辑操作。
- 块层:核心为I/O调度(如
blk_mq)、设备映射(如LVM/RAID),将文件操作转为块级请求。 - 设备层:物理设备(HDD/SSD/NVMe)及驱动,执行最终数据读
Linux Storage Stack Diagram 这里不是我擅长领域, 如果按照这个思路写下,思路偏了。
1.3 最少知识,线索就是 POSIX基于本地文件系统设计,变成分布式呢?
| POSIX接口 | 说明 | ||
|---|---|---|---|
| 软/硬链 接 | 一个 inode 可以被多个目录项引用,修改引用计数 | ||
| 原子重命名 | 文件/目录改名需要保持一致性,且涉及多个目录项和 inode | ||
| 目录遍历 | 遍历时需保证一致性视图,避免遍历时出现“文件消失”或“幽灵文件,大型目录生成只读快照(基于COW技术),确保readdir遍历期间目录内容不变 |
||
| 权限继承和检查 | 不只是存值,还涉及复杂规则 | ||
| 文件锁定 | 通过 flock或 fcntl实现文件锁,协调多进程对同一文件的并发访问 |
||
| 间戳类型 | 触发条件 | 更新频率问题 | |
| atime | 文件被读取 | 高频读操作导致大量写元数据 | |
| mtime | 文件内容修改 | 与应用程序逻辑可能冲突 | |
| ctime | 元数据变更 | 权限、所有权等变更频繁时 |
到这里最少知识准备完毕,正式开始
二、大局观:元数据服务如何设计
| 文件系统 | 典型使用场景 | 特点/优势 | 不适合场景 |
|---|---|---|---|
| HDFS(Hadoop Distributed File System) | 大数据离线分析(Hadoop、Spark、Hive)、日志归档、批处理数据仓库 | - 面向大文件(GB~TB级)优化- 高吞吐,顺序读写性能好- 与 Hadoop/Spark 深度集成 | - 小文件性能差- 不适合低延迟随机访问 |
| CephFS(Ceph File System) | 云平台共享存储(OpenStack、Kubernetes PVC)、容器持久化存储、企业文件共享 | - POSIX 语义,支持块、对象、文件统一存储- 水平扩展能力强- 高可用、强一致 | - 元数据性能瓶颈影响小文件场景- 复杂部署与维护 |
| JuiceFS / 百度 CFS / 3FS(面向云原生的分布式文件系统) | 大数据 + 云原生(Spark、Flink)、机器学习训练数据集、混合云共享文件 | - 云原生兼容 POSIX- 元数据可存储在云数据库(如 TiKV、Redis)- 按需弹性扩容- 高并发小文件访问优化 | - 对极低延迟的 OLTP 类应用不合适- 云服务依赖度高 |
| Lustre | 高性能计算(HPC)、科学模拟、气象建模、基因分析、石油勘探 | - 极高吞吐(100GB/s+)- 适配 HPC 超算集群- 并行 I/O 优化 | - 部署复杂- 更适合专用计算集群,云原生集成差 |
| Alluxio(可选补充) | 计算与存储解耦的中间缓存层(Spark、Presto) | - 内存级缓存、跨存储系统统一命名空间 | - 不是持久化文件系统,需要与底层存储结合 |
简单总结场景匹配:
- HDFS → 离线大数据分析(批处理,吞吐优先)
- CephFS → 云平台 POSIX 共享存储(通用存储,弹性扩展)
- JuiceFS / 百度CFS / 3FS → 云原生高并发场景(尤其是小文件和混合云)
- Lustre → HPC 超高吞吐并行计算场景(科学计算、工程模拟)
2.1 单节点存储元数据服务合适小文件吗?
2.1.1 代表产品:
- Google File System (GFS)
- HDFS
2.2.2 元数据服务架构图
2.2.3 使用场景(或者优点):
- HDFS 主要用于 大数据批处理(Hadoop MapReduce、Spark 等)
- 元数据全部能存储到内存(访问效率高)
- 元数据都由master节点统一管理(减少锁冲突)
- 适合**顺序大文件读写
- HDFS 的 单写多读(Write Once, Read Many) 是它最核心的设计原则之
2.2.4 缺点
- 不适合存储小文件(高IOPS、海量小文)
- 不完全满足POSIX强一致性与语义(如随机覆盖写、强一致目录视图、原子多文件操作等)
2.2.5 取舍
HDFS 的目录操作在元数据更新和客户端可见性之间存在权衡:
- 强一致性场景:需通过
hsync()或安全模式实现,但牺牲吞吐量。 - 最终一致性场景:默认模式,适合对延迟不敏感的批处理任务
- 如果允许多客户端同时写,必须维护复杂的 分布式锁 + 随机写同步,这会极大降低性能和可扩展性。 因此 HDFS 直接放弃随机写
- 不适合小文件
| 设计取舍 | 带来的好处 |
|---|---|
| 禁止并发写 | 避免复杂的分布式锁协调,系统简单稳定 |
| 顺序写入 | 磁盘吞吐率高(顺序 I/O),网络传输更高效 |
| 写后多读 | 文件一旦关闭,就可以被多客户端并发读取 |
| 易于副本一致性 | 只需保证写入过程中的副本一致,关闭文件后副本稳定 |
2.2.6 疑问1:GFS/HDFS 为什么不适合存储小文件
- 块存储效率低
- 固定块大小:HDFS默认的块大小通常是128MB或256M。如果一个文件只有几KB或几MB,仍然会占用一个完整的块,导致存储空间浪费。
- 存储利用率低:大量小文件会导致块存储效率低下,磁盘空间利用率不高
- 访问性能差
- 寻址开销: HDFS是为顺序读取大文件优化的,而小文件的随机读取会导致频繁的寻址操作
- 网络开销:RPC与管道开销被放大
- 内存开销
- 元数据存储:占用大量N内存
2.2.7 疑问2:GFS/HDFS为什么不满足POSIX强一致性的语义
POSIX语义 强一致目录视图(Strongly Consistent Directory View)
1. 问题背景
- POSIX要求目录操作(如创建/删除文件)是原子的,所有客户端应看到一致的目录结构。
- 分布式元数据服务(如HDFS NameNode)通常采用最终一致性模型
2. 场景描述
- 客户端 A 向 NameNode 发起创建文件
/data/file.txt的请求。 - NameNode 分配新 inode 并更新元数据(标记文件为待写入状态),但未立即同步到所有 DataNode。
- 客户端 B 立即查询目录
/data,可能无法看到新文件。
3. 原因分析
- 元数据异步复制:NameNode 的元数据更新需通过 JournalNode 持久化,并异步传播到其他 NameNode(HA 模式)或 DataNode(数据块位置更新)。
- 客户端缓存:客户端可能缓存目录列表,未及时感知新文件
|
|
POSIX语义2 原子多文件操作或者重命名操作的原子性破坏
1. 问题背景
POSIX要求多文件操作(如批量创建、删除)是原子的,但分布式系统中跨节点操作难以保证:
- 部分成功问题:若操作涉及多个节点,网络分区或节点故障可能导致部分成功、部分失败。
- 协调开销:需引入分布式事务协议(如2PC、Raft),增加复杂性和延迟。
- 解决办法:实际系统中常牺牲强原子性,采用补偿机制(如重试)或最终一致性。
2. 场景描述
- 客户端 执行跨目录重命名
/dir1/file.txt→/dir2/file.txt。 - NameNode 需更新两个目录的元数据(删除
/dir1/file.txt,创建/dir2/file.txt)。 - 若元数据更新过程中断(如网络分区或 NameNode 故障),可能导致部分更新成功。
3. 原因分析
- 元数据操作非原子性:跨目录重命名需多次元数据更新,HDFS 未提供事务机制。
- 最终一致性妥协:HDFS 默认采用最终一致性模型,允许短暂不一致,最终通过后台同步修复。
2.2 (耦合式)多节点元数据架构适合小文件吗?
1.2.1 代表产品
- CephFS
- BeeGFS
- Lustre
1.2.2 元数据服务架构图
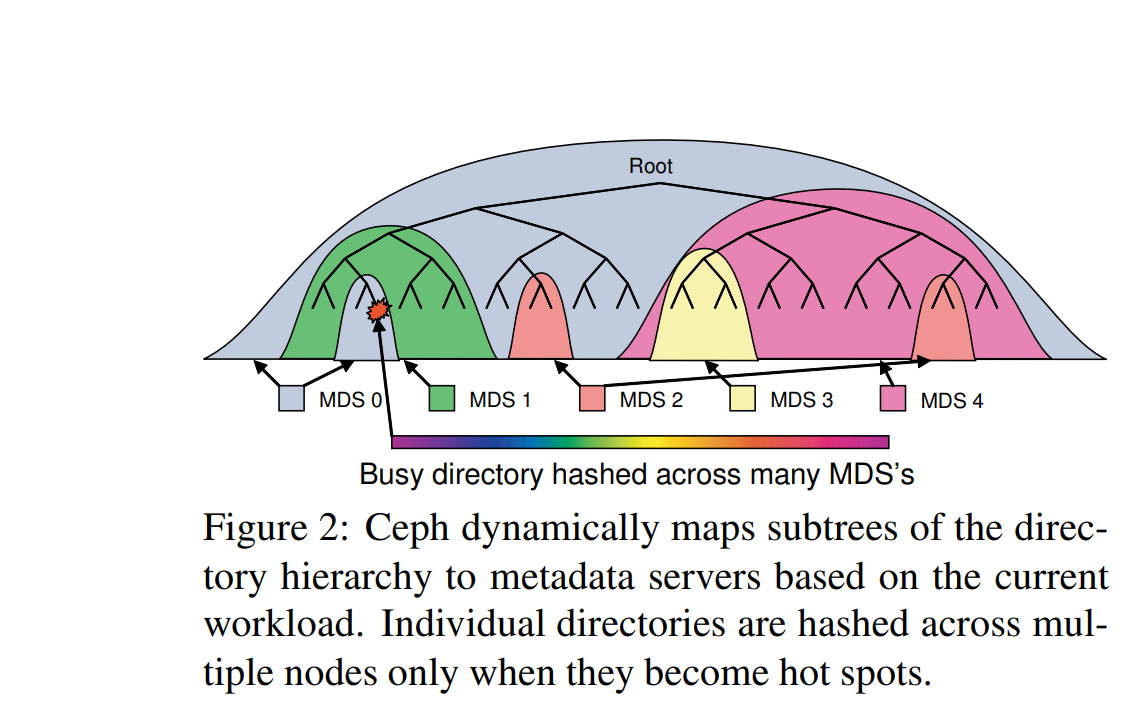
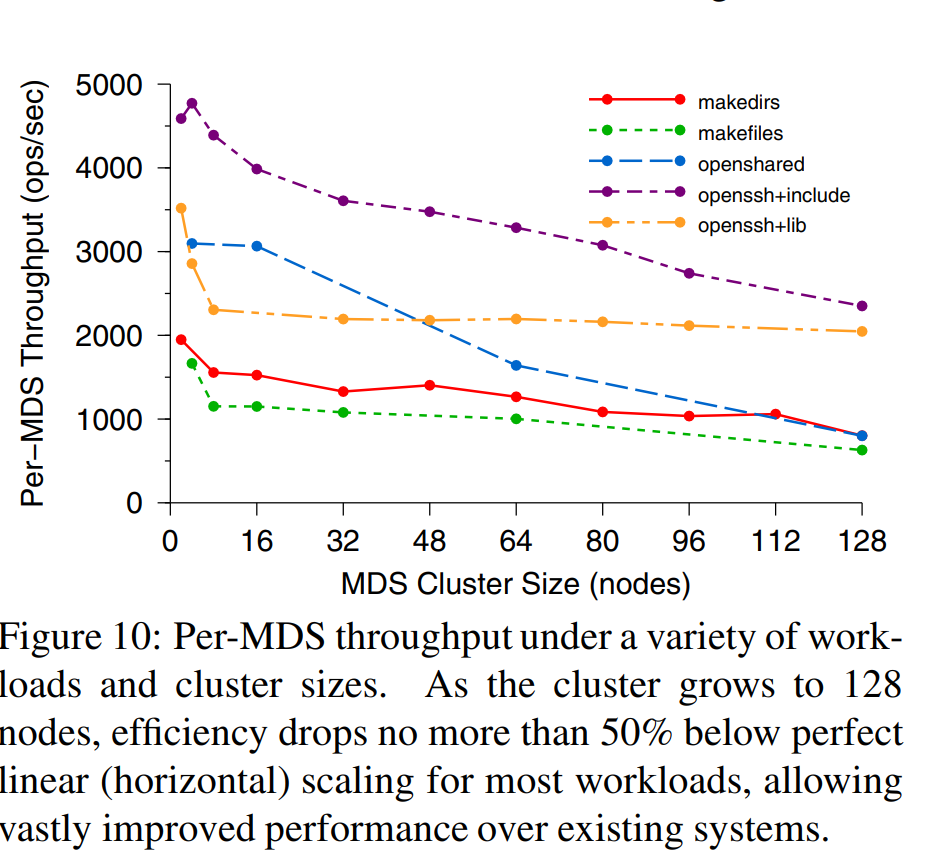
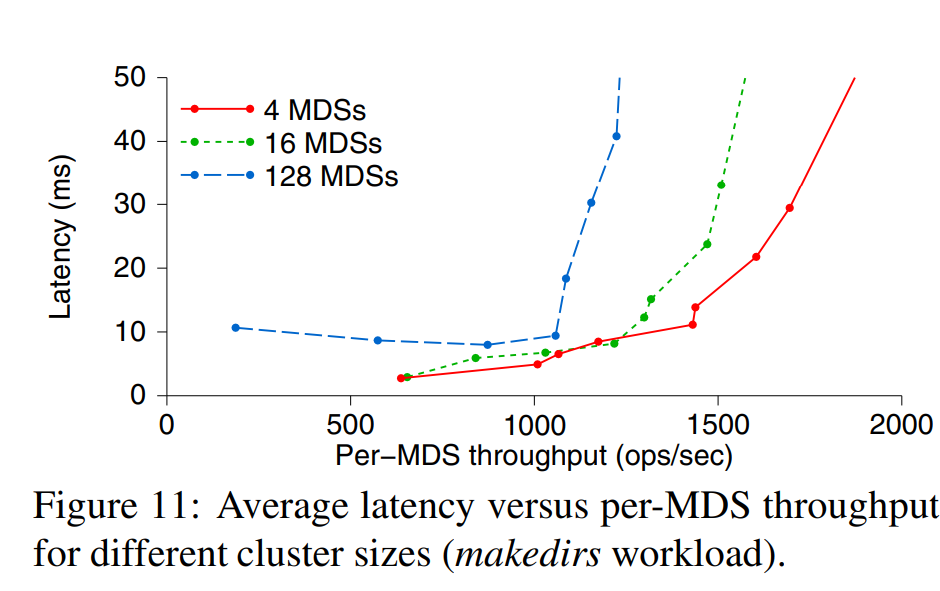
Average MDS throughput drops from 2000 ops per MDS per second with a small cluster, to about 1000 ops per MDS per second (50% efficiency) with 128 MDSs (over 100,000 ops/sec total). 128个mds节点达到1万qps
1.2.3 优点(使用场景)
- 【兼容】 Ceph 文件系统 (CephFS) 是兼容 POSIX 标准的文件系统
- 【依赖】在 Ceph 的分布式对象存储基础上构建 RADOS(可靠的自主分布式对象存储)。
- 【多个客户端并发】Ceph 文件系统是一种共享文件系统,因此多个客户端可以同时处理同一文件系统
- 【可扩展】Ceph 文件系统具有高度可扩展性,因为元数据服务器水平扩展,并且直接客户端对各个 OSD 节点进行读写操作。
- 元数据与数据分离架构、分布式锁机制 和 强一致性存储模型(当对于本地文件系统)
1.2.3 缺点
-
代码实现复杂,运维复杂,看不懂代码
-
为了保证一致性,引入分布式锁,MDS状态切换 ,代码直接看不懂.这不废了吗.
-
可扩展 就是添加机器,例如上图128个MDS ops 1万/秒,per MDS 1000 ops 性能极差。
-
Lustre并不适合小文件I/O应用,性能表现非常差
1.2.4 疑问 CephFS采用什么机制兼容 POSIX 语义
相关提问:
- CephFS的分布式锁机制具体是如何实现的?能否举例说明锁竞争的处理流程?
- CephFS与其他分布式文件系统(如Lustre)在POSIX语义实现上有哪些主要区别?
- CephFS在保证强一致性的同时如何优化性能?有哪些典型的性能优化策略?
POSIX 文件系统语义要求包括:
- 原子性:
write()、rename()、link()等必须在多客户端下表现一致(一次写入不可被分割)。 - 同步可见性:一个进程写文件,另一个马上能读到(如果调用了
fsync或关闭文件)。 - 文件锁定:
flock()、fcntl()等锁机制必须按规范生效。 - 目录一致性:创建、删除文件后,目录列表必须立刻反映变化
CephFS 通过 MDS 的分布式锁与状态机、RADOS 的强一致性存储 和 客户端协议优化
CephFS 分布式锁的核心实现机制 【绑定在ceph内部,其他项目无法使用,高度绑定。】
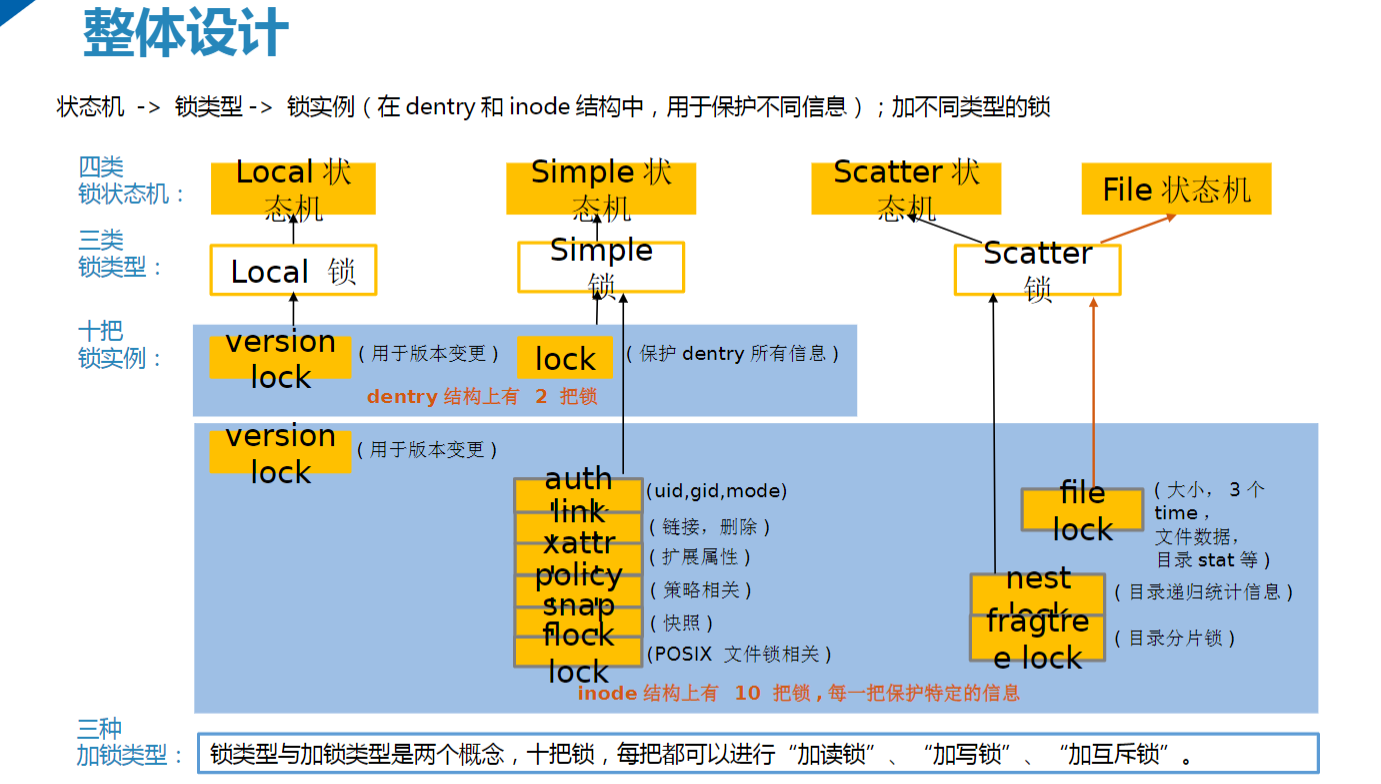
1. 锁类型与作用域
CephFS 通过 锁类型分层设计 实现高效的元数据管理: CephFS 定义了 4 种锁类型,覆盖不同元数据操作场景:
- LocalLock:本地锁,用于单 MDS 内无需分布式协调的元数据(如 inode 版本号)。
- SimpleLock:共享读/排他写锁,适用于目录项(dentry)、权限(authlock)等需要互斥写入的场景。
- ScatterLock:共享读/共享写锁,允许权限委托(如目录统计信息 INEST)。
- FileLock:文件锁,管理文件数据访问权限(如读写锁)。
| 型 | 锁模式 | 适用场景 | 性能影响 |
|---|---|---|---|
| LocalLock | 本地版本锁 | inode/dentry 版本控制 | 无跨节点开销,低延迟 |
| SimpleLock | 共享读/排他写 | 目录项操作、权限变更 | 写锁阻塞其他写操作 |
| ScatterLock | 共享读/共享写 | 目录统计、分片管理 | 允许并发读,写需协调 |
| FileLock | 读写锁 | 文件数据读写 | 写锁导致读阻塞 |
示例:
- 目录创建操作需获取
SimpleLock(排他写锁),确保同一目录下文件名唯一性。 - 目录统计信息更新使用
ScatterLock,允许多个 MDS 并行更新不同子目录。
2. 锁状态机与自动评估
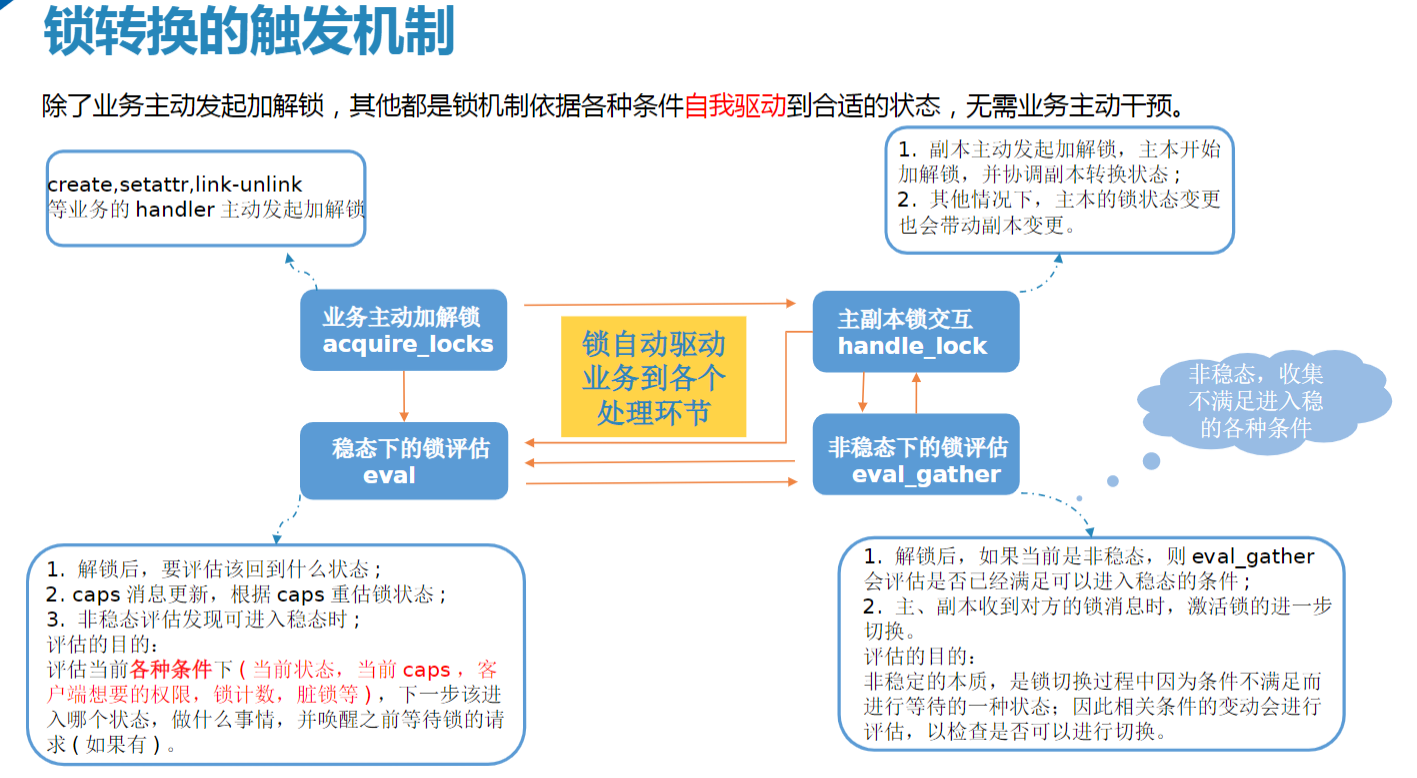
高度抽象,业务参与很少
高度抽象,业务参与很少
- 系统自动驱动:锁状态(如
available、held、revoking)由 MDS 根据请求和定期评估自动转换。 - 触发条件:
- 请求驱动:客户端请求如读、写、打开文件等操作会触发锁状态评估 Server::handle_client_readdir–>mds->locker->eval
- 定期评估:定期检查锁状态以优化性能和资源利用 Locker::tick()—->eval_scatter_gathers();
- 客户端能力(Caps)变化 Locker::handle_client_caps –>mark_updated_scatterlock
3. 锁持久化与故障恢复
-
RADOS 存储锁状态:锁元数据持久化到 RADOS 对象(如
ceph_lock),确保 MDS 故障后锁状态可恢复。 -
HA 切换:主 MDS 故障时,备用 MDS 通过日志恢复锁状态,保证操作连续性。
锁竞争处理流程(以目录重命名为例)
场景描述
- 客户端 A 尝试将
/dir1/file.txt重命名为/dir2/file.txt。 - 客户端 B 同时尝试删除
/dir2/file.txt。
处理流程
-
锁请求阶段
-
客户端 A 向 MDS 发起
rename()请求,需获取以下锁:-
/dir1的SimpleLock(排他写锁,确保目录项可修改)。 -
/dir2的SimpleLock(排他写锁,确保目标目录可写入)。
-
-
客户端 B 发起
unlink()请求,需获取/dir2的SimpleLock(排他写锁)。
-
-
锁冲突检测
- MDS 检测到
/dir2的SimpleLock已被客户端 B 请求,且与客户端 A 的请求冲突。
- MDS 检测到
-
锁状态转换与协调
-
阶段 1(准备):MDS 标记
/dir2的SimpleLock为revoking,通知客户端 B 释放锁。 -
阶段 2(等待):客户端 B 收到通知后,若操作未完成则回滚
unlink(),释放锁。 -
阶段 3(授予):MDS 确认
/dir2锁可用后,授予客户端 A 排他写锁。
-
-
操作执行与提交
-
客户端 A 完成重命名操作,更新目录项元数据。
-
MDS 持久化锁状态变更到 RADOS,并通知其他 MDS 副本同步。
-
-
异常处理
- 若客户端 A 在操作中崩溃,MDS 检测到锁超时(默认 60 秒),自动释放锁,允许其他客户端重
问题:客户端故障后锁自己释放问题?
- 当多个 client 需要共享一个文件时,linux 通常采用的方法是给文件上 锁,避免共享的资源产生竞争状态。这里的文件锁(filelock)要与分布式锁中的 flock 区分开.
- Filelock 可分为 flock 及 fcntl 两类系统调用,前者只能锁定整个文件,后者可以操作文件的一部分
- handle_client_file_setlock 整个过程复杂,这里跳过,代码太丑了了。
Ceph 中的 Two-Phase Commit(2PC)
在分布式文件系统里,一个操作可能涉及多个对象、多个元数据位置。为了防止“只更新一半”的问题,Ceph MDS 会用两阶段提交:
- 阶段 1(Prepare):锁定所有相关元数据节点,写预日志(journal)
- 阶段 2(Commit):确认所有节点都准备好 → 真正写入并释放锁
2PC 是保证分布式元数据操作原子性的关键机制
举个例子(POSIX rename 原子性):
假设 /dirA/file1 被 rename 到 /dirB/file2
- Prepare 阶段
- MDS 找到
dirA和dirB所在的元数据分区(可能不同 MDS 节点) - 对两个目录加锁
- 写入“rename 事务”到 MDS 的 journal(预写日志)
- MDS 找到
- Commit 阶段
- 所有参与的 MDS 都返回 “ok”
- MDS 同步更新目录结构(
dirA删除 file1,dirB添加 file2) - 释放锁并广播缓存失效
1.2.5 疑问 ceph 对文件read 和write操作如何保证POSIX语义
1. POSIX 的要求
read-after-write 在 POSIX 里意味着:
- 当进程 A
write()某个文件的部分数据,并且该写调用返回后,其他进程(无论在同一台机器还是远程节点)再去read()这个文件,同一位置必须能读到刚刚写入的数据(不应该再读到旧版本)。 - 这个语义对分布式文件系统尤其难,因为不同客户端各有自己的缓存,数据要通过网络分发,还要考虑崩溃恢复。
2. 场景:客户端 A 写文件,客户端 B 读文件。
-
A 打开文件 → 从 MDS 获得写 cap(允许本地缓存和写入)。
-
A write() → 数据分片写到 OSD,OSD 完成多副本确认后返回成功。
-
B open() → 向 MDS 请求 inode caps。
-
MDS 检查发现 A 仍持有写 cap → 向 A 发送 cap recall。
-
A 将脏数据 flush 到 OSD 并确认 → MDS 更新 inode 状态并把写 cap 降级。
-
MDS 给 B 分配读 cap → B 从 OSD 读取最新数据。
-
B 读到的就是 A 最新写入的内容(read-after-write 保证成立
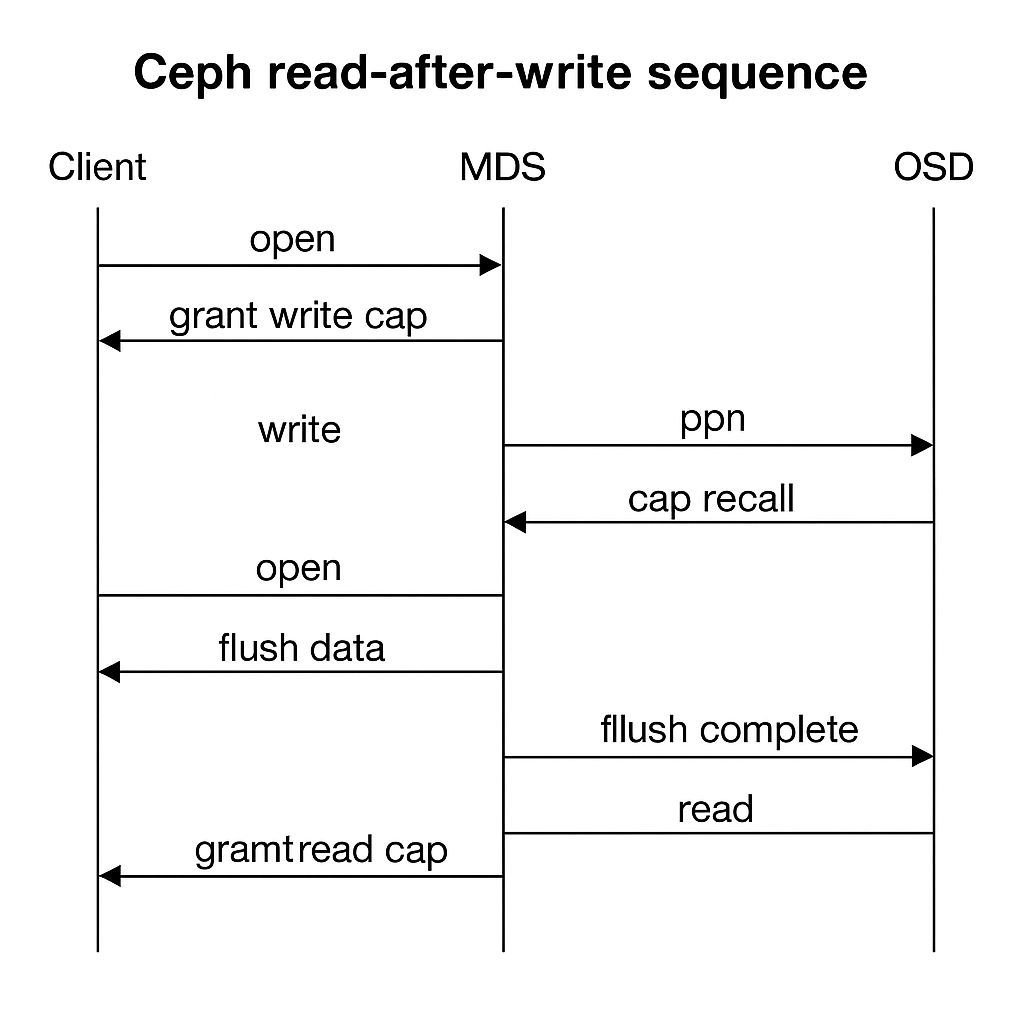 为了实现这一点,CephFS 的三个主要参与方协作:
为了实现这一点,CephFS 的三个主要参与方协作:
| 模块 | 在 read-after-write 语义中的职责 |
|---|---|
| 客户端(CephFS Client) | 本地缓存数据和元数据,通过 MDS/OSD 获取 capability(caps)来判断能否直接读写或需要同步;在必要时向其他客户端发 cap recall/invalidate 消息,确保它们的缓存失效。 |
| MDS(Metadata Server) | 掌握文件和目录的“所有权/租约”,用 caps 控制客户端的缓存权限,当一个客户端写数据后,MDS 会通知持有读缓存的其他客户端回收或刷新对应数据。 |
| OSD(Object Storage Daemon) | 存储实际数据对象,保证单对象写入的原子性与顺序性(RADOS 层);当客户端写入 OSD 完成后,RADOS 保证后续读能看到最新版本。 |
| 存储池(RADOS Pool) | 提供多副本或纠删码存储,并在对象级别实现一致性,保证 OSD 写成功后数据在整个存储池是可见的。 |
|
|
3.1 客户端缓存控制:capabilities (caps)
-
cap 是 MDS 发给客户端的一种“权利票”,表示某客户端在一段时间内可对某个 inode 执行哪些操作(读缓存、写缓存、元数据修改等)。
-
如果客户端 A 打开文件并写入,MDS 会让它持有 写 cap(WR cap)。
-
当另一个客户端 B 也来读这个文件时,MDS 会:
-
检查 B 是否有最新数据缓存,如果没有则允许读;
-
如果 A 还持有写 cap,那么 MDS 会发送 cap recall 给 A,要求它刷回脏数据到 OSD,并把写 cap 降级为只读 cap;
-
当数据刷回并确认后,B 再去 OSD 读到的就是最新数据。
-
重点:cap recall 是 Ceph 保证多客户端缓存一致性的核心机制,避免脏缓存被其他客户端读到。
3.2 数据写入路径:Client → OSD
-
客户端写数据后,数据会被分片映射到对应对象(RADOS object)中,通过 CRUSH 算法定位 OSD。
-
OSD 内部的 RADOS 层保证:
-
单对象的写是 原子可见 的;
-
写请求按到达顺序应用,后写入的内容对后续读可见;
-
多副本模式下,必须大多数(或全部)副本确认写入后才返回成功给客户端。
-
-
当客户端 write 调用返回时,意味着 OSD 集群已经确认这个数据在存储池中可用,因此下一次读就会拿到新数据(无论是本客户端还是其他客户端)。
3.3 元数据协同:MDS 协调数据与元数据一致性
-
写文件时不仅要更新数据,还可能要更新元数据(如 mtime、size、blocks)。
-
MDS 负责把这些元数据更新与数据写回进行协调:
-
客户端写完数据 → 发送元数据更新 RPC 给 MDS;
-
MDS 根据 inode 的 caps 状态决定是否立即同步元数据到所有客户端;
-
当需要保证 read-after-write 时,MDS 会确保在允许其他客户端读之前,数据和元数据已经一致。
-
-
对于纯数据更新(不涉及扩展文件长度),MDS 可以延迟元数据刷新以优化性能,但依然会保证数据可见性。
3.4 存储池(RADOS Pool)保证最终一致性
-
在 RADOS 层,每个对象有一个版本号(epoch/objver)。
-
当 OSD 收到写请求时,会更新对象版本,并在返回响应时告诉客户端最新版本号。
-
后续任何客户端请求读取该对象时,都会根据这个版本号拿到最新的数据(除非请求特意要求旧版本)。
-
这样,跨客户端的数据一致性在对象级别就被 RADOS 层锁死
3.5 代码实现

| 步骤 | 关键函数 / 文件路径 | 作用 |
|---|---|---|
| 1 | Client::ll_open() → MDCache::issue_cap() |
打开文件并从 MDS 获取写 cap |
| 2 | Client::write() → librados::aio_write() → OSD 写入路径 |
写数据到对象并多副本确认 |
| 3 | MDCache::handle_open() |
MDS 接收 B 的 open 请求 |
| 4 | Client::handle_cap_recall() |
MDS 向 A 发起 cap recall |
| 5 | Client::flush() → librados::aio_write_full() |
A flush 脏数据到 OSD |
| 5 | MDS::handle_cap_ack() → MDCache::downgrade_cap() |
MDS 确认 flush 并降级 A 的 cap |
| 6 | MDCache::issue_cap()(read)→ librados::read() |
给 B 分配读 cap 并从 OSD 读最新数据 |
| 7 | OSD 返回已提交数据 | 保证 read-after-write 一致性 |
2.3 分离式元数据架构
2.3.1 代表产品
- JuiceFS
- 3fs
- CFS
2.3.2 元数据结构特点
这个方法论具体的做法是将复杂系统进行分层, 每一层次专注于解决一个领域的问题做到极致, 最后叠加不同层次实现完整的功能。
这在计算机领域是屡试不爽的套路。
近年数据库领域流行的存储计算分离架构,都是最好的佐证
-
数据库层:实现数据的持久化的同时提供分布式事务能力;
-
元数据代理层:这一层对外提供 POSIX 或 HDFS 接口,对内将层级命名空间的数据转换成 Table 系统中的记录,处理时利用事务保证操作的正确性。
- JuiceFS 的元数据管理是完全独立于数据存储的,这意味着 JuiceFS 可以支持大规模数据存储和快速文件系统操作,
- 例如 Redis、TiKV、MySQL等。这种架构的设计使得 JuiceFS 可以通过共享同一个数据库和对象存储实现强一致性保证的分布式文件系统。
DeepSeek 3FS 选择 FoundationDB 作为元数据服务的核心存储引擎,其设计目标是通过分布式事务性键值存储实现 强一致性元数据管理,同时结合 RDMA 网络和用户态零拷贝技术优化性能。
2.3.3 优点
- 复杂功能让别人实现,代码和运维简单
- 性能:延迟
| 系统 | 元数据存储 | 一致性模型 | 典型场景 | 延迟(μs) |
|---|---|---|---|---|
| 3FS | FoundationDB | Serializable | AI 训练/推理 | 4-15 |
| CephFS | 内置 MDS | 最终一致性 | 通用存储 | 20-100 |
| JuiceFS | Redis/TiKV | 会话一致性 | 对象存储 | 10-50 |
| HDFS | ZooKeeper | 最终一致性 | 大数据批处理 | 50-200 |
2.3.4 疑问1 文件系统元数据可以存储kv吗?
3FS 元数据服务架构设计
(1) 键值模型映射
-
目录树编码
将 POSIX 目录结构转换为键值对,支持高效范围查询
| 键格式 | 值内容 | 用途 |
|---|---|---|
DENT:{parent_inode}:{name} |
child_inode |
目录项查询 |
INOD:{inode} |
{size, mode, blocks...} |
文件属性获取 |
CHUNK:{inode}:{offset} |
chunk_id |
数据块定位 |
| |
|
|
JuiceFS 的文件系统映射结构
JuiceFS 使用象存储 + 元数据引擎(如 Redis / RocksDB / TiKV) 的混合架构:
| 文件系统内容 | 映射到 KV 系统的方式(键Key → 值Value) |
/a/b/c.txt 文件元数据 |
inode:<inode_id> → {mode, uid, gid, timestamps, size…} |
| 目录结构 | parent:<inode_id> → [child_inode1, child_inode2, …] |
| 文件数据块 | data:<inode_id>:<block_index> → 二进制数据块 |
| 路径索引 | path:/a/b/c.txt → inode_id |
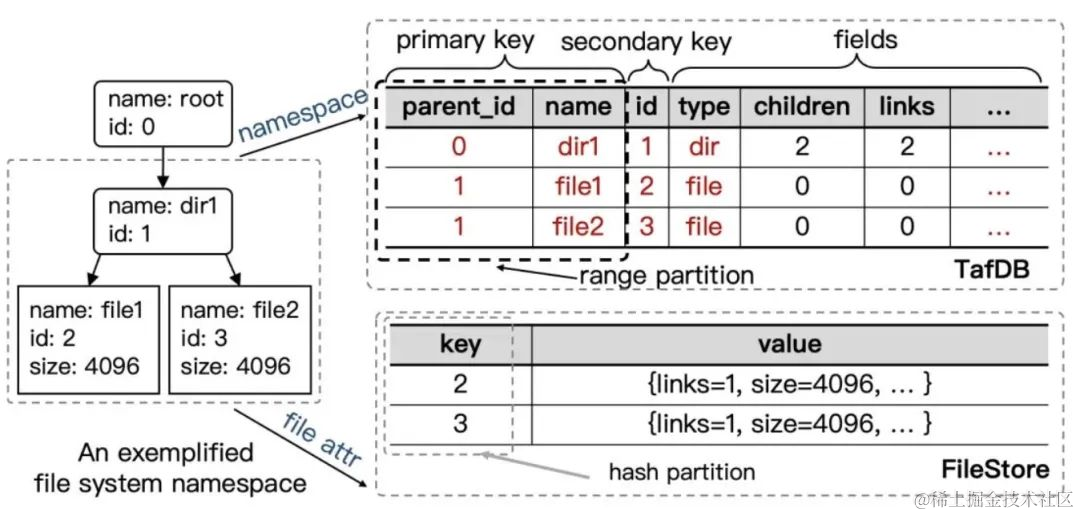 本文的主要目的是解读百度沧海·存储团队发表于 EuroSys 2023 的论文《CFS: Scaling Metadata Service for Distributed File System via Pruned Scope of Critical Sections》,论文全文可以在 https://dl.acm.org/doi/10.1145/3552326.3587443
本文的主要目的是解读百度沧海·存储团队发表于 EuroSys 2023 的论文《CFS: Scaling Metadata Service for Distributed File System via Pruned Scope of Critical Sections》,论文全文可以在 https://dl.acm.org/doi/10.1145/3552326.3587443
2.3.5 疑问2 DeepSeek 3FS 选择 FoundationDB?而非 TiKV
Meta Service 提供元数据服务,采用存算分离设计
-
元数据持久化存储到 FoundationDB 中,FoundationDB 同时提供事务机制支撑上层实现文件系统目录树语义;
-
Meta Service 的节点本身是无状态、可横向扩展的,负责将 POSIX 定义的目录树操作翻译成 FoundationDB 的读写事务来执行。
-
整个请求路径上端到端没有任何缓存而是采用及其简单的事务配合以coroutine调度来满足高吞吐
| 特性 | FoundationDB | TiKV |
|---|---|---|
| 设计定位 | 分布式事务性键值存储,强一致性 | 分布式事务性KV存储,主要服务于 TiDB |
| 事务模型 | 强事务(ACID),多键跨范围事务 | 分布式事务,基于 Percolator 模型 |
| 数据模型 | 纯 KV,支持多版本事务 | KV,支持 MVCC 和事务 |
| 开发语言 | C++ | Rust |
| 开源时间 | 2013年开源,设计较早 | 2016年左右开源,后起之秀 |
| 社区和生态 | 小众,闭源多年后开源,生态相对小 | 活跃,TiDB 生态核心组件 |
为什么选 FoundationDB 而非 TiKV?
1. 事务模型的差异与成熟度
- FoundationDB 的事务模型设计非常严谨,事务隔离和一致性强,尤其擅长处理复杂跨多键事务。
- TiKV 虽然也支持分布式事务,但早期实现对复杂跨范围事务支持有限,且针对 TiDB 设计优化更多,针对通用事务灵活度略低。
- 3FS 需要强事务保证,FoundationDB 能提供更加稳健的事务保障。
2. 一致性和容错保证
- FoundationDB 在分布式一致性算法(Paxos)和故障恢复方面经验丰富,设计成熟。
- TiKV 虽采用 Raft 算法,也保证一致性,但设计目标更聚焦数据库场景,某些极端一致性需求支持尚在演进。
3. 架构设计和接口差异
-
FoundationDB 提供简单且强大的多版本键值事务接口,易于构建复杂系统如文件系统。
-
TiKV 的接口更适合 SQL 层服务,作为 TiDB 的存储引擎,缺少一些通用分布式事务的特性。
4. 生态和使用历史
- FoundationDB 在构建复杂分布式系统方面已有成功案例,且项目稳定,适合长期依赖。
- TiKV 虽活跃,但更依赖 TiDB 生态,独立使用时部分功能仍在完善。
2.3.5 疑问3 为什么 JuiceFS 能用 TiKV,Ceph 不行?
-
TiKV:一个分布式、强一致性、支持多版本并发控制(MVCC)的事务性键值存储系统,底层基于 RocksDB 实现。
-
POSIX inode:文件系统中的一个重要抽象,用来描述文件的元数据和标识。支持复杂的文件系统语义,比如:
-
多硬链接(同一个 inode 多个路径)
-
目录层级结构(父子关系)
-
权限继承、时间戳维护
-
原子重命名、目录遍历等操作
JuiceFS 完成了 文件系统 → KV 映射
Ceph基于omap方式,虽然kv但是没有直接一
| 对比项 | Ceph | JuiceFS |
| 元数据结构 | 面向对象层级结构(如 inode、dentry) | 统一建模为 Key-Value |
| 依赖的特性 | POSIX 强一致性、事务、关系型语义 | 松耦合,弱一致性可接受,围绕 KV 设计 |
| 元数据存储引擎 | 自研 MDStore / BlueStore(用 RocksDB) | 可配置,支持 Redis、TiKV、MySQL、RocksDB |
| 与 TiKV 匹配程度 | 差,难以迁移元语义 | 好,天然为分布式 KV 设计 |
JuiceFS 元数据结构设计图
|
|
Ceph 的元数据结构图(简化)
|
|
2.3.6 疑问3 Ceph 在RocksDB层怎么key value 映射
| 维度 | JuiceFS | Ceph (Omap) |
|---|---|---|
| 底层存储 | 纯 KV 存储(Redis/RocksDB/S3) | RADOS 对象 + Omap (对象内的 KV 集合) |
| 元数据映射 | 文件系统元数据直接映射成 KV 键值对 | 元数据存在对应对象的 Omap 中 |
| 数据与元数据 | 元数据与数据完全分离,数据放对象存储 | 元数据和数据是两个不同对象 |
| 一致性保证 | 依赖底层 KV 事务支持 | 依赖 RADOS 提供的原子批量操作 |
| 扩展性 | 利用 KV 存储扩展性 | 利用 RADOS 集群扩展能力 |
| 访问路径 | KV 存储访问路径清晰简单 | 通过对象访问,Omap 为对象附加结构 |
| 适用场景 | 云原生、轻量级文件系统 | 大规模分布式存储系统,兼顾对象存储与文件 |
- JuiceFS元数据与数据完全分离,数据放对象存储
- Ceph 元数据和数据是两个不同对象,对象的 Omap 中
| JuiceFS | Ceph |
|---|---|
| 完全解耦的元数据引擎 • 支持Redis、TiKV、MySQL等多种独立元数据引擎 • 元数据操作通过标准键值接口(GET/SET/DELETE)实现 • 元数据与存储层完全分离,可独立扩展 | 集成式元数据管理 • 元数据存储在OSD的OMAP结构中 • 依赖MDS(元数据服务器)集中管理目录树和文件属性 • 元数据与存储层(RADOS)强耦合 |
Ceph Omap 的缺点(特别是在云原生环境下) 复杂度较高,维护成本大
-
Omap 作为 RADOS 对象上的内嵌 KV 集合,实现和维护复杂度较高。【表的概念】
-
需要管理对象的生命周期、版本、事务,系统设计和调试难度大。
-
云环境更倾向于轻量、易用、易扩展的系统,Ceph的复杂性成为负担。
三、细节:先正确,在优化
3.1 细节:从多线程到分布式到文件系统推到出 POSIX 语义这个最少知识点,满足线性一致性。
本文目标是:如何在不升级硬件的前提下,小文件并发读写性能提升十倍 但是上来不是考虑优化,而是考虑正确性,为了保证正确性,我做如下分析,
单机 多线程保证一致性:
- 互斥锁,自旋锁,
- C++ 11 引入了标准的内存模型,C++ 标准不依赖于任何特定的编译器,操作系统,或 CPU。它依赖于抽象机(abstract machine)
- C++11标准中提供了6种memory order
|
|
分布式数据库
- 假设从分布式系统只写一个值保证一致性
- 采用2pc,3cp raft,paxos等协议
- 成为OB贡献者(4):从单点到多节点 i++并发方案

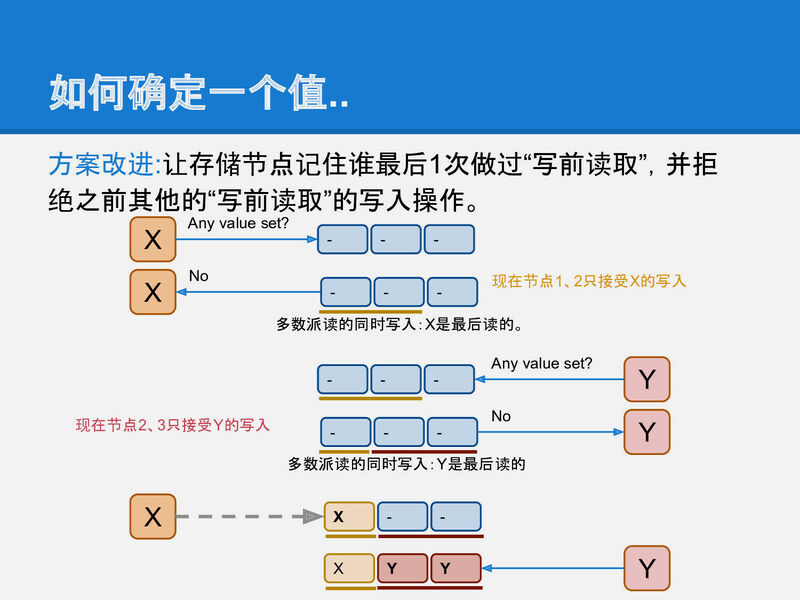
分布式文件系统
- 最后提到POSIX 语义如何保证正确性。这个最后因此线索
3.2 为了保证 POSIX语义 线程一致性 不同系统是如何实现的
疑问:为什么原子计数不保证都读正确性?
|
|
-
threadA加了很多次,理论上
cnt应该是1000。 -
但 threadB 的
load可能读到小于1000的值,因为写没同步过去
| 写 | 原子性:写入不会丢失,累加正确 | 多线程加计数不会出错 |
| 读 | 同步性:读到的是最新写入值? | 可能读到过期旧值(延迟) |
3.2 Ceph小文件优化
| 功能 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|
| MDS Cap 管理 | 减少权限请求次数,合并写操作 | 权限失效复杂,写缓存同步难 | 多写操作,频繁修改小文件 |
| ObjectCacher | 缓存热点数据,降低访问延迟 | 内存占用高,缓存一致性复杂 | 小文件频繁读写 |
| Writeback/Delayed Sync | 减少IO次数,提高写响应速度 | 数据持久性有延迟,崩溃恢复复杂 | 写操作高峰期,合并批量写入 |
1. MDS Cap 管理(客户端写权限管理)
举例说明
- 小明的客户端要写一个小文件
file.txt,先向 MDS 申请写权限(write cap)。 - MDS 授权给小明写权限后,小明客户端在本地先缓存写操作,不必每次写都立即同步到后端。
- 小明可以多次写入同一个文件,这些写操作合并成一批,最后一次性发给后端存储(RADOS)。
- 这样减少了客户端和 MDS 之间频繁通信,提升写性能。
优点
- 减少了频繁向 MDS 请求权限的网络开销。
- 写操作可以本地合并缓存,避免多次小数据同步。
- 提升写性能和响应速度。
缺点
-
需要保证写权限失效或回收时数据一致,增加系统复杂度。
-
在写权限丢失或者网络异常时,需要处理写缓存的同步和回滚,设计较复杂。
2. ObjectCacher(对象缓存)
举例说明
-
客户端频繁读取或写入小文件
file.txt的数据和元数据。 -
ObjectCacher 会在客户端或 MDS 内存中缓存该文件对应的对象数据和元数据。
-
下一次访问时直接从缓存拿,避免访问底层磁盘或网络调用,提高响应速度。
优点
-
显著降低对底层存储的访问频率,提升小文件读写性能。
-
缓存热点数据,减少延迟。
-
减轻后端存储系统压力。
缺点
-
占用较多内存资源。
-
需要处理缓存一致性,复杂度提升。
-
热点缓存失效时可能会出现短暂性能下降。
3. Writeback / Delayed Sync(写回与延迟同步)
举例说明
-
用户写入小文件内容时,Ceph客户端不立即写到底层存储。
-
而是先写入本地或MDS的写缓存,写操作“标记”后延迟一段时间批量同步到底层存储。
-
多个小写操作合并成一个大批次提交,减少网络和磁盘IO。
优点
-
减少了小文件写入时的网络和磁盘IO次数。
-
写入操作更快,客户端响应时间短。
-
更高效利用系统带宽和IO资源。
缺点
-
数据持久性会有延迟(写入未同步前,如果系统崩溃,可能丢失部分数据)。
-
需要设计机制保证写回时数据一致性和崩溃恢复。
历史文章
- 企业案例:分布式存储产品架构性能优化总结
- 知识地图–块存储
- Linux高性能网络详解从 DPDK、RDMA 到 XDP(上)
- 【项目实践】IO-uring助力TiKV提升1倍写性能
- 浪潮AS13000分布式存储在医疗影像场景中如何优化小文件IO性能
- 【翻译】Ext4 文件系统中大型目录结构的最佳实践
- 面试官:从三万英尺角度谈一下Ceph架构设计(1)
- Ceph分布式锁的设计哲学与工程实践
- 慢盘问题:从青铜到王者的处理思路
- 深入理解文件系统:文件IO的一生
- 分布式(存储)文件系统设计要点与实践之愚见
- 一种数据readdir方法、系统、设备及计算机 https://patents.google.com/patent/CN110896415A/zh
- readdir性能优化技巧有哪些
- 如何优化Linux readdir性能
- SOSP19' Ceph 的十年经验总结:文件系统是否适合做分布式文件系统的后端
- 如何将千亿文件放进一个文件系统,EuroSys‘23 CFS 论文背后的故事
- 论文 [https://dl.acm.org/doi/10.1145/3552326.3587443
- Curve 如何演进 (1):从 EuroSys'23 CFS 论文看文件系统
- 实践案例03:HDFS如何解决超大规模流式数据读写
- Google文件系统为了极简设计,舍去哪些复杂实
- Lustre 与 JuiceFS :架构设计、文件分布与特性比较
- 【翻译】Crimson:用于多核可扩展性的下一代 Ceph OSD
- Ceph: A Scalable, High-Performance Distributed File System
- 3FS Meta Service源码剖析
- FoundationDB 最佳实践
- 从 CephFS 到 JuiceFS:同程旅行亿级文件存储平台构建之路
- C++ 并发编程(从C++11到C++17)
- 现代C++并发编程教程
- C++并发编程实战 (第2版)
- 深入理解C11/C++11内存模型(白嫖新知识~)
- 成为OB贡献者(4):从单点到多节点 i++并发方案