企业案例03:分布式存储产品架构性能优化总结

文章目录
【注意】最后更新于 August 7, 2024,文中内容可能已过时,请谨慎使用。
一 、背景
假如现在你参与一个后端服务产品性能优化,该如何下手呢?
上来直接优化那是万不行的,至少确定优化原则,重构,还是缝缝补补?
目前我是要给普通开发工程师,直接舍去重构。
本文AS13000 产品架构性能为例子,在优化之前需要了解基架构组成
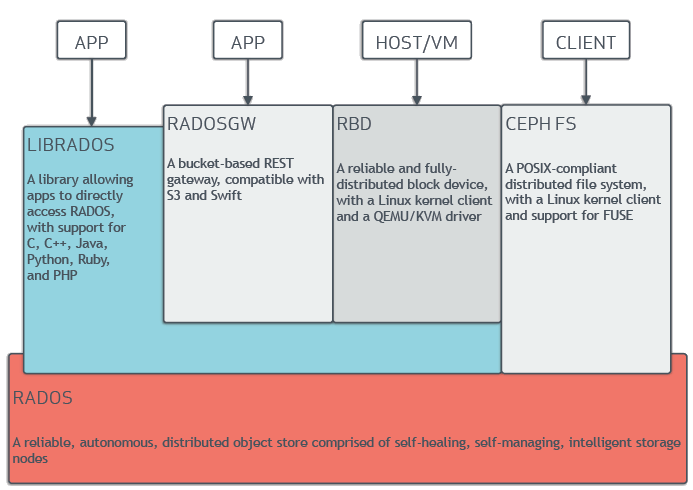
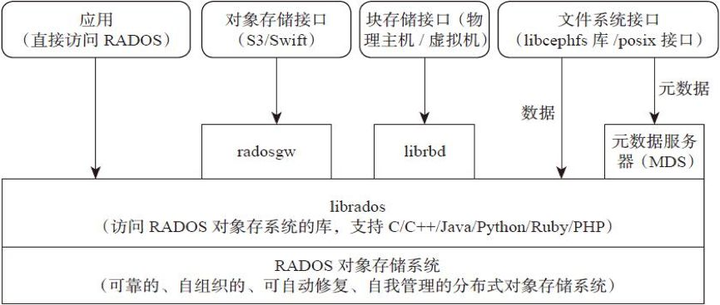
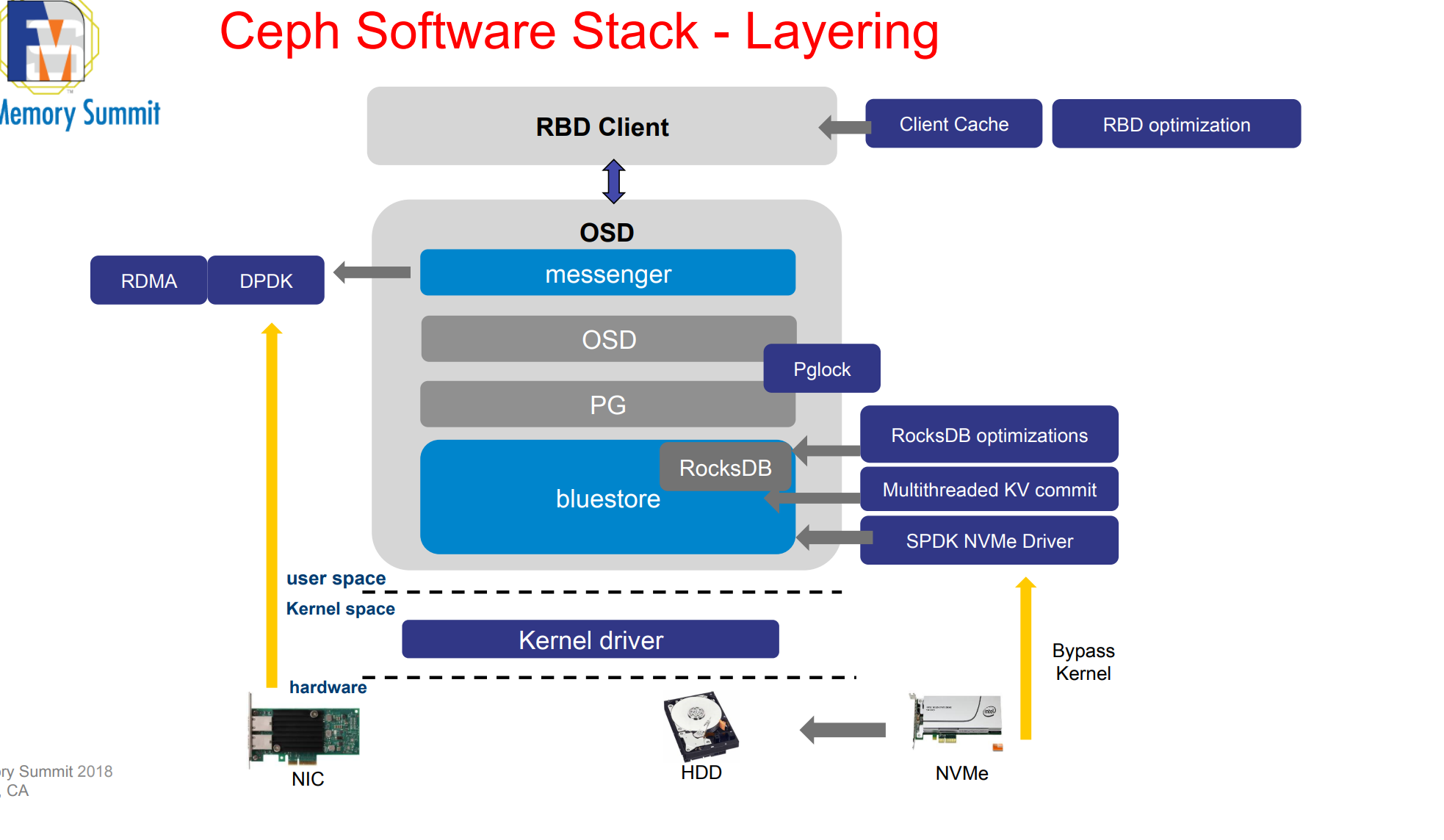
三层架构
- 用户层: 提供三种服务 对象存储,块存储,文件存储,LIBRADOS模块是客户端用来访问RADOS对象存储设备的
- 中间层: Monitor :负责整个集群状态 ,MDS,负责文件的元数据,OSD 提供存储池:
- 存储引擎:RADOS是指Reliable Autonomic Distributed Object Store,
- BlueStore,绕过文件系统:直接读写块设备,RocksDB 键值数据库存储对象元数
- Seastore,下一代 存储引擎,替代 BlueStore,直接管理物理存储设备, 独立管理元数据,不再依赖 RocksDB。(Bluestore 在 NVMe 上最明显的瓶颈是 kv-sync-thread,即顺序提交元数据到 RocksDB 的线程)
- Crimson,定位:基于 Seastar 框架重构的 OSD(对象存储守护进程)架构,替代传统多线程 OSD

| 维度 | Seastore | Crimson |
|---|---|---|
| 架构重点 | 存储引擎(数据持久化层) | OSD 服务框架(请求处理层) |
| 核心技术 | - 用自研 B+树管理元数据,取代 RocksDB - 支持写时复制(Copy-on-Write) - 支持 ZNS/SMR 磁盘 | - 基于 Seastar 异步框架(Run-to-Completion 模型) - 单线程 per core,避免锁竞争 - 兼容现有 ObjectStore 后端(如 BlueStore/Seastore) |
| 性能优化方向 | - 降低读放大,避免 RocksDB 的 Compaction 阻塞 - 提升全闪存集群的 IOPS 和延迟 | - 减少 CPU 上下文切换 - 利用多核并行处理请求,释放 NVMe 带宽潜力 |
| 依赖关系 | 可独立于 Crimson 部署(例如运行在经典 OSD 上) | 需搭配存储引擎(如 BlueStore 或 Seastore)使用 |
-
Seastore 是 存储引擎,解决数据落盘效率问题;
-
Crimson 是 OSD 服务框架,解决 CPU 多核扩展性问题
同时 你了解该产品未来10年规划(相关电子书如下)
- File Systems Unit as Distributed Storage:Lessons from 10 Years of Ceph Evolution 过去10年发展历史
- Ceph: 20 Years of Cutting-Edge Storage at the Edge # Ceph:20年尖端的边缘存储技术
二、IO 栈分层优化
- 客户端拆锁
- 客户端纠删
- 存储池分层IO流程
- 操作系统优化
2.1 客户端
存在问题
- CephFS 客户端 并发方式时候,读写等操作使通一个全局锁,锁力度过大
- ceph 南北流量占用过大
解决办法
- CephFS 客户端 拆分,通过多个通道与存储池交互,自 Nautilus 版本起,
libcephfs支持多线程并发调用 - 元数据锁分片(MDS)
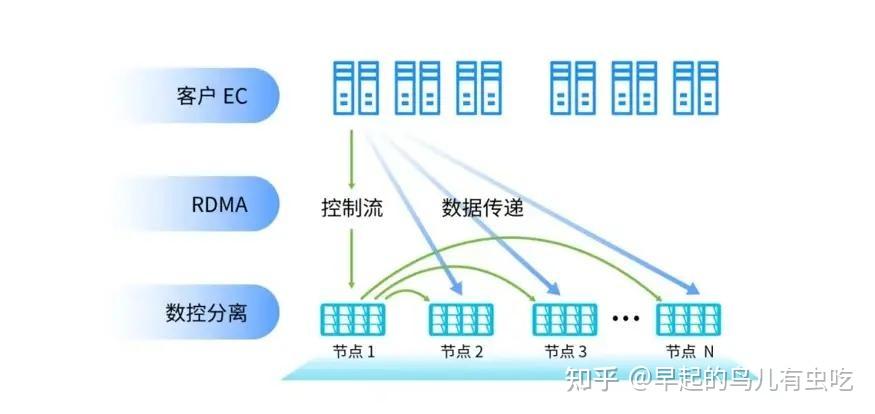
- **纠删EC与数控分离。缩短网络传输路径,对读写 都有优势
| 厂商 | 技术方案 | 关键指标 | 局限性 |
|---|---|---|---|
| 浪潮存储 | EC 12+4 + 数控分离 | 冗余度1.33,支持小IO加速 | 依赖自研智能调度引擎 |
| 阿里云盘古 | EC 8+3 + Stripe Placement | 冗余度1.375,适配对象存储 | 跨AZ修复带宽开销大 |
| Google Colossus | EC 6+3 + 动态条带 | 低冗余高可靠,深空通信优化 | 硬件依赖性强 |
| 普通以太网无缘RDMA?数控分离架构实现传输路径“零中转” |
- 通一个机柜 机架数据相互复制 【为什么做到,ceph配置有关系】
- CRUSH - 受控、可扩展、去中心化的复制数据放置
- CRUSH - Controlled, Scalable, Decentralized Placement of Replicated Data
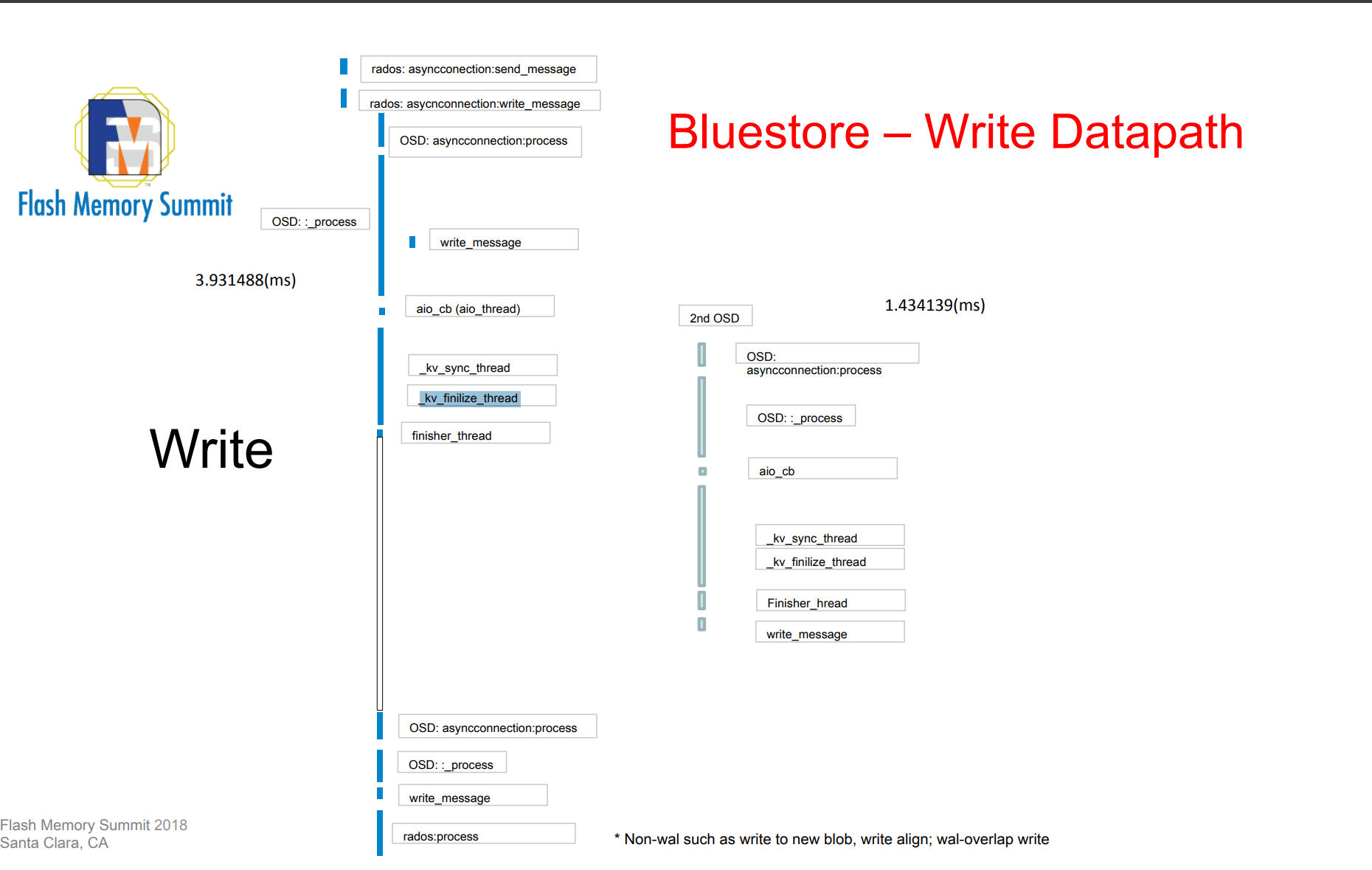
2.2 存储引擎: 先写数据,还是先写元数据?在返回客户端?
存在问题 写入慢
BlueStore 可以理解为一个支持 ACID 的本地日志型文件系统。 所有的读写都是以 Transaction 进行。
BlueStore 通过状态机的方式控制整个 IO 流程
通过 queue_transactions 接口封装 BlueStore 事务并驱动状态机执行。
BlueStore事务状态流转

STATE_PREPARE
- 该阶段主要是 IO 前的准备工作,如果是对齐 IO ,
- 置为 STATE_AIO_WAIT 并将数据提交到 aio ;
STATE_AIO_WAIT
- 该阶段等待 aio 的完成,
- aio 完成后在回调函数中将事务状态设置为STATE_IO_DONE 。
STATE_IO_DONE
- 该阶段完成对齐 IO 的处理,并对 IO 进行保序,保证 kv 事务的顺序性
- 按顺序设置事务状态为 STATE_KV_QUEUED ,将事务放入 kv_queue
STATE_KV_QUEUED
- 该阶段主要在 kv_sync_thread 线程中把 aio 的元数据或者延迟 IO 数据和元数 据写入 kv 数据库,并且将状态设置为 STATE_KV_SUBMITTED 。
- 然后将事务放入 kv_committing_to_finalize 队列,并通知 _kv_finalize_thread 线程处理。
STATE_KV_SUBMITTED
- 该阶段主要在 _kv_finalize_thread 线程中将状态设置为 STATE_KV_DONE 并 将回调函数放入 finisher 队列
- 在 finisher 线程中给客户端返回 oncommit 应答
KV写入批处理与并行化
- 问题:kv_sync_thread单线程写入KV数据库(如RocksDB),无法发挥NVMe SSD的IOPS潜力。
- 方案:
-
批量提交:在STATE_KV_QUEUED阶段合并多个事务的元数据,单次写入多条KV记录(利用RocksDB的WriteBatch)。
-
分片并发:按事务哈希分片到多个kv_sync_worker线程,并行写入不同KV分片。
-
效果:KV写入吞吐量提升3-5倍(参考阿里云盘古优化案例)。
-
io流程优化
- BlueStore IO 流程: Simple Write
- BlueStore IO 流程: Deferred Write
对于 deferred write 场景,延迟 IO 数据封装在 k/v 事务中,写入 kv 数据库 后给客户端返回应答,然后在后台执行延迟 IO 数据的写操作
Ceph BlueStore
Source:http://blog.wjin.org/posts/ceph-bluestore.html

- AioContext 写设备都是通过libaio,首先需要了解回调函数的执行流程。AioContext派生了两种context,TransContext和DeferredBatch,前者对应simple write,简称为txc,后者对应deferred write
- 对于用户或osd层面的一次IO写请求,到BlueStore这一层,可能是simple write,也可能是deferred write,还有可能既有simple write的场景,也有deferred write的场景
优化策略
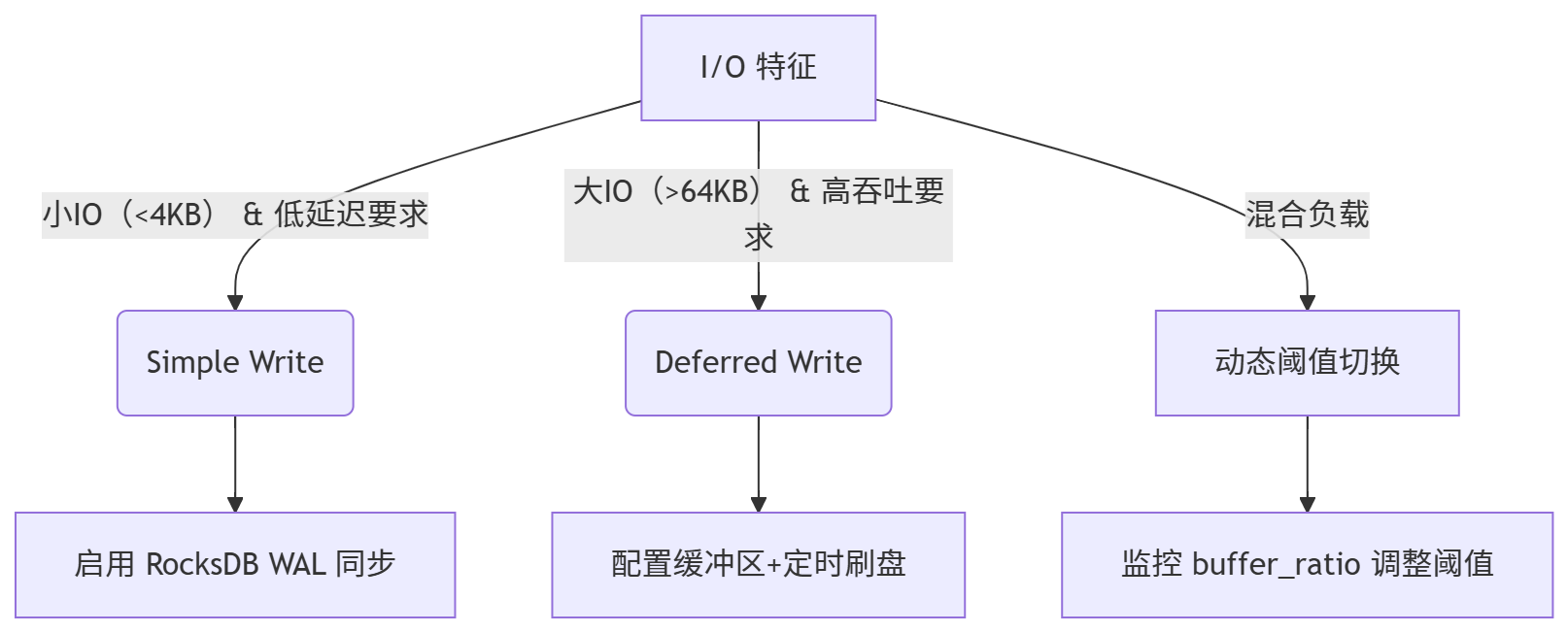
| 场景特征 | 推荐模式 | 原因与优化效果 | 风险与限制 |
|---|---|---|---|
| 小 I/O 随机写 | Simple Write | 避免缓冲区频繁刷新造成的碎片化,减少元数据更新压力(如 KV 事务竞争) | 高并发下 RocksDB WAL 可能成为瓶颈 |
| 大块顺序写 | Deferred Write | 批量合并写入减少磁盘寻址,吞吐量提升 3-5 倍(如视频流、备份数据) | 宕机时可能丢失未刷新的数据(需额外日志) |
| 低延迟事务型负载 | Simple Write | 实时刷盘保证 ACID,适用于数据库在线事务(OLTP) | 吞吐量受限,不适合高带宽场景 |
| 高吞吐批处理 | Deferred Write | 结合 AIO 回调与流水线技术,最大化 SSD 带宽利用率(如 AI 训练 checkpoint) | 需监控缓冲区溢出(OOM 风险) |
| 混合读写负载 | 动态切换 | 根据 I/O 大小阈值自动选择(如 4KB 以下用 Simple,以上用 Deferred) | 策略配置复杂,需压测调优 |
三 、操作系统优化与基准测试
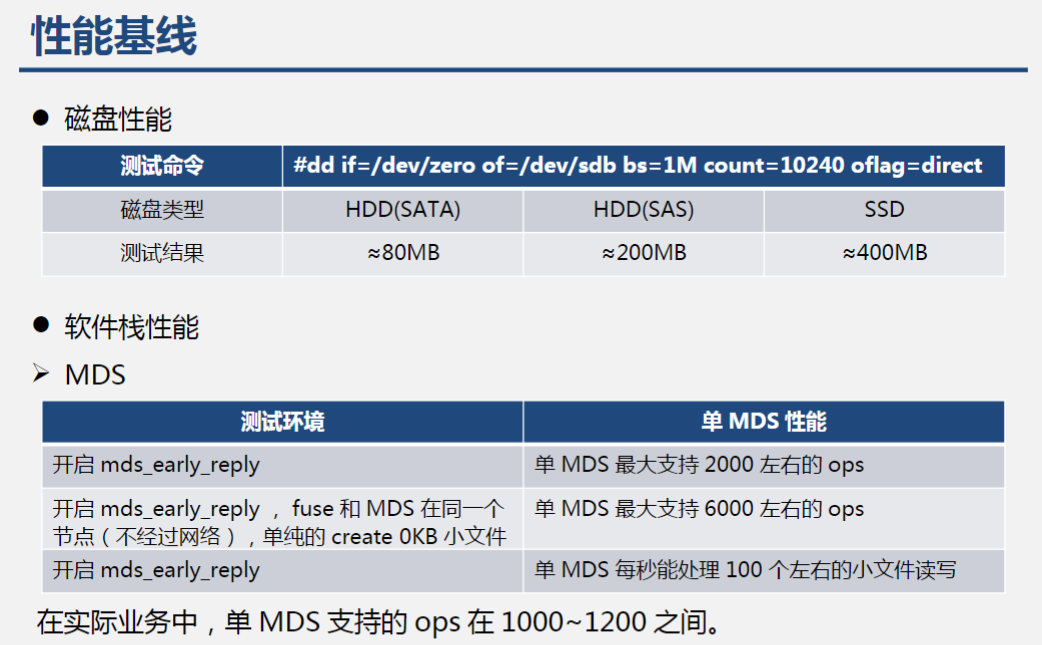
性能优化: CPU(多核架构)
- top
- mpstat
CPU每个核心CPU发生中断的数量查看 mpstat -P ALL 1 如果软中断集中在某一个核上,会导致 CPU 100%,影响整体性能
mpstat -P ALL mpstat - Report processors related statistics. -P { cpu_list | ALL } Indicate the processors for which statistics are to be reported
|
|
- 手动执行 echo 3 > /proc/sys/vm/drop_caches 会强制清空 Page Cache(文件缓存)和 Buffer Cache(块设备缓存)。
- 减少自旋锁最大重试次数(默认 4096) echo 1000 > /proc/sys/kernel/spin_retries
- [osd.0] bluestore_wal_path = /dev/nvme1n1 # 独立 WAL 设备
Buffer/Cache 缓存缓存过它线程加锁时阻塞,而内核模块用的都是自旋锁( _raw_spin_lock ),阻塞时间长了会导致 CPU 利用率变高
查看中断数高的CPU忙于处理哪些中断
命令:cat /proc/interrupts
|
|
查看网卡当前中断号绑定的CPU编号
cat /proc/irq/124/smp_affinity_list 查看绑定的CPU列表,(10进制表示)
## 将中断号绑定所有CPU
- echo 0,1,2,3 > /proc/irq/124/smp_affinity_lis
参考:https://www.cnblogs.com/zhangmingda/p/15196363.html
NUMA(Non-Uniform Memory Access)
运行 test_program 程序,参数是 argument,绑定到 node 0 的 CPU 和 node 1 的 内存 numactl –cpubind=0 –membind=1 test_program arguments
性能优化:内存
- 限制缓存个数
性能优化:磁盘
- 写入放大现象(WA: Write amplification)
- SSD与传统磁盘相比其有了很大的性能优势,以及较多的优点,但是事物总是有两面性的,擦除块之前需要将原有的还有效的数据先读出,然后在与新来的数据一起写入,
- 举个最简单的例子:当要写入一个4KB的数据时,最坏的情况是一个块里已经没有干净空间了,但有无效的数据可以擦除,所以主控就把所有的数据读到缓存,擦除块,缓存里 更新整个块的数据,再把新数据写回去,这个操作带来的写入放大就是: 实际写4K的数据,造成了整个块(共512KB)的写入操作,那就是放大了128倍。
- EC条带未对齐导致读改写
- 第二层写放大:FileStore的clone_range机制冗余操作
问题触发条件
修改写(非追加写)触发FileStore的clone_range流程:
-
克隆对象:创建临时副本(_touch + _clone_range);
-
修改原对象:写操作施加于临时对象;
-
清理:删除旧对象并重命名临时对象(_remove + _collection_move_rename)。
此过程引入额外I/O(读克隆对象、写临时对象、删旧对象)。
- 如果通过 iotop 命令发现磁盘是因为写 journal 或访问 Leveldb/Rocksdb 引起的压力大,可以将 journal 和 omap 数据迁移到 SSD 上。
性能优化: 网络
- 万兆链路链路检测 : iperf –c
- 检查网口速度 ethtool
- 检测当前节点网络是否存在大量错包,丢包,重传 netstat -i | column -t
sar -n ETCP 1 -
retrans/s:每秒重传的 TCP 段数量- > 0 值:表明网络丢包(发送方未收到 ACK 触发重传)。
- 健康参考:
< 1:可接受(短时波动/正常丢包)。> 1持续存在:可能网络拥塞或链路故障。
-
atmptf/s:每秒失败的 TCP 连接尝试次数(如 SYN 超时)> 0表示握手失败(可能防火墙拦截、服务器过载或网络不通)。
-
estres/s:每秒被重置的 TCP 连接数(如意外断开)> 0表明连接异常终止(可能服务端错误或攻击)。
-
isegerr/s:每秒接收的错误 TCP 段数量(校验和错误等)> 0表示链路层错误(物理故障、驱动问题或干扰)
- ethtool -g 网卡名称,显示网卡的接收/发送环形参数
最动人的作品,为自己而写,刚刚好打动别人
我在寻找一位积极上进的小伙伴,
一起参与神奇早起 30 天改变人生计划,发展个人事情,不妨 试试
1️⃣ 加入我的技术交流群Offer 来碗里 (回复“面经”获取),一起抱团取暖
 2️⃣ 关注公众号:后端开发成长指南(回复“面经”获取)获取过去我全部面试录音和大厂面试复盘攻略
2️⃣ 关注公众号:后端开发成长指南(回复“面经”获取)获取过去我全部面试录音和大厂面试复盘攻略
 3️⃣ 回复 面经 获取全部电子书 或者购买正版书籍
3️⃣ 回复 面经 获取全部电子书 或者购买正版书籍
—————-我是黄金分割线—————————–
抬头看天:走暗路、耕瘦田、进窄门、见微光,
- 我要通过技术拿到百万年薪P7职务,打通任督二脉。
- 但是不要给自己这样假设:别人完成就等着自己完成了,这个逃避问题表现,裁员时候别人不会这么想。
低头走路:
- 一次专注做好一个小事。
- 不扫一屋 何以扫天下,让自己早睡,早起,锻炼身体,刷牙保持个人卫生,多喝水 ,表达清楚 ,把基本事情做好。