2分钟论:让网卡写磁盘,这项专利彻底绕过了 CPU!

文章目录
声明:文章涉及的数据和方案 均来官方公布的数据, 如有偏差,属于个人理解有误。
基于一次只解决一个事情的原则 本文重点描述 专利:分布式存储数据的传输方法、装置、系统、设 备和介质

在思考一个小问题: 你会怎么选?
你下单了一件 9.9 元的小东西,只是个数据线。
请问,你更愿意选择哪种送货方式?
A. 派一架专机、一个快递员全程护送,送货上门、签字确认,享受 1 对 1 至尊服务。
B. 凑满几件一起走菜鸟驿站,快递员批量处理,自己跑一趟拿,虽然累点,但不贵。
选择A.反常识 但对于系统设计者来说,这种思路就是在用极度昂贵的资源处理微小的数据请求
选 B 就是——批量处理、小数据聚合,统一落盘,延迟略高但系统资源利用更好。 缺点:但是累人呀,每天爬楼梯,夏天取快递。一个还好说,要是100件呢
为什么这样设计?
随着全闪技术的发展,闪存的容量做的越来越大,价格越来越低,全闪存储逐步成为大众客户考虑的范畴。
尤其是在人工智能(ArtificialIntelligence,AI)场景对于带宽和每秒操作数(OperationsPerSecond,OPS)要求比较高的高性能计算(HighPerformanceComputing,HPC)场景中,全闪更是成为首选。
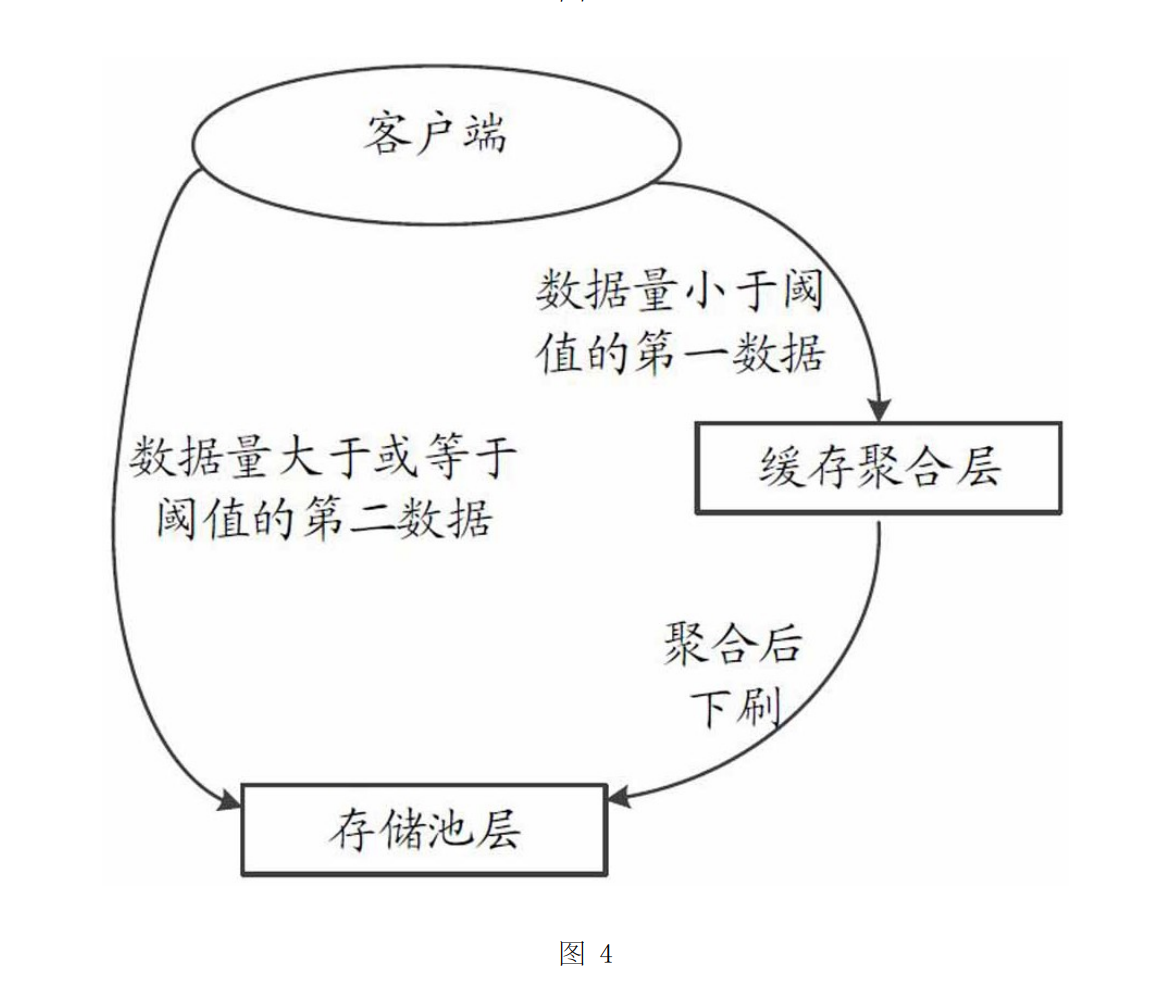
在全闪存储产品中,远程直接数据存取(RemoteDirectMemoryAccess,RDMA)技术是比较常用的技术,数据跨节点传输卸载到RDMA网卡中,极大减少中央处理器(CentralProcessingUnit,CPU)接入,但是接收或者发送仍然需要主机内存的介入,落盘时由主机内存通过直接存储器访问(DirectMemoryAccess,DMA)方式拷贝到盘的内存里然后落盘。
主机内存拷贝过程,对带宽需求量高,产生的时延也较高,导致数据传输效率偏低。可见,如何提升数据传输效率,是本领域技术人员需要解决的问题。
-
减少了频繁的主机内存拷贝(对小数据来说特别浪费);
-
避免了CPU频繁介入处理琐碎小请求;
-
提高了系统吞吐(OPS)和整体资源利用率;
-
兼顾了**低延迟(NVRAM 缓存)与高带宽(NVMe)**的性能特征
《CN117573043B》的解法:按“数据大小”走不同路径!
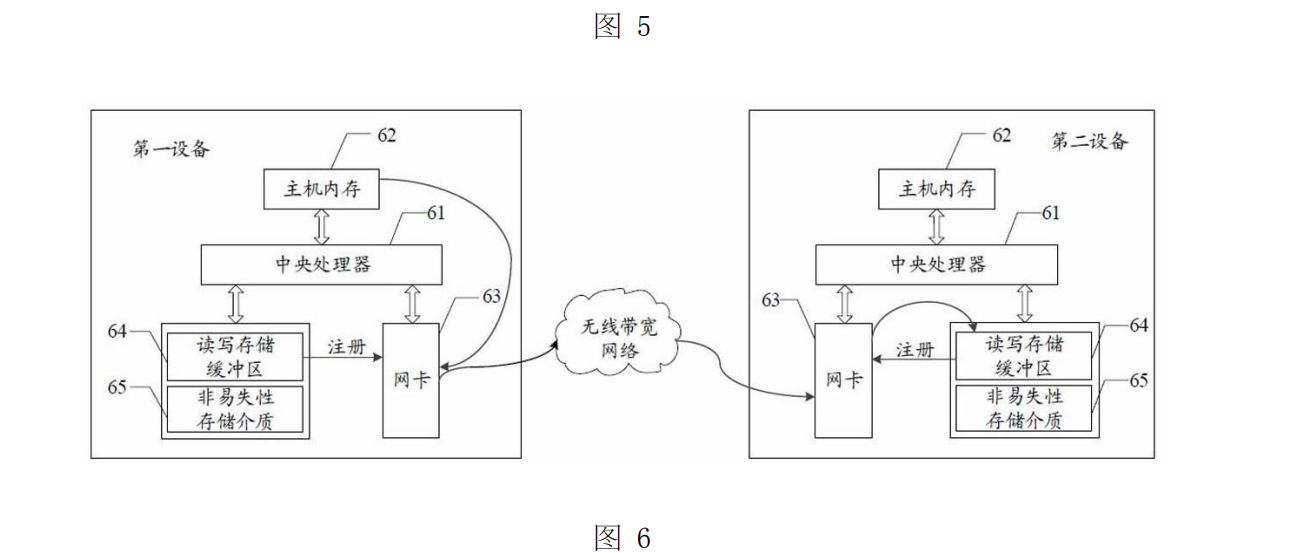
这项专利提出了一个非常巧妙的数据分流机制:
根据写入数据量的大小,选择不同的缓存层存储路径:
| 数据类型 | 存储策略 | 缓存设备 | 落盘时机 |
|---|---|---|---|
| 小数据(如元数据、日志、数 KB 级) | 存入第一缓存设备(NVRAM) | 类似“快递暂存点” | 批量聚合后落入主存储 |
| 大数据(如模型文件、图像块) | 直接写入第二缓存设备(NVMe 介质) | ||
一、前置知识
1.1 这是什么业务场景?文件跨网络传输
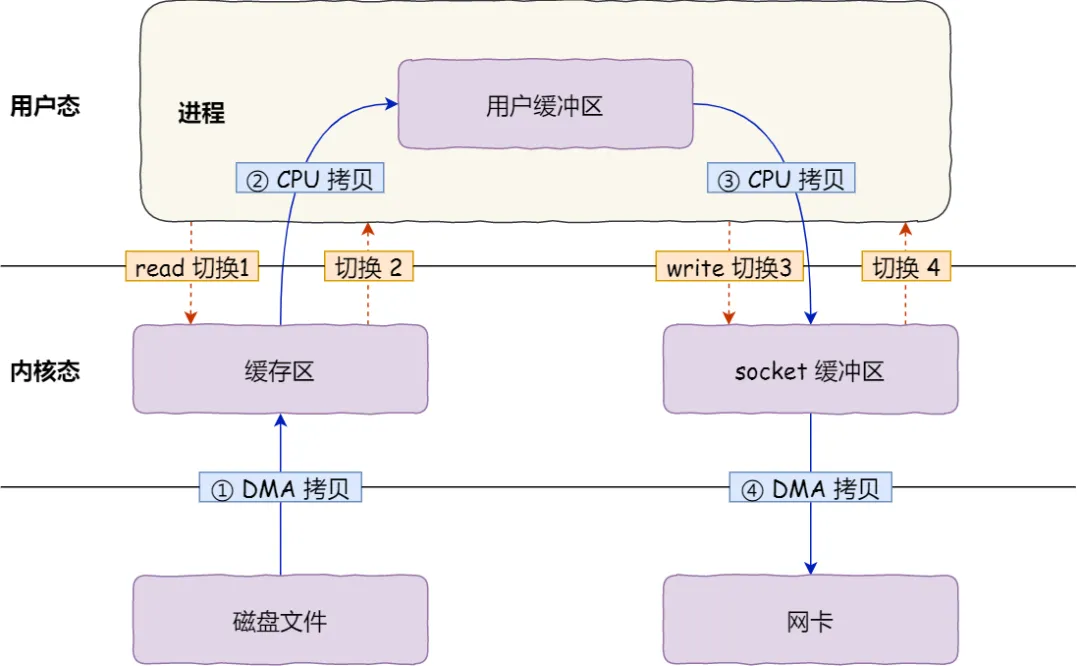
1.2 如何理解虚拟内存?黑科技 把SSD当内存用
- 根据csapp 定义 虚拟内存让每个程序都觉得自己拥有独立的大内存,其实背后是操作系统偷偷把磁盘当成内存的一部分用 ,内存是磁盘缓存,ssd是hdd判断缓存
- 在Linux下,使用SSD为HDD加速,目前较为成熟的方案有:flashcache,enhanceIO,dm-cache,bcache等,多方面比较以后最终选择了bcache。 bcache 是一个 Linux 内核块层超速缓存。它允许使用一个或多个高速磁盘驱动器(例如 SSD)作为一个或多个速度低得多的硬盘的超速缓存
1.3 如何网卡控制器(NIC Controller)和磁盘控制器(Disk Controller)?磁盘有缓存(DRAM 或 CMB)
| 类比角色 | 网卡 | 磁盘 |
|---|---|---|
| 像什么? | 快递员 | 仓库 |
| 负责什么? | 把数据从 A 搬到 B | 把数据存起来、随时取用 |
| 有缓存吗? | 有,供收发暂存用 | 有,供 IO 聚合用 |
| 掉电怎么办? | 数据会丢 | 高端 SSD/CMB 有电容保电设计,避免丢数据 |
| 项目 | 网卡(NIC) | 磁盘(Disk) |
| 功能 | 网络通信(发送/接收数据包) | 数据持久化存储(读写文件块) |
| 控制器 | 网卡控制器(MAC + PHY) | 磁盘控制器(SATA, NVMe 等) |
| 总线协议 | PCIe,Ethernet,InfiniBand | SATA,SAS,NVMe(PCIe) |
| 数据源 | 来自 CPU/内存/其他主机的网络数据 | 来自主机进程的文件/块读写请求 |
| 访问方式 | DMA 或 RDMA(远程) | DMA,NVMe queue,IO调度器 |
| 典型软件接口 | socket / RDMA verbs | 文件系统 / 块设备 / IO stack |
| 常见延迟 | 微秒级 | 毫秒(HDD)~微秒(NVMe SSD) |
| 目标 | 快速传输 | 安全落盘 |
控制器和缓冲区的差异
✅ 网卡控制器(NIC Controller)
-
控制数据包收发、校验、队列;
-
支持 DMA 或 RDMA 方式将数据从/写入内存;
-
高端网卡支持 zero-copy,可绕过 CPU 和主内存(CMB、DDIO);
-
没有持久化能力(掉电就丢)。
✅ 磁盘控制器(Disk Controller)
-
管理 数据在磁盘介质(HDD、SSD)上的读写;
-
有内部调度队列、缓存(DRAM 或 CMB);
-
NVMe 控制器支持多队列、低延迟、高并发;
-
数据最终会落盘(持久化),有 FTL(闪存转换层)或机械磁头调度
二、专利简化理解
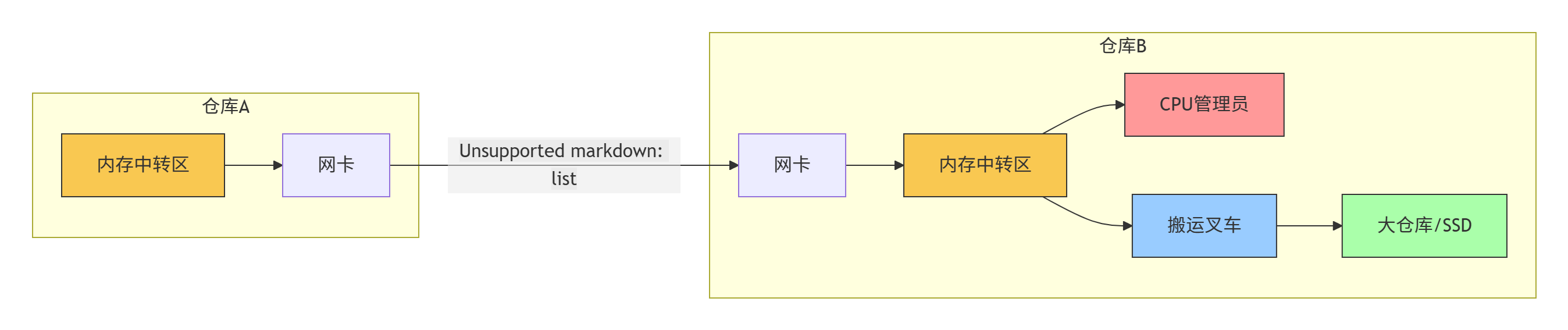
场景: 两个数据中心节点(仓库A和仓库B)之间需要高速传输数据(搬运货物)。
🚚 第一阶段:传统方式(慢速路径)
-
数据从仓库A出发: 数据首先放在仓库A的内存中转区(黄色)。
-
装车: 仓库A的网卡把数据装车。
-
运输: 卡车通过高速路(InfiniBand)运到仓库B的网卡。
-
卸货到中转区: 仓库B的网卡把数据卸到仓库B的内存中转区(黄色)。
-
管理员处理: CPU管理员(红色) 发现中转区有货,发出指令。
-
叉车搬运: 搬运叉车(蓝色) 根据指令,把数据从内存中转区搬到最终大仓库/SSD(绿色)。
- 瓶颈: 步骤4和5需要时间和CPU资源,尤其当小包裹很多时(高OPS),管理员(CPU)和叉车(内存拷贝)忙不过来,造成拥堵延迟。
-
场景1:海量小包裹涌入 (高OPS场景)
- 传统方式: 卡车源源不断到达仓库B门口。每辆车都要排队进中转区卸货,CPU管理员和叉车忙得满头大汗,处理速度跟不上,门口排起长龙(高延迟)。
传统方式: 卡车源源不断到达仓库B门口。 每辆车都要排队进中转区卸货,CPU管理员和叉车忙得满头大汗,处理速度跟不上,门口排起长龙(高延迟)。 - 专利方式: 卡车到达后,网卡司机看一眼包裹大小(小件),立刻精准投递到旁边的小件快速处理区,然后马上掉头去拉新货。小件区快速接收、记录、备份。理货员在后台有条不紊地将攒够的小包裹批量送到大件区或大仓库。门口畅通无阻(高OPS,低延迟)。
- 传统方式: 卡车源源不断到达仓库B门口。每辆车都要排队进中转区卸货,CPU管理员和叉车忙得满头大汗,处理速度跟不上,门口排起长龙(高延迟)。
-
场景3:AI训练 GPU -> 存储
- GPU(高性能图形处理器,产生海量数据)需要快速保存数据。
- 专利方式: GPU直接叫来网卡司机(调用驱动),告诉司机:“数据在我这里,地址是XXX”。网卡直接从GPU“装货”,然后通过高速路直达远程仓库的CMB临时存放区。完全不经过本地的CPU和内存中转区,GPU可以立刻继续计算。效率极高!
专利方式: GPU直接叫来网卡司机(调用驱动),告诉司机:“数据在我这里,地址是XXX”。 网卡直接从GPU“装货”,然后通过高速路直达远程仓库的CMB临时存放区。 完全不经过本地的CPU和内存中转区,GPU可以立刻继续计算。 效率极高!
⚡ 第二阶段:专利方法(CMB直达快车道)

🔧 关键升级:仓库B内部改造
-
直达临时存放区 (CMB): 仓库B在网卡旁边开辟了自带备用电源的临时存放区 (橙色)。仓库B的管理员(CPU)提前把这里的地址告诉了网卡司机。
-
智能理货员 (用户态驱动): 新增了一个高效的理货员(绿色),专门负责从临时存放区把货整理进大仓库。
🚀 高速直达流程
- 数据从仓库A出发: 仓库A网卡装车(数据可以直接从仓库A的CMB或内存出发)。
- 运输: 卡车通过高速路直达仓库B。
- 直达卸货!: 仓库B的网卡司机不再去中转区!它根据货物大小:
- 小包裹: 直接送到小件快速处理区(CMB的一部分/NVRAM,见下文)。网卡卸完货立刻返回拉新货!
- 大件货: 直接送到大件主存储暂存区(CMB的另一部分)。网卡卸完货立刻返回拉新货!
- 理货员处理: 理货员(用户态驱动) 在后台工作:
- 监控小件快速处理区,等小包裹攒够一车(达到条带大小),就打包送入大件主存储暂存区或直接搬进大仓库。
- 将大件主存储暂存区的货物搬进最终大仓库/SSD(绿色)。
- 仓库管理员解放: 仓库B的CPU管理员(红色) 只负责协调通知(比如告诉仓库A货在哪儿),完全不参与具体的卸货和搬运!工作量大大减少。
- 临时存放区复用: 货物搬空后,临时存放区空间被释放,等待新货物。
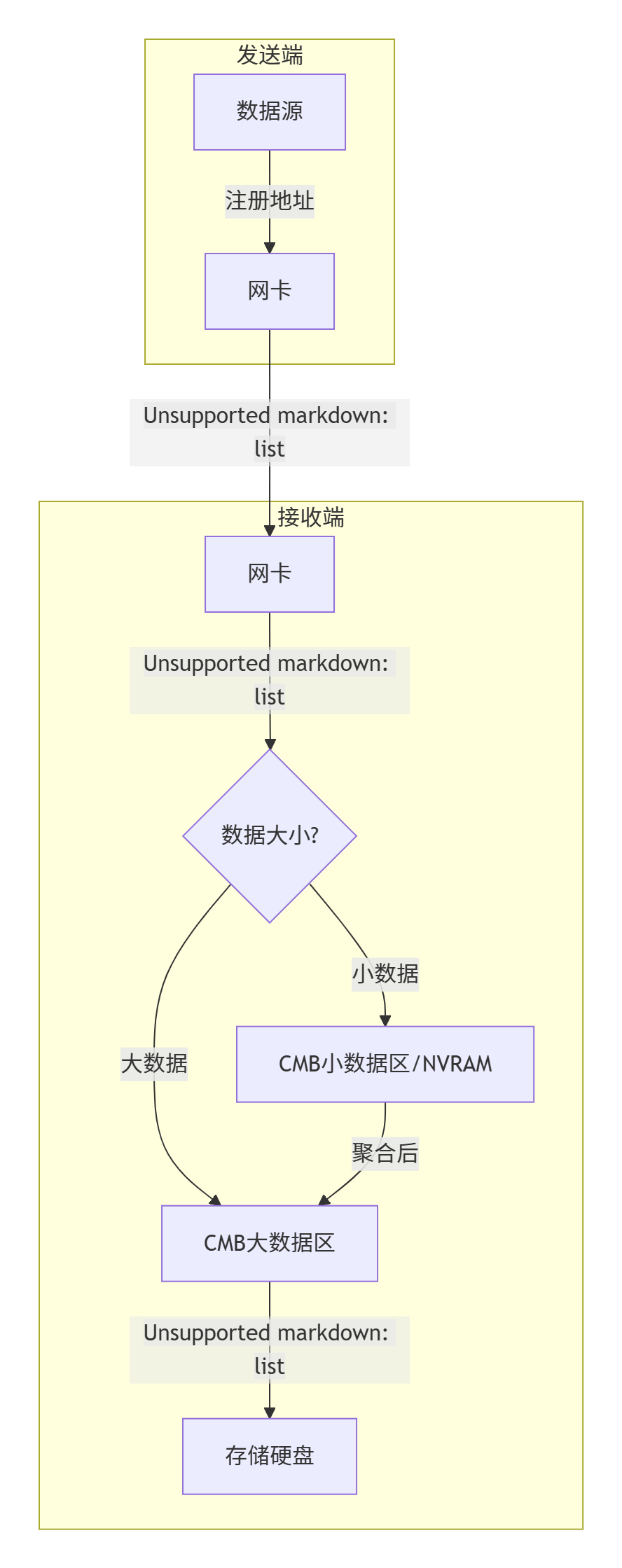
三、 专利解决方案:CMB直达架构
3.1 CMB直达架
- 硬件层:使用带电容保电的CMB内存(ssd盘上读写存储缓冲区),断电不丢数据。
- 路径层:网卡直连CMB,绕过主机内存和CPU。
- 逻辑层:
- 分层缓存:CMB分为小数据区(NVRAM)和大数据区
- 用户态驱动:异步处理数据落盘,不阻塞传输
关键步骤说明:
① 网卡直达CMB → ② 按数据尺寸分流 → ③ 后台落盘不阻塞
3.2 小数据区
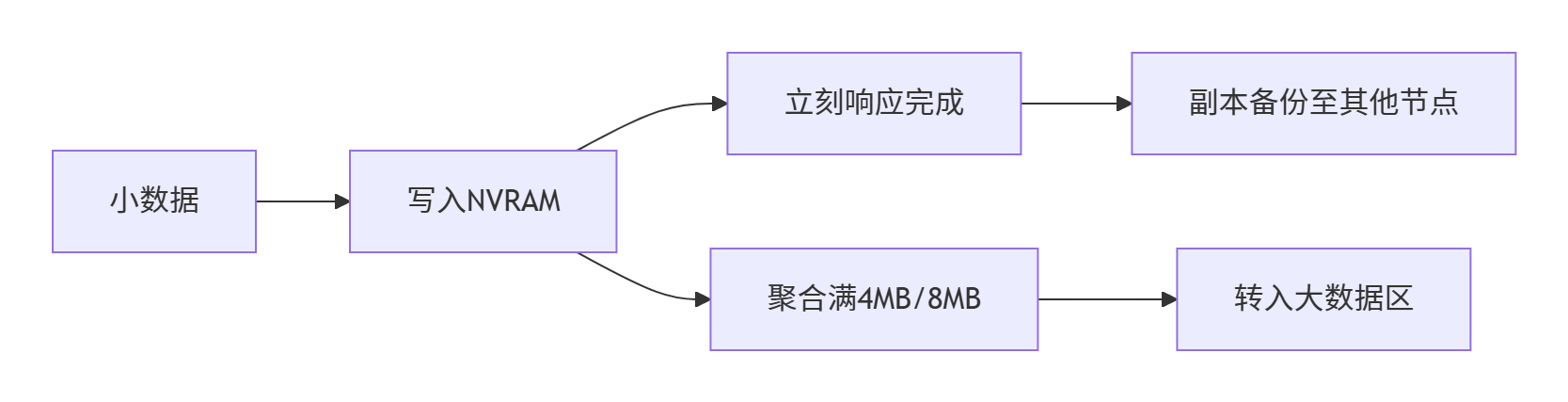 功能:
功能:
✅ 极速响应(微秒级)
✅ 三副本容错
✅ 专设元数据VIP通道(存储高频操作日志)
3.3 大数据
 功能:
功能:
✅ 并行写入提升吞吐
✅ 纠删码减少存储开销
| 指标 | 传统方式 | 专利方案 | 提升幅度 |
|---|---|---|---|
| 小数据延迟 | 100μs | 20μs | 5倍 |
| CPU占用率 | 70% | <15% | 80%↓ |
| 带宽利用率 | 60% | >90% | 50%↑ |
| OPS(每秒操作数) | 50万 | 200万+ | 4倍 |
最动人的作品,为自己而写,刚刚好打动别人
我在寻找一位积极上进的小伙伴,
一起参与神奇早起 30 天改变人生计划,发展个人事情,不妨 试试
1️⃣ 加入我的技术交流群Offer 来碗里 (回复“面经”获取),一起抱团取暖
 2️⃣ 关注公众号:后端开发成长指南(回复“面经”获取)获取过去我全部面试录音和大厂面试复盘攻略
2️⃣ 关注公众号:后端开发成长指南(回复“面经”获取)获取过去我全部面试录音和大厂面试复盘攻略
 3️⃣ 感兴趣的读者可以通过公众号获取老王的联系方式。
3️⃣ 感兴趣的读者可以通过公众号获取老王的联系方式。
—————-我是黄金分割线—————————–
抬头看天:走暗路、耕瘦田、进窄门、见微光,
- 我要通过技术拿到百万年薪P7职务,打通任督二脉。
- 但是不要给自己这样假设:别人完成就等着自己完成了,这个逃避问题表现,裁员时候别人不会这么想。
低头走路:
- 一次专注做好一个小事。
- 不扫一屋 何以扫天下,让自己早睡,早起,锻炼身体,刷牙保持个人卫生,多喝水 ,表达清楚 ,把基本事情做好。