浪潮AS13000分布式存储在医疗影像场景中如何优化小文件IO性能

文章目录
声明:文章涉及的数据和方案 均来官方公布的数据,如有偏差,属于个人理解有误。
基于一次只解决一个事情的原则 本文重点描述 数控分离特征
一、背景信息
海量小文件的元数据管理、存储性能以及访问效率等问题是目前学术界和工业界公认的难题。
浪潮AS13000软件定义存储系统利用包括小文件聚合功能在内的独特技术, 帮助用户应对存储资源浪费、效率低下等诸多挑战, 成就大数据与人工智能时代的企业核心竞争力
浪潮AS13000分布式存储在医疗影像场景实践案例
| 医院/场景 | 核心问题 | 解决方案 | 关键技术 | 性能提升效果 |
|---|---|---|---|---|
| 南华大学附属第二医院 (3D PACS影像) | • 单次检查生成1000~2000个小文件(63%为200-300KB) • 深目录层级导致元数据瓶颈 • 高峰期“图片喷涌式上传” | • 目录分片技术哈希切分深层路径• 小文件聚合写入:合并为64MB大对象,4MB对齐落盘 • 双活容灾 | 1. 元数据分布式管理 2. SSD写放大优化 3. 故障自动切换 | • 访问延迟<1ms • 单目录支持十亿级文件无性能衰减 • 3D影像加载效率提升50% |
| 浙江省人民医院 (PACS热冷数据分层) | • 年增数百TB影像数据 • 需兼顾1年内热数据高速访问与长期冷数据低成本存储 | • 分层存储架构- •热数据:全闪存储HF5000(NVMe架构) - 冷数据:AS13000(8+2纠删码) • 独立资源池隔离PACS业务 | 1. 智能数据迁移策略 2. 纠删码空间利用率80% 3. QoS保障关键业务 | • 热数据调阅延迟≤5ms • 冷数据归档效率10GB/s • 双活故障切换前端无感知 |
| 武汉大学中南医院 (CT影像高并发) | • 日均数万幅CT影像(单文件几十MB) • PB级数据长期存储 • 520+台设备并发写入压力大 | • 5节点高密部署(35盘位/节点) • 小文件聚合技术:200-300KB文件合并写入 • 三副本冗余保障安全 | 1. 高密节点设计 2. 批量写入减少IO次数 3. 线性扩展架构 | • 影像调阅时间≤15秒(原分钟级) • 支持520+设备并发写入 • 单目录千万文件无衰减 |
| MLPerf™ AI测试平台 (3D-Unet医疗模型训练) | • 训练数据加载慢导致GPU闲置 • 检查点开销占训练时间12%~43% • 万卡集群存储带宽瓶颈 | • 数控分离架构数据面直通NVMe SSD • 内核亲和调度NUMA感知优化,IO线程绑定同节点 • RDMA网络加速 | 1. 控制面/数据面解耦 2. 跨节点数据转发量降低80% 3. 本地NUMA内存访问 | • 集群聚合带宽360GB/s • 单节点峰值120GB/s • GPU利用率90%+,I/O开销占比<10% |
文件存储技关键技术说明
1. 聚:小文件聚合减少IO次数(性能提升核心);
- 通过将KB级小文件合并为64MB大对象写入,减少元数据操作与磁盘IO次数,写入效率提升96.8%(128KB文件测试
- 4MB对齐落盘**:适配SSD物理块大小,降低写放大,提升删除/重构性
2. 分:分层存储架构
- 热数据层采用全闪存(NVMe SSD),延迟≤5ms;
- 冷数据层使用纠删码(如8+2),空间利用率达80%,成本降低40%
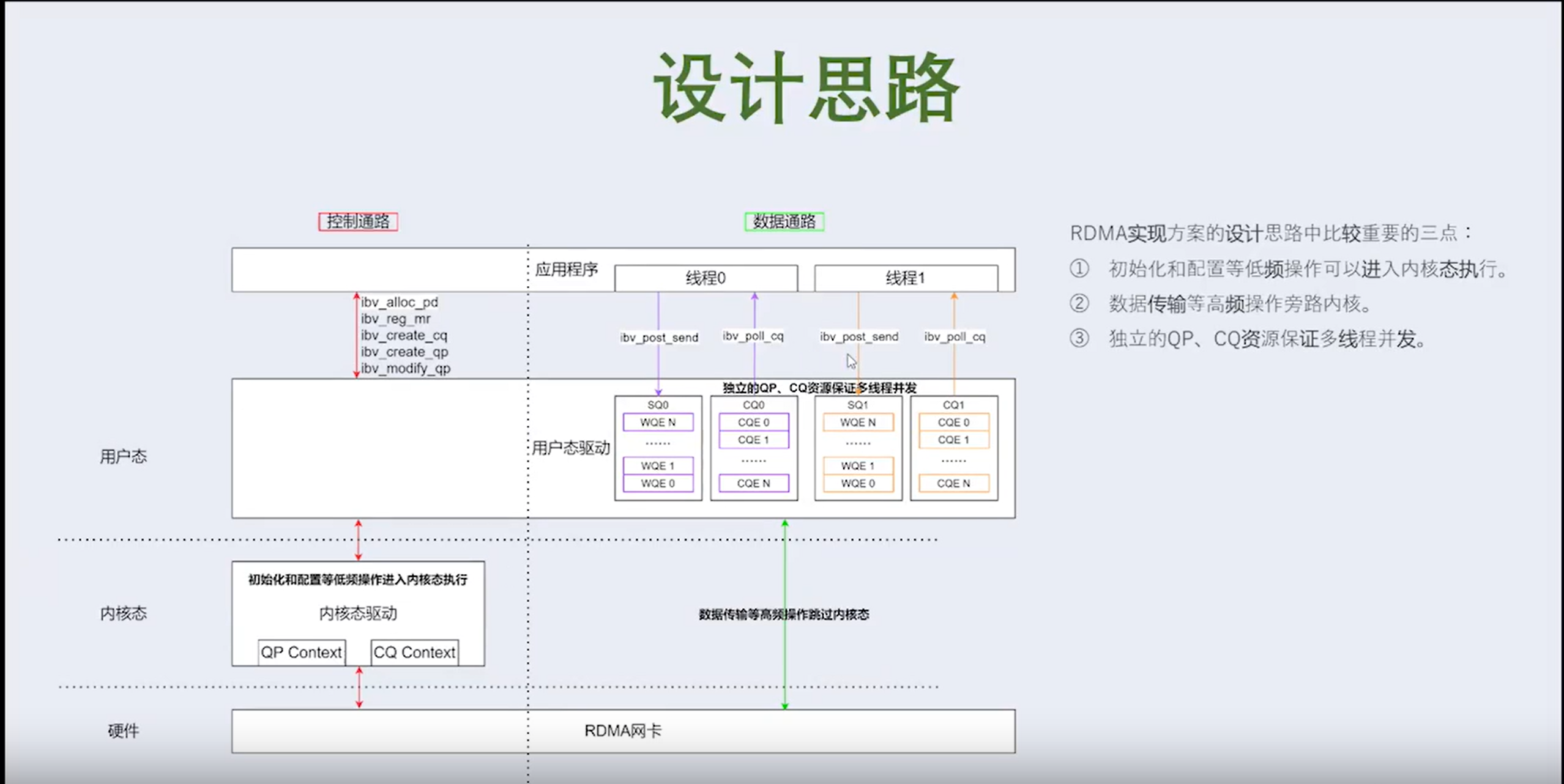
3. 通:数据通路和控制通路分离【重点描述】
- 通:数控分离+直通存储缩短数据路径
- 采用全新数控分离架构。 数据面和控制面完全解耦,控制面实现数据管理和访问,数据面读写操作直通到盘,达到120 GB/s的单存储节点的超高性能,单存储节点支撑5台8卡计算节点规模,同时计算集群GPU利用率90%以上
- 为了降低跨NUMA访问带来的时延,在全新数控分离架构下,使内核客户端可自主控制数据页缓存分配策略并主动接管用户下发的IO任务。这种方式能够更加灵活地实现各类客户端内核态到远端存储池的数据移动策略。
4. 拆:
- 目录分片技术通过哈希算法分散深目录压力,支持单目录十亿级文件无性能衰减
- 无论是读操作还是写操作,AS13000G7-N采取了字节级(Byte)分布式锁机制,粒度是主流并行文件系统锁机制粒度的几十分之一。
材料补充:AS13000G7存储取得MLPerf佳绩(扩展阅读)
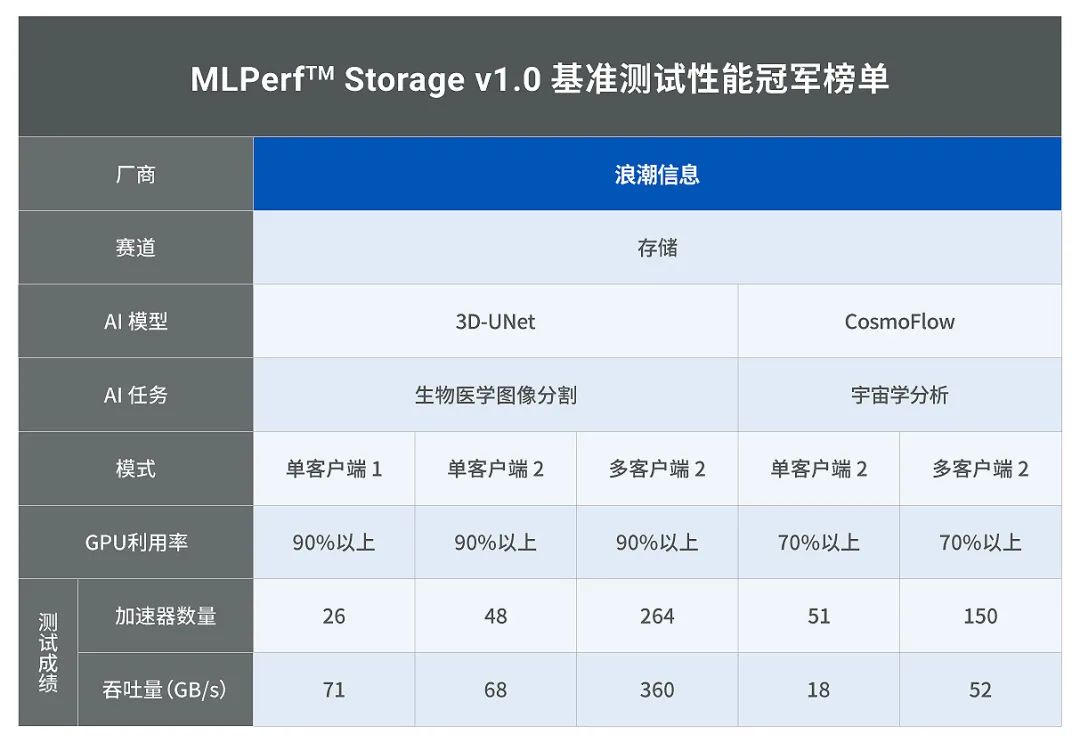
最新发布的MLPerf AI存储基准评测中,浪潮信息分布式存储平台****AS13000G7通过一系列创新技术,显著提升数据处理效率,勇夺8项测试中5项性能最佳成绩,实现集群带宽360GB/s、单节点带宽达120GB/s
- MLPerf™ 是影响力最广的国际AI性能基准评测,由图灵奖得主大卫•帕特森(David Patterson)联合顶尖学术机构发起成立。2023年推出MLPerf™ 存储基准性能测试,旨在以架构中立、具有代表性和可重复的方式衡量机器学习(ML)工作负载的存储系统性
- 本次MLPerf™ 存储基准评测(v1.0)吸引了全球13家领先存储厂商和研究机构参与。该评测围绕医学影像分割、图像分类、宇宙学参数预测三大AI存储应用场景,采用主流的3D-Unet、ResNet50、CosmoFlow三类模型
- 本次测试,浪潮信息采用3台AS13000G7搭建分布式存储集群,搭载ICFS自研分布式文件系统,在3D-UNet和CosmoFlow两大评测任务中共获得五项最佳成绩。 其中,在图像分割3D-UNet多客户端2评测任务中,服务于10个客户端264个加速器,集群聚合带宽达到360GB/s,单个存储节点的带宽高达120GB/s; 在宇宙学分析CosmoFlow单客户端2和多客户端2评测任务中,分别提供了18 GB/s和52 GB/s的带宽最佳成绩。
疑问:为什么最差18G最高360G差别是什么?
 硬件方面
硬件方面 - AS13000G7-N是一款2U24盘位的全闪存储机型
- 搭载英特尔®至强®第四、第五代可扩展处理器,
- 支持400 Gb 网卡
- 同时每盘位可配置15.36TB 大容量NVMe SSD。 软件方面
- 通过集群控制服务将N个节点联成一套具有高扩展性的文件系统;
- 通过分布式元数据服务提升海量小文件读写性能;
- 通过数控分离架构,实现东西向网络优化,降低IO访问时延,提升单节点带宽。
- 浪潮信息基于计算和存储协同的理念,依托自研分布式文件系统构建了新一代数据加速引擎DataTurbo,在缓存优化、空间均衡、缩短GPU与存储读取路径等方面进行了全面升级 【不是文件系统领域范围】
二、小文件聚合技术(简单了解)
2.1 可视化演示: 合并写入减少IO次数
-
聚合前:

-
聚合后:
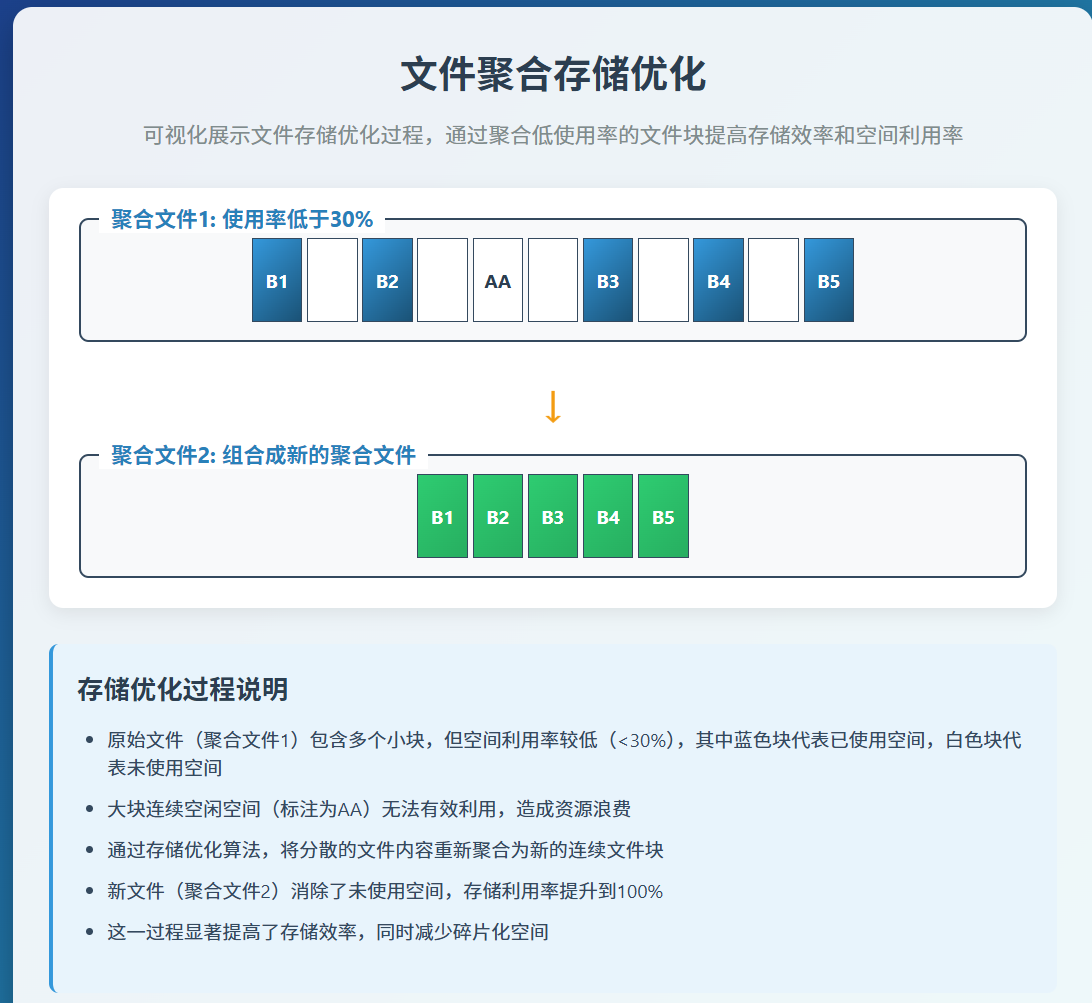
2.2小思考: 假如从0实现一个聚合功能,需要考虑哪些功能呢?
提问1:什么时候开始聚合?(类比lsm)
- 第一层: 根据数据生命周期管理,自然写SSD盘不需要聚合,直接读写(100万+ IOPS)
- 第二层:数据不经常访问,移动机械硬盘 HDD 进行 聚合大文件。
- 第三层:数据经常不访问,备进行归档处理。,继续聚合更大文件。
提问2:普通的文件和聚合文件怎么区分?
- 肯定保持到文件元数据中
- xattr 是文件扩展属性全称是一种以key-value 保存数据到文件系统中的技术。接口函数
|
|
- 大小有区别,小文件会以 4K 对齐方式写入 4M 块,聚合大文件最大 512M
- 3fs 都512k对齐写入,一看就是使用libaio库
- 从青铜到王者系列:跟着文件系统学数据结构
提问3:迁移接单故障怎么处理,做到无状态
- 将迁移结果持久化存储
三、数控分离(重点)
参考专利:# 一种分布式存储减少数据转发的方法、装置、设备及介质

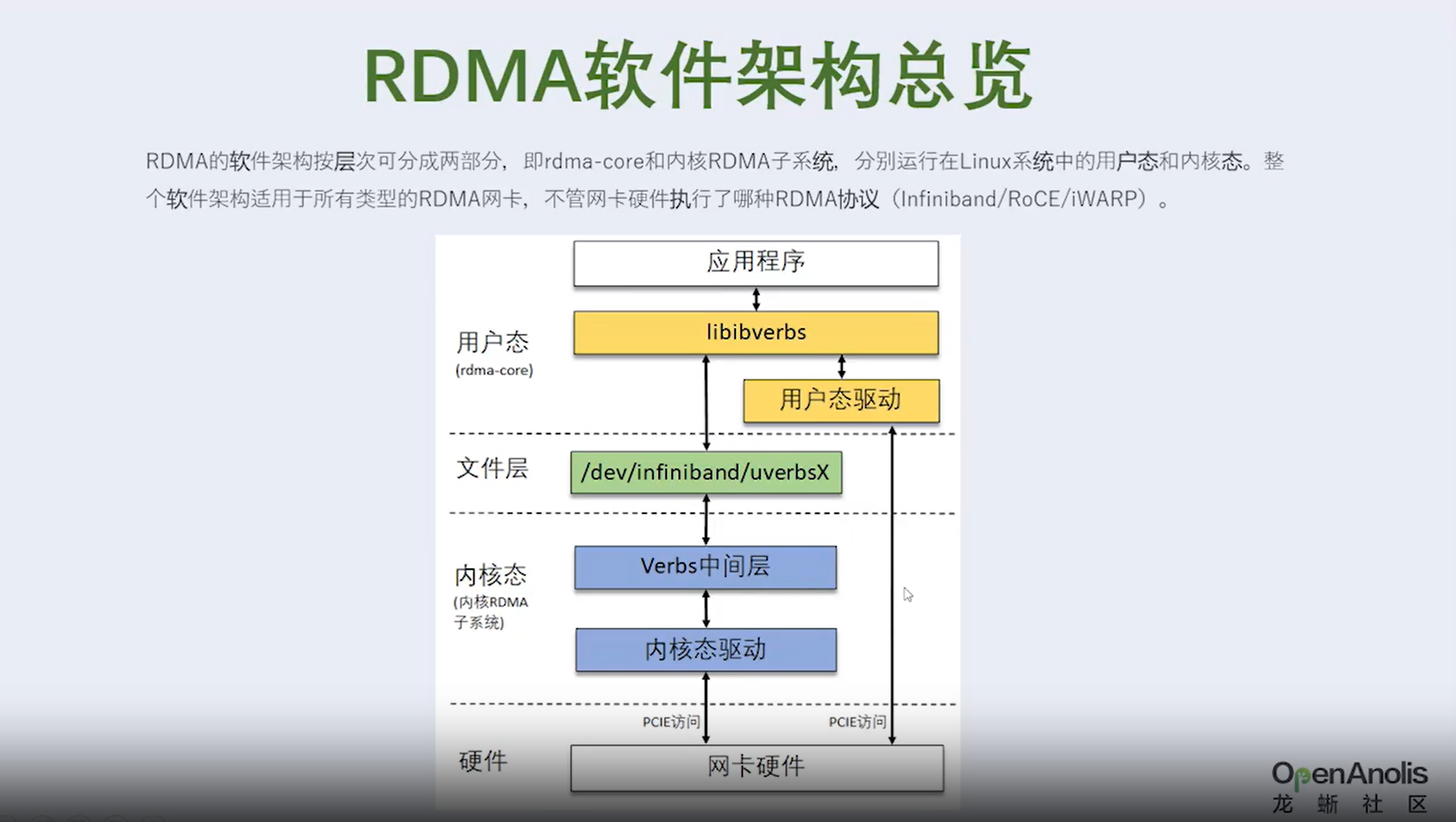
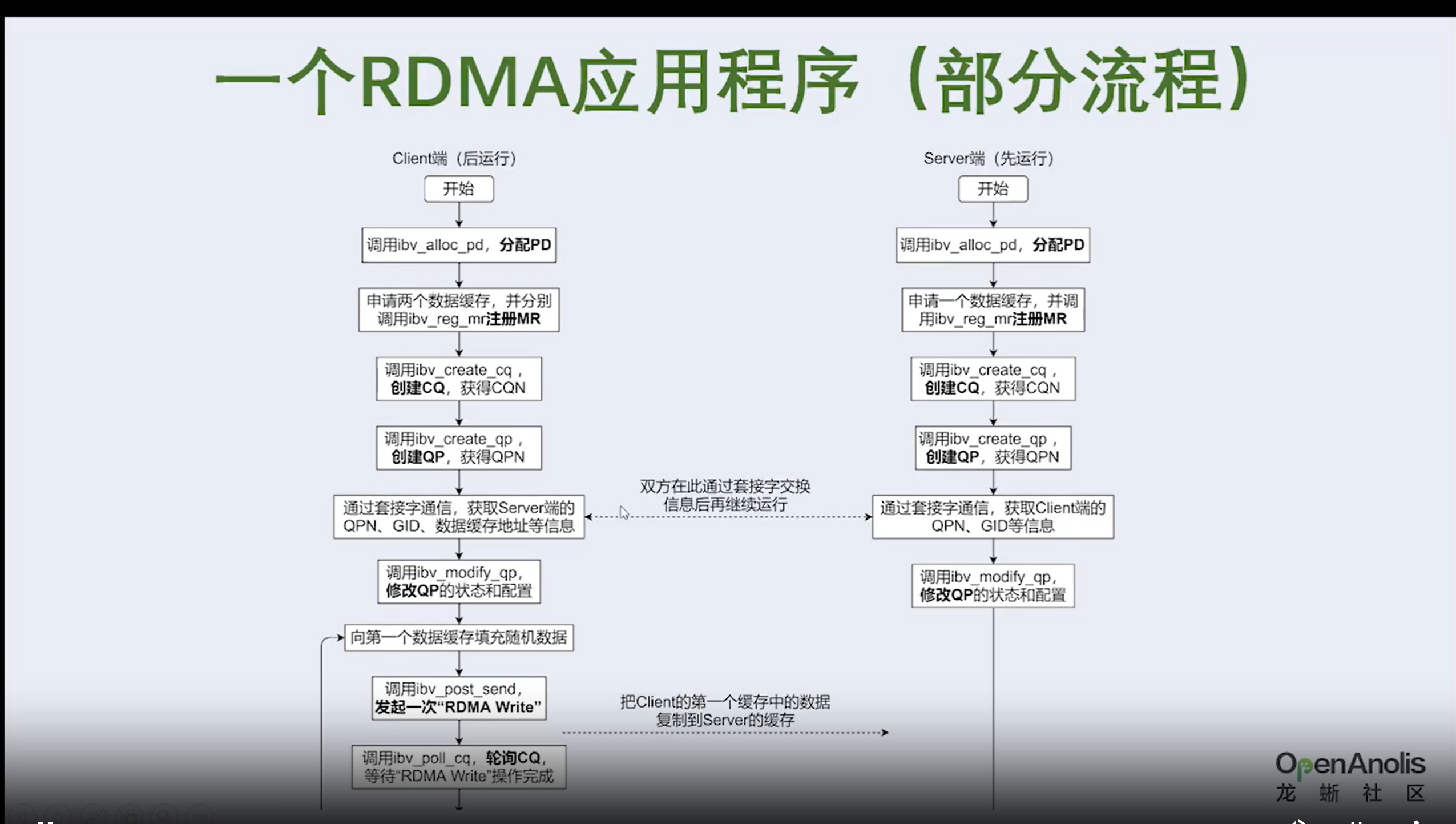
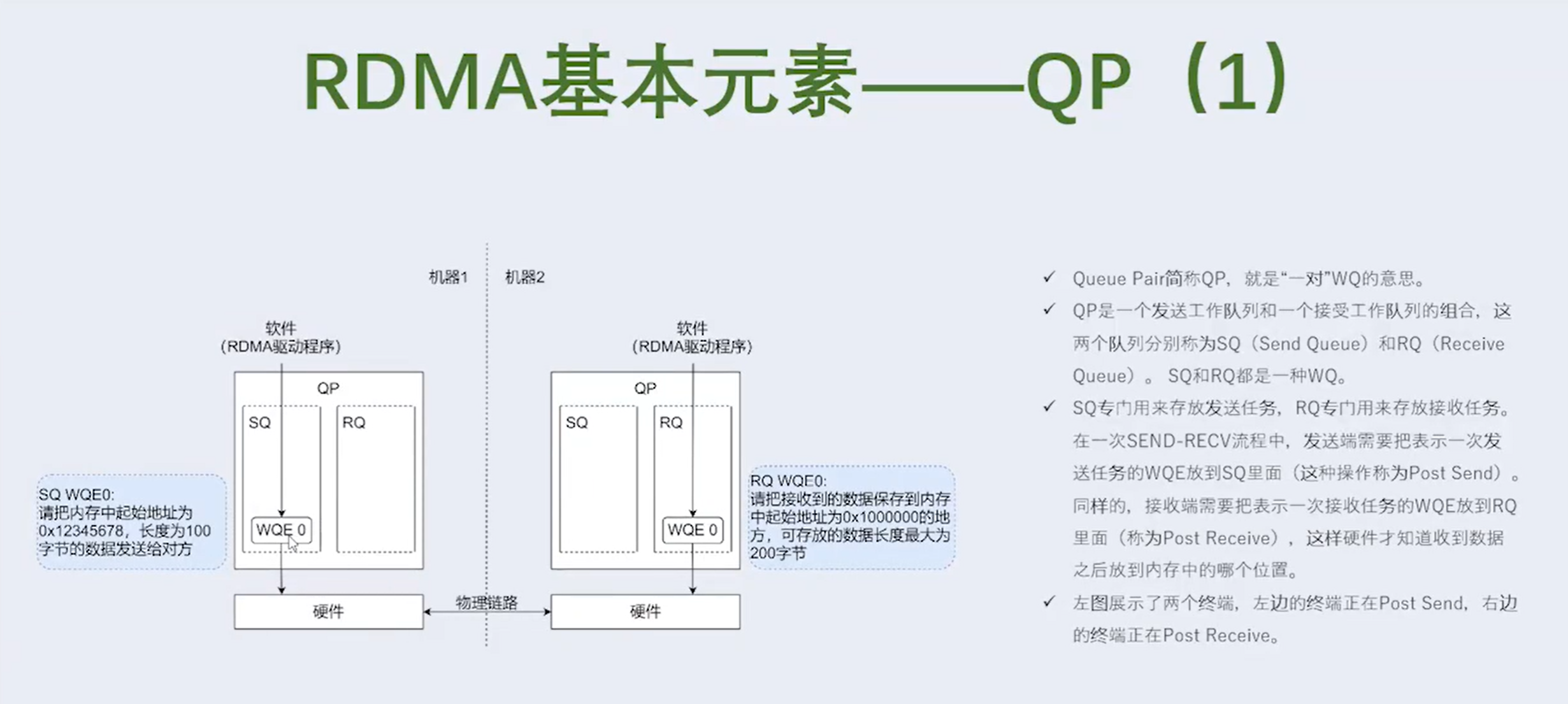
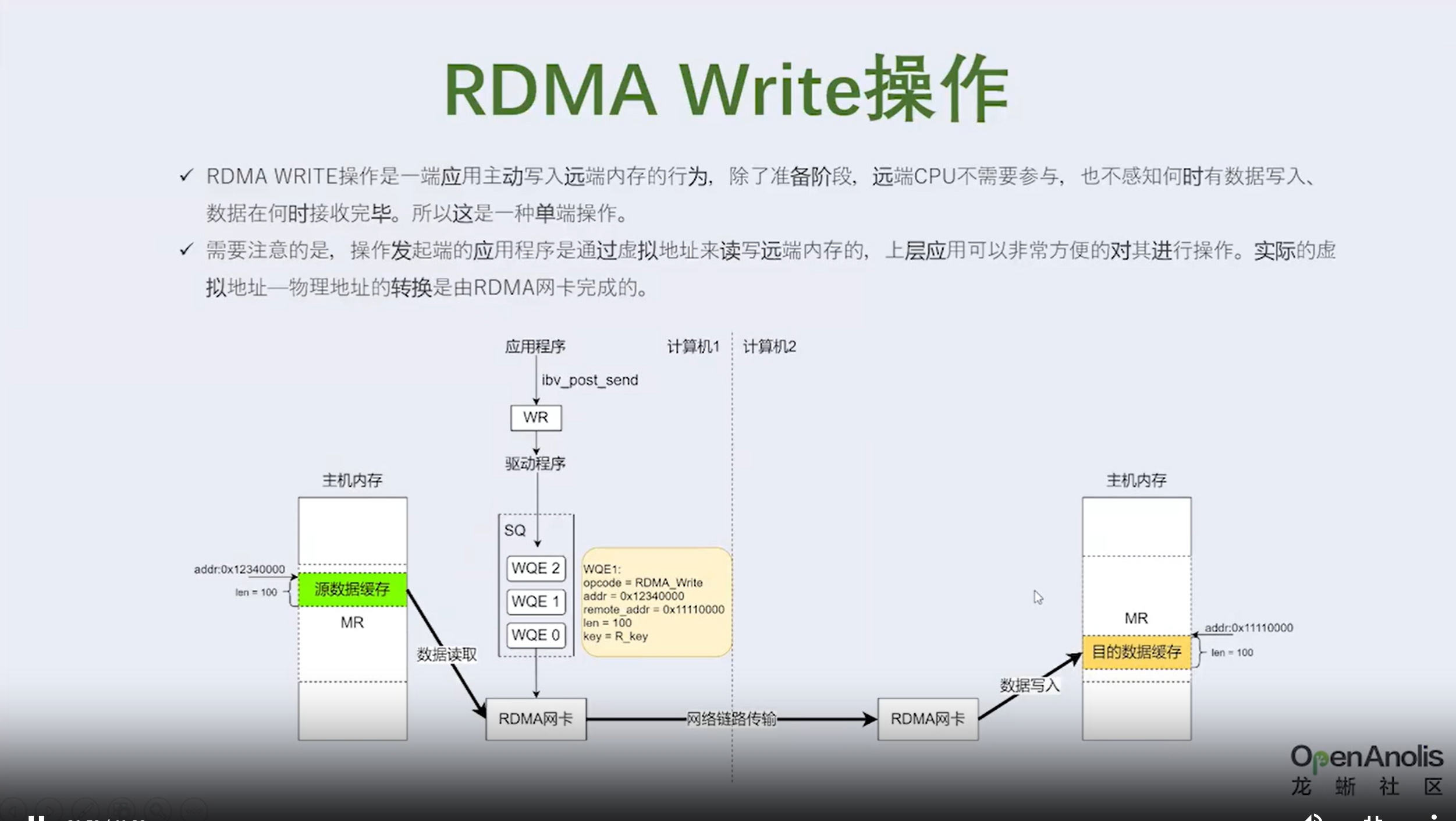
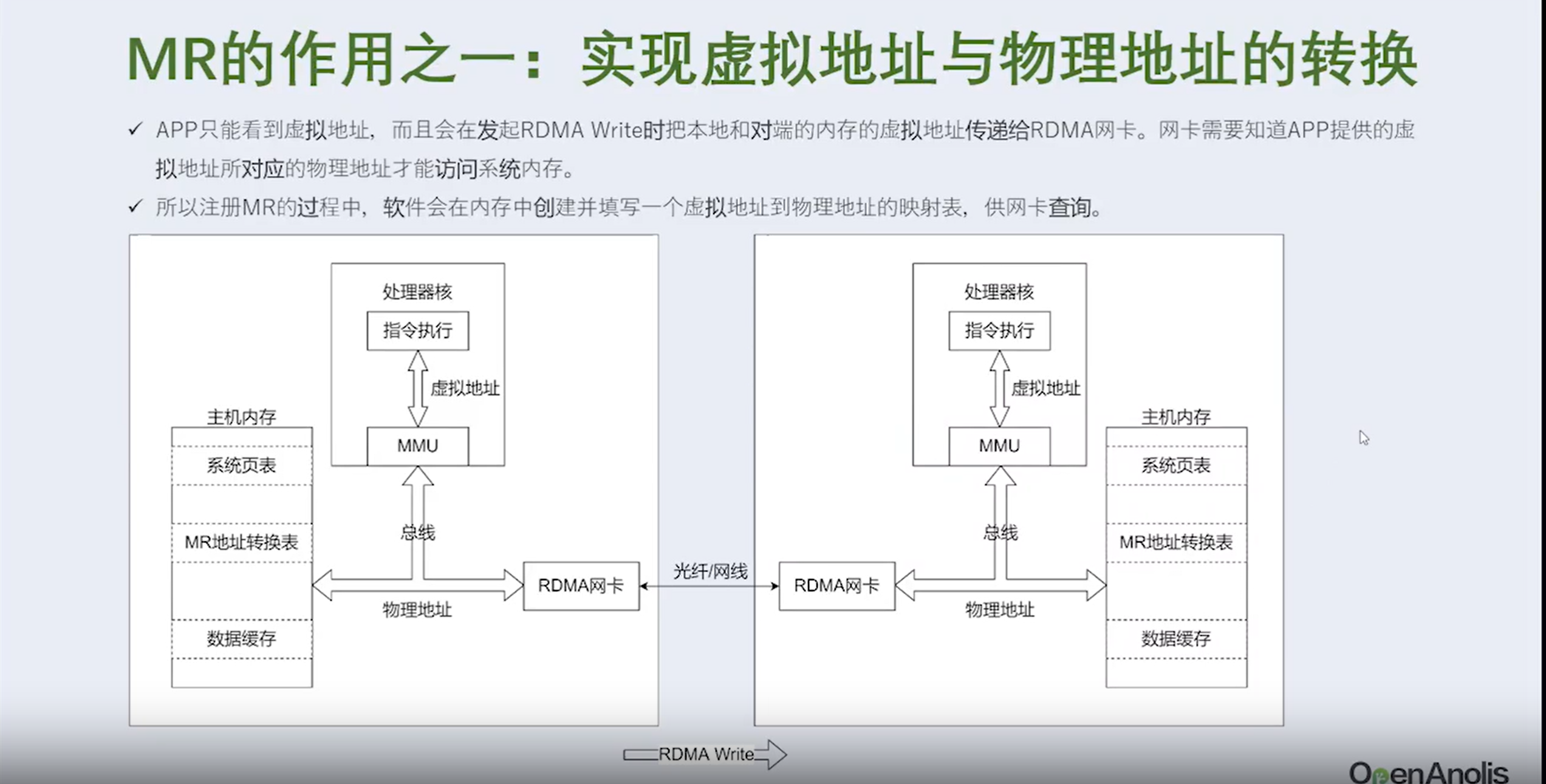
3.1 RDMA数控分离是什么含义
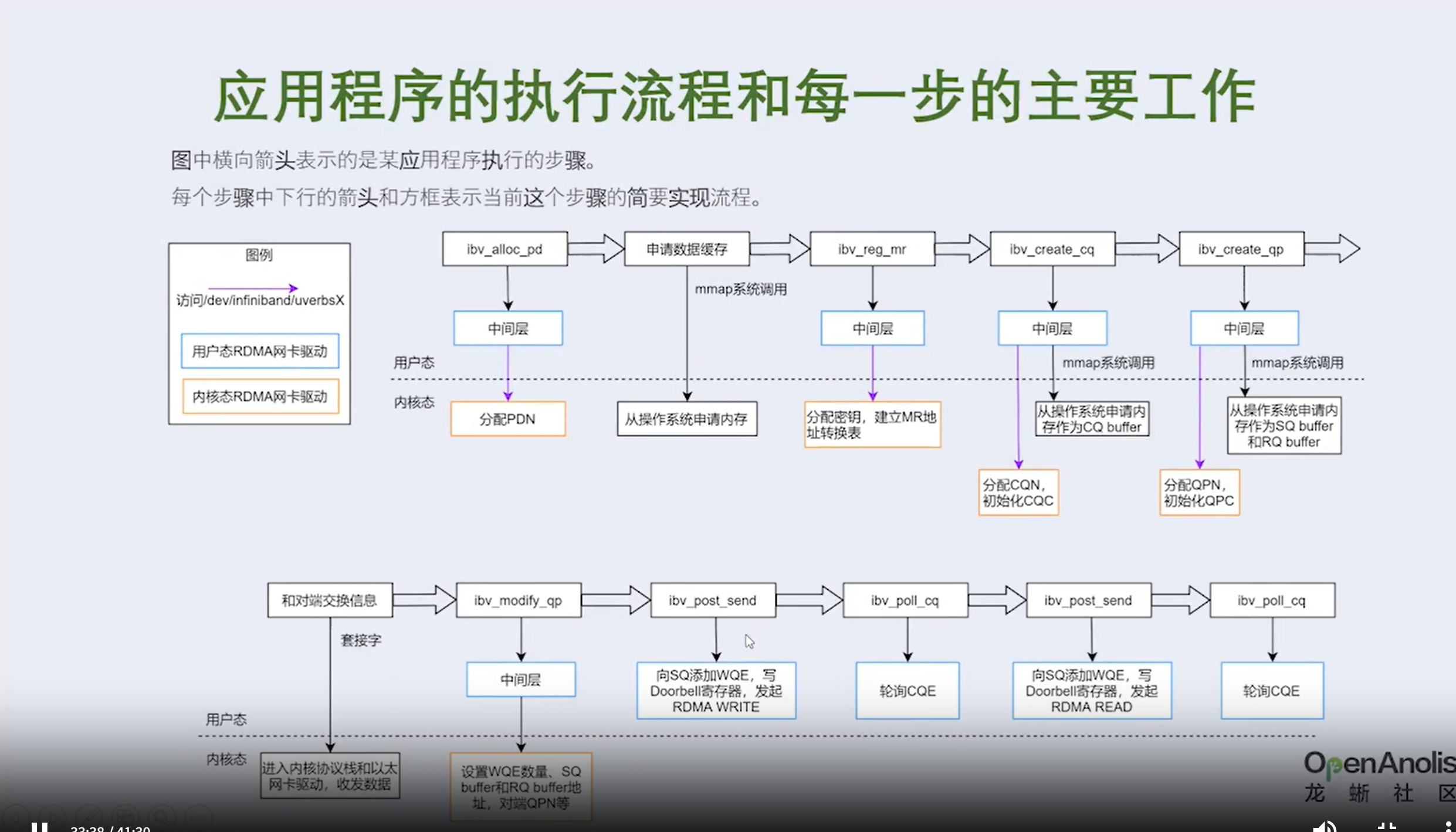
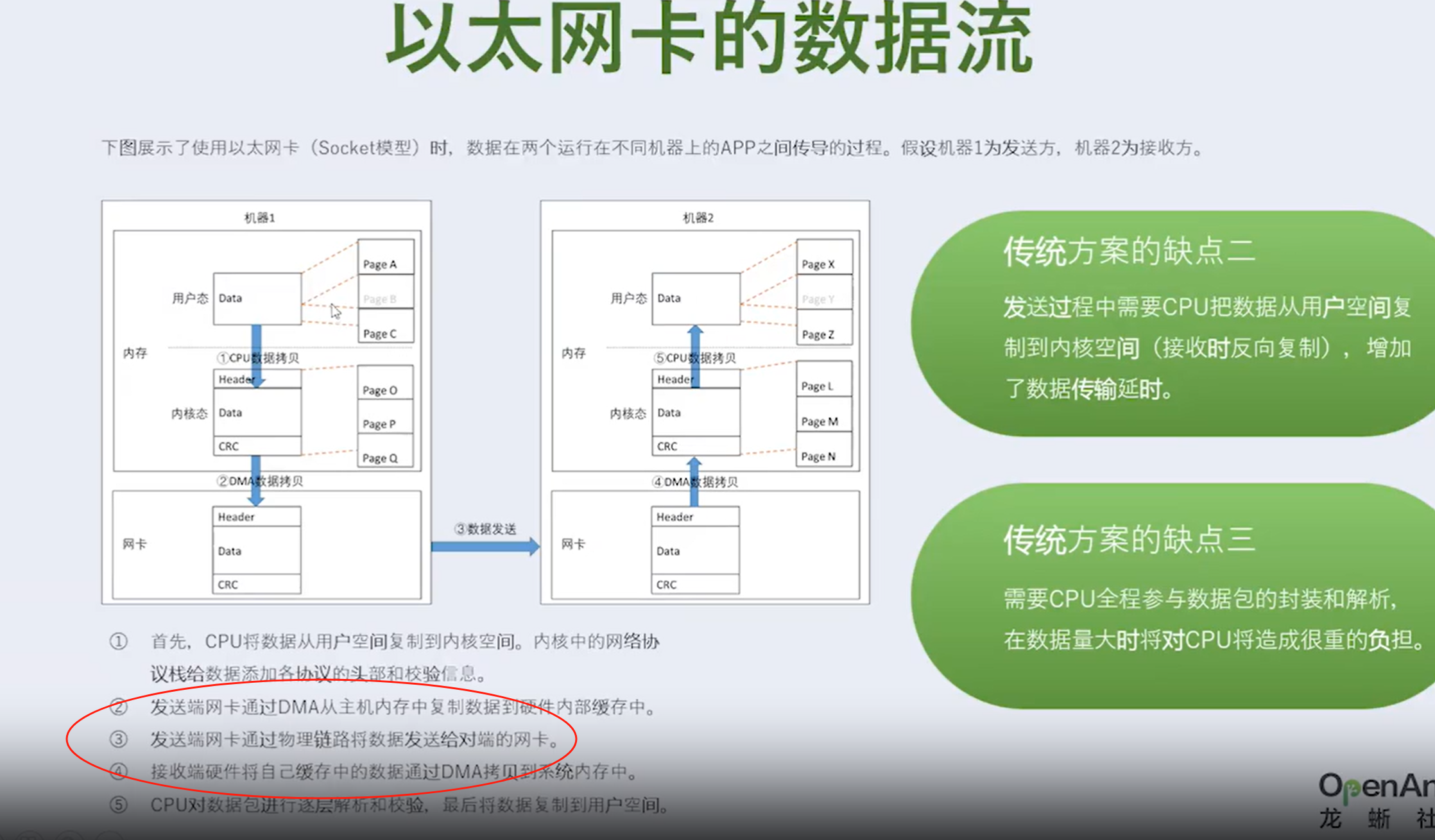
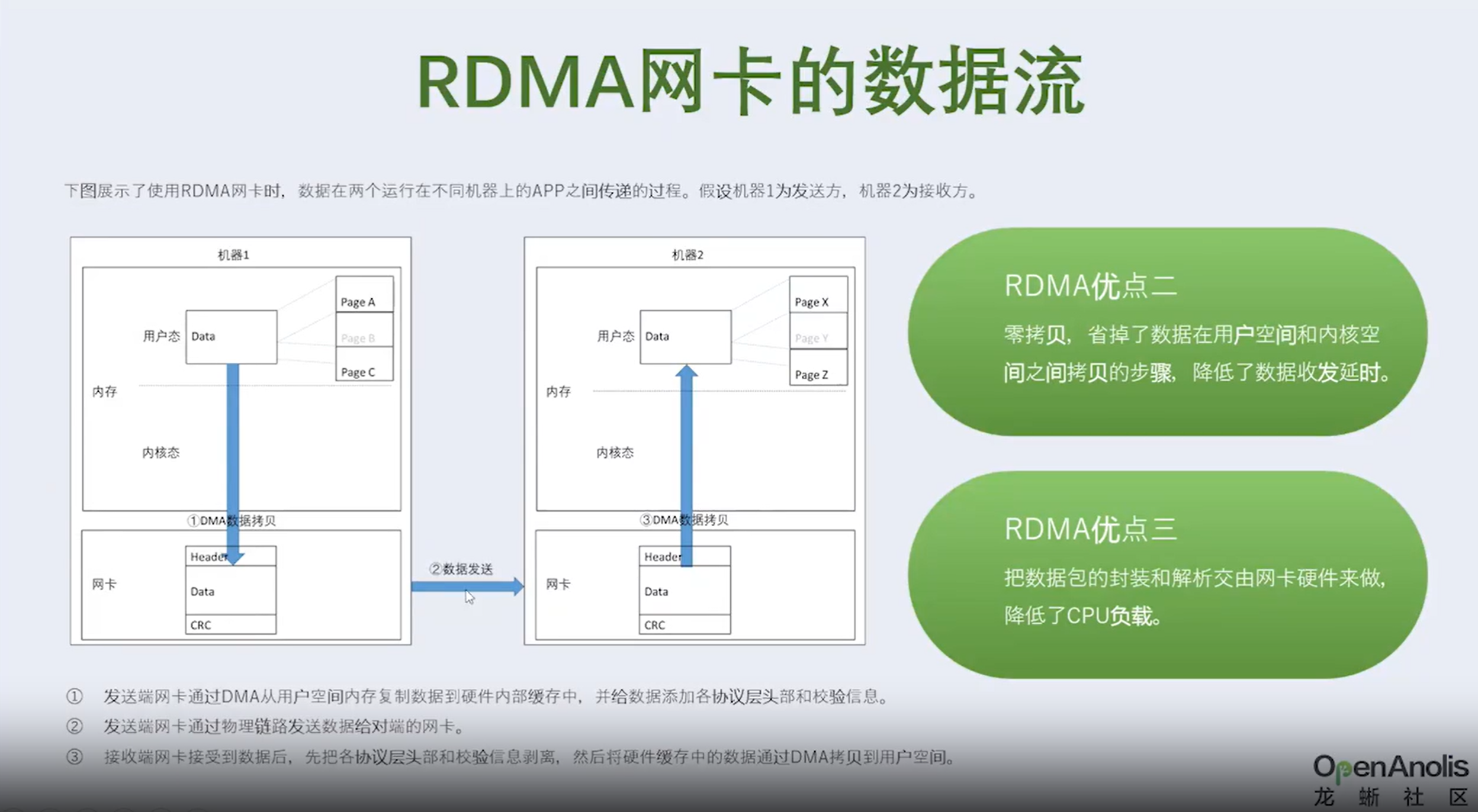
①发送端网卡会通过DMA直接从用户空间内存复制数据到自己内部缓存中,并给数据添加各层头部和校验信息。
②发送端网卡通过物理链路发送数据给对端的网卡。
③接收端网卡接受到数据后,先把各层头部和校验信息剥离,然后将自己缓存中的数据包DMA拷贝到用户空间。
通过和Socket的对比,我们可以明显看到,数据收发绕过了内核并且数据交换过程并不需要CPU参与,报文的组装和解析是由硬件完成的。
明显可以看出 RDMA 方案的三个优点。
- 本地内存零复制 • 内核旁路(bypass) • 把数据包的封装和解析工作交由网卡来实现,降低了 CPU 负载。
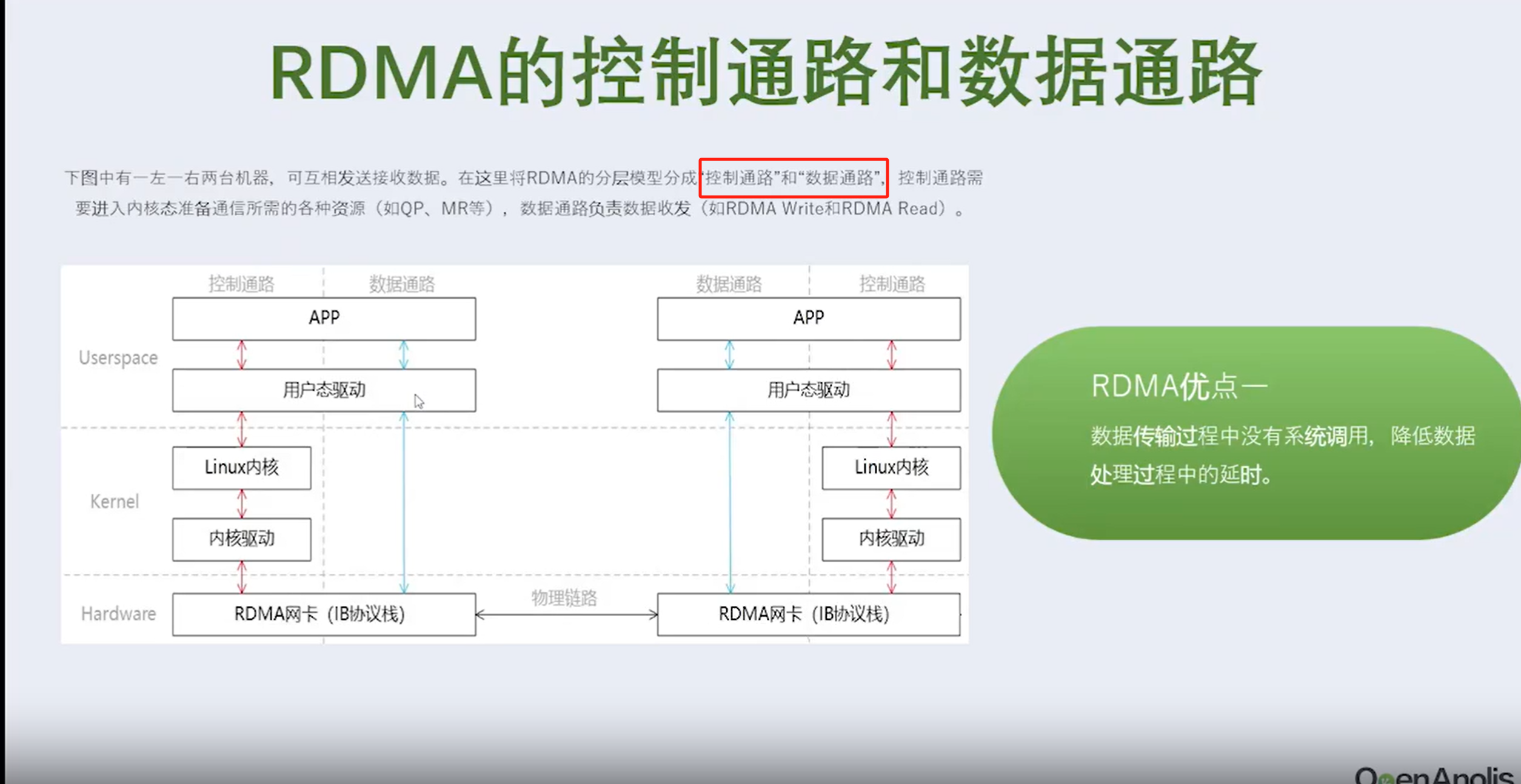
RDMA技术简介 RDMA的控制通路和数据通路方案
卡速率是一样的(比如都是10G/S),为什么要选择RDMA?或者RDMA有什么优势?
RDMA的优势:每个Data只需要3个ns就可以到达对端网卡——即每个Data更低的时延。


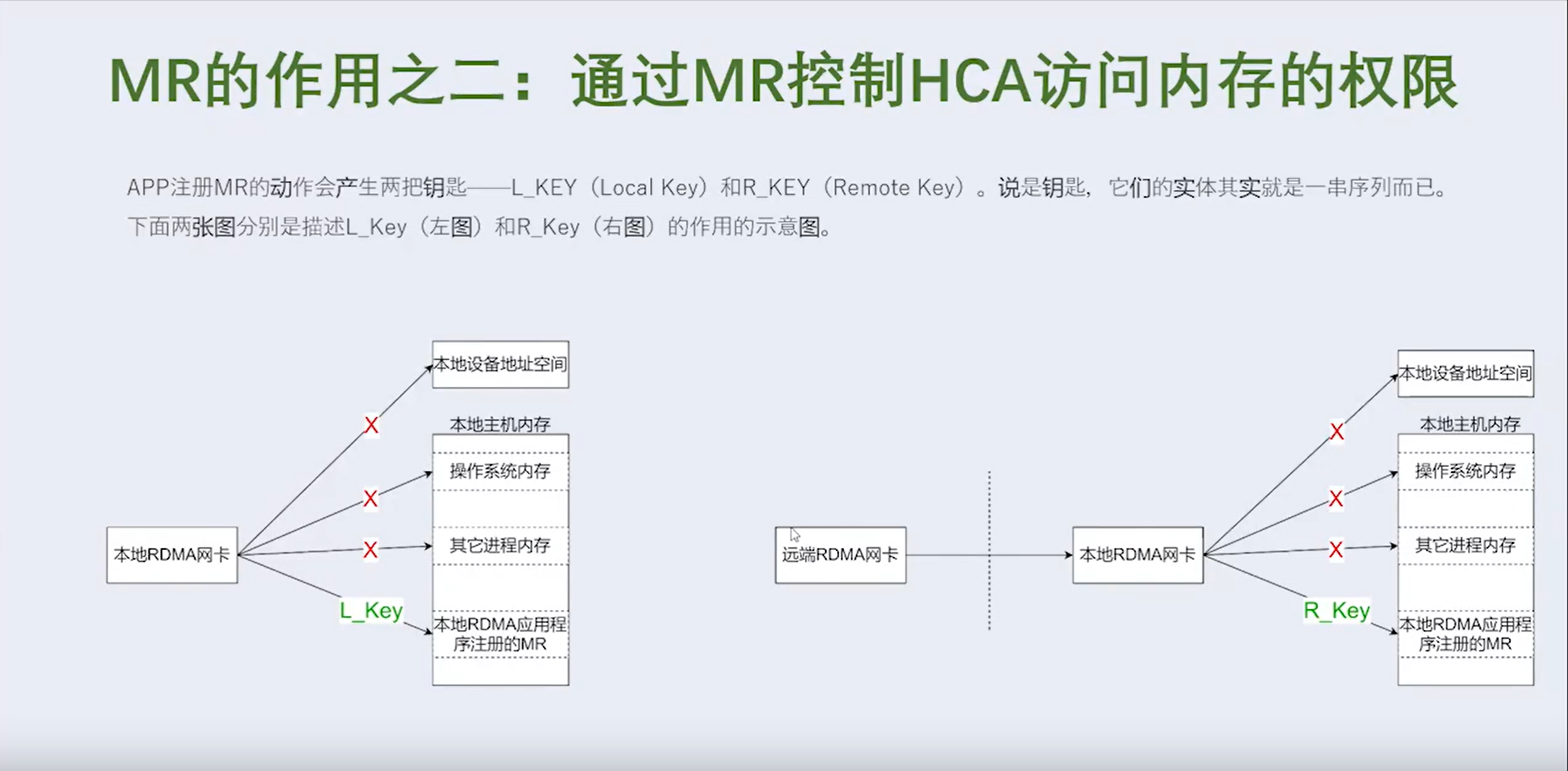
3.2 RDMA 没有解决什么问题
历史文章:# 2分钟论文:网卡直写磁盘,这项专利彻底绕过了 CPU!
参考专利:CN117573043B 发明名称 :分布式存储数据的传输方法、装置、系统、设 备和介质
- 在全闪存储产品中,远程直接数据存取(Remote Direct Memory Access,RDMA)技 术是比较常用的技术,数据跨节点传输卸载到RDMA网卡中,极大减少中央处理器(Central Processing Unit,CPU)接入,但是接收或者发送仍然
- 需要主机内存的介入,落盘时由主机 内存通过直接存储器访问(Direct Memory Access,DMA)方式拷贝到盘的内存里然后落盘。 主机内存拷贝过程,对带宽需求量高,产生的时延也较高,导致数据传输效率偏低。 可见,如何提升数据传输效率,是本领域技术人员需要解决的问题。
为什么 这么说,什么场景呢?
- 机器1:读取本地本地文件,从网络发送
- 机器2:从网络读取文件,写入本地文件
网络传输用RDMA,写入文件呢? 类似问题:# 如何将100Gbps的网络数据实时写入硬盘? https://www.zhihu.com/question/585959385
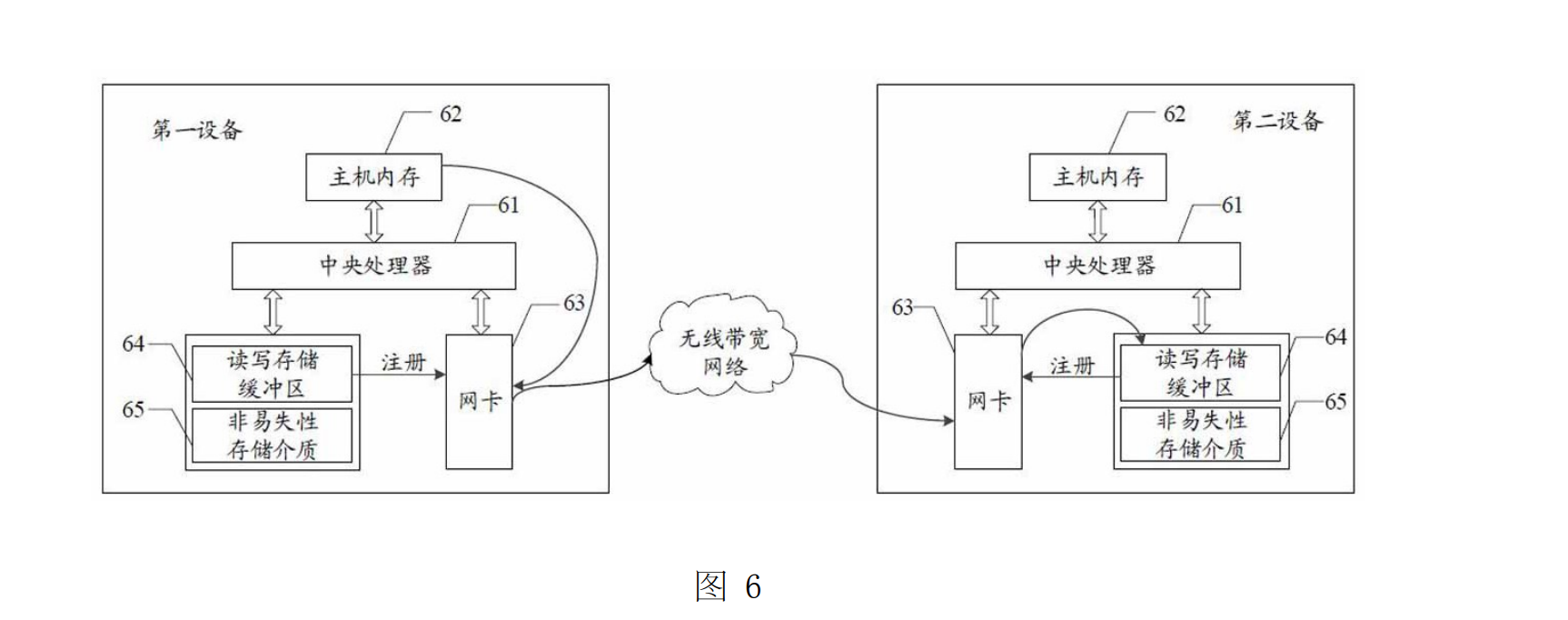
3.3 如何解决呢
- 参考专利:CN117573043B
- _https://aboutnetworks.net/nvme-and-nvmeof/_ RDMA-Based NVMe-oF # 一文读懂NVMe、NVMe-oF和RDMA
- NVMe将 SSD 设备视为内存,而不是硬盘驱动器
其他疑问
- 在RDMA单边传输和双边传输的差异
- https://blog.csdn.net/m0_71540099/article/details/135704323
- 小消息双边传输 :a. 将数据直接发送给主,再由主发送给子
- 大消息单边传输
参考资料
- 医疗PACS影像系统的数据存储性能优化
- 基 MLPerf™ AI存储基准评测发榜,浪潮信息AS13000G7获多项测试最佳成绩
- 一图读懂浪潮信息新一代分布式全闪存储AS13000G7-N系列
- 时代和技术在变,但数控分离的架构设计理念未曾改变
- 最佳实践 | SD-WAN与SDP-SASE框架下的数控分离
- 一种分布式存储减少数据转发的方法、装置、设备及介质 https://max.book118.com/html/2023/0923/7102106122005161.shtm
- 3FS优化 01 | 服务端优化 https://www.high-flyer.cn/blog/3fs-1/
- 分布式存储数据的传输方法、装置、系统、设备和介质
- 【RDMA】qp数量和RDMA性能(节选翻译)|连接数
- RDMA DC QP工作原理介绍
- RDMA 单边模型
- 布鲁斯的读书圈 https://mp.weixin.qq.com/s/5hKLfprjjlQLIYxHwLOc9A
- RDMA网卡相对于传统以太网卡的优势
- 绕过CPU,英伟达让GPU直连存储设备