【翻译】Crimson:用于多核可扩展性的下一代 Ceph OSD

文章目录
Crimson:用于多核可扩展性的下一代 Ceph OSD
目录
- 前言与思考
- 背景与技术演进
- Crimson vs Classic OSD 架构
- Seastar 框架简介
- 运行到完成性能
- 多分片实现
- OSD 组件详解
- ObjectStore 后端
- AlienStore
- CyanStore
- SeaStore
- 总结与测试配置
在危机时代坚持修炼内功,锻炼身体, 等待恒纪元的到来,一旦新机会出现, 我们就已经做好了准备,抓住新的机会,实现自己的目标
系统重构,项目优化,重新开发系统 最重要一点是什么? Finer-grained Resource Management(细粒度资源管理)
- 目标:将资源(CPU、内存、I/O)的分配单位从"粗粒度"(如进程、线程)细化到"微粒度"(如协程、内存块、NUMA节点)。
- Fast Path Implementations(快速路径实现)**
- 网络协议栈:DPDK/XDP绕过内核协议栈(节省μs级延迟) TCP/IP协议栈
- 存储栈:NVMe over Fabrics的
Zero-Copy RDMA。 - 数据库:LSM-Tree的MemTable直接写入(跳过WAL队列)。
内核旁路(Kernel Bypass)是一种高性能计算和网络通信领域的重要技术,其核心思想是绕过操作系统内核
1. 前言与思考
在危机时代坚持修炼内功,锻炼身体, 等待恒纪元的到来,一旦新机会出现, 我们就已经做好了准备,抓住新的机会,实现自己的目标。
坚持(人生密码)
坚持的力量在于,它让我们在追求目标的过程中,不断超越自我,挖掘出自己的潜能。无论我们的目标有多大或多小,实现它们通常需要时间、努力和毅力。正是坚持,让我们在面临挑战时不放弃,从而最终实现我们的目标。
独立思考(掌握未来的关键能力)
在这个信息爆炸的时代,我们每天都会接触到大量的信息和观点。面对这些纷繁复杂的信息,学会独立辩证思考显得尤为重要。独立辩证思考是我们在认知世界、做决策和解决问题时的关键能力。它能帮助我们在茫茫信息海洋中找到真实的价值。
视野(拓宽人生的无限可能)
在我们的生活和工作中,视野的重要性不言而喻。 它不仅指的是我们看待问题的角度和深度,更是我们理解和接触世界的窗口。 一个开阔的视野可以帮助我们更好地理解世界,更准确地判断形势,更有效地解决问题。
2. 背景与技术演进
2.1 存储硬件的变化
用于存储软件的裸机硬件的架构一直在不断变化。
单词:
- constantly :经常
- metal 金属:
- Bare-metal:计算机件
- Technology landscape: 技术发展趋势
On one hand, memory and IO technologies have been developing rapidly. 一方面,内存和 IO 技术一直在迅速发展
At the time when Ceph was originally designed, it was deployed generally on spinning disks capable of a few hundreds of IOPS with tens of gigabytes of disk capacity.
在Ceph最初设计时,它通常部署在机械硬盘上,这些硬盘仅能提供数百次IOPS(每秒输入/输出操作次数)的吞吐能力和数十GB的磁盘容量。
单词:
- spinning disks:机械硬盘
- a few hundreds of IOPS:数百IOPS
- Originally:设计初衷
Modern NVMe devices now can serve millions of IOPS and support terabytes of disk space. 现代 NVMe 设备现在可以提供数百万 IOPS 并支持数 TB 的磁盘空间
DRAM capacity has increased 128 times in about 20 years And for Network IO, a NIC device is now capable of delivering speeds upwards of 400Gbps compared to 10Gbps just a few years ago.
现代 NVMe 设备现在可以提供数百万 IOPS 并支持数 TB 的磁盘空间。 DRAM 容量在大约 20 年内增长了 128 倍 对于网络 IO,NIC 设备现在能够提供超过 400Gbps 的速度,而几年前为 10Gbps。
啥意思:磁盘 网络,内存
- 从机械硬盘(数百IOPS/数十GB)到NVMe(百万级IOPS/TB级容量)
- 网络带宽从10Gbps跃升至400Gbps
- DRAM容量20年增长128倍
但是:在Ceph最初设计时,它通常部署在机械硬盘上
Ceph为适应从HDD到NVMe的硬件变革,主要进行了以下关键架构调整:
- 分层存储引擎优化
- 引入Bluestore替代Filestore
- 直接管理裸设备,规避文件系统开销(针对NVMe低延迟特性)
- 元数据与数据分离存储(HDD时代元数据需特殊优化
-
- IO路径重构
- 实现并行化IO处理
- HDD时代:顺序IO优化(机械寻道延迟是瓶颈)
- NVMe时代:深度队列并发(利用多核CPU+NVMe高队列深度)
- 机械硬盘(HDD)时代的串行IO
- 支持并行通道(如PCIe 4.0 x4 = 64条虚拟车道)
- 队列深度可达数万(相当于同时处理数万辆车)
网络协议增强
- 支持RDMA/RoCEv2
- 匹配400Gbps网卡性能
- 传统TCP/IP栈无法满足NVMe-oF场景
On the other hand, single-core performance has plateaued(达到稳定水平) as the CPU frequency and single-thread performance of CPU cores has remained in the same range for about a decade now 另一方面,单核性能趋于停滞,因为在过去十年中,CPU 的主频和单线程性能几乎没有明显提升
In contrast, the number of logical cores has grown quickly with the increasing transistor (晶体管)scale.
相较之下,随着晶体管规模的增长,逻辑核心的数量迅速增加。
重点:多核架构,通过增加数量
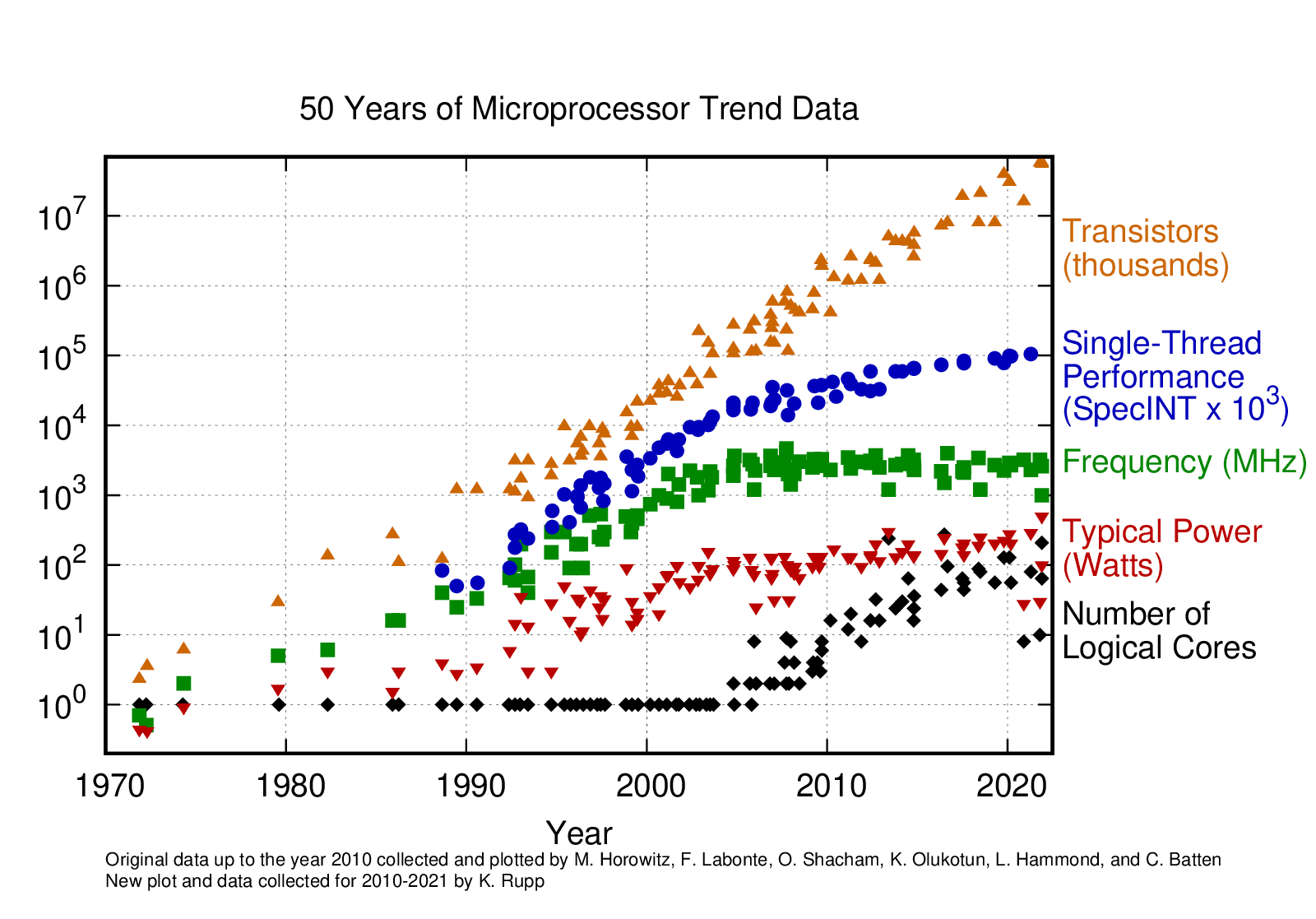
It has been challenging for Ceph performance to keep up with the pace of modern hardware development, as its architecture was shaped more than a decade ago –
its dependence on single core performance limits its ability to take full advantage of the growing capabilities of IO devices.
Ceph 性能要跟上现代硬件发展的步伐一直是一项挑战,因为它的架构是在十多年前形成的,它对单核性能的依赖限制了它充分利用 IO 设备不断增长的功能的能力
现代 IO 和 CPU 的演进趋势:
| 资源类型 | 演进方向 | 对 Ceph 架构的挑战 |
|---|---|---|
| CPU | 多核 > 单核 | 串行瓶颈限制并行计算能力 |
| 存储 | NVMe、SSD | Ceph 无法产生足够并行写请求 |
| 网络 | RDMA、高带宽网卡(25G/100G) | 单线程网络处理撑不起吞吐量 |
In particular, classic Ceph object storage daemon (OSD)’s reliance on thread pools to handle different portions of an IO incurs significant latency costs due to cross-core communications. Reducing or eliminating those costs is the core goal of the Crimson project.
特别是,由于跨核心通信,传统 Ceph 对象存储守护进程 (OSD) 依赖线程池来处理 IO 的不同部分,这会产生巨大的延迟成本。减少或消除这些成本是 Crimson 项目的核心目标。
疑问:怎么解决多核架构交互问题?
The Crimson project was initiated to rewrite the Ceph OSD with the shared-nothing design and run-to-completion model to address the demanding scaling requirements, and at the same time, be compatible with the existing clients and components.
Crimson 项目旨在使用无共享设计和运行到完成模型重写 Ceph OSD,以满足苛刻的扩展要求,同时与现有客户端和组件兼容。
Seastar 框架:高性能事件驱动编程模型
-
Crimson 基于 Seastar 框架构建,这是一个为高性能服务器应用设计的 C++ 异步编程框架。
-
特点:
- 每个核心运行独立的事件循环(reactor)
- 使用
future/promise进行异步任务编排(无回调) - 无需线程间共享内存,每个 core 拥有自己的数据与逻辑
- 完全用户态 I/O(bypass 内核 context switch)
Crimson 相较传统 OSD 的区别
| 特性 | 传统 Ceph OSD | Crimson OSD (Seastar/无共享) |
|---|---|---|
| 多核利用方式 | 多线程 + 锁 | 每核独立事件循环,无锁 |
| 状态共享 | 全局状态、共享 PG、缓存等 | 每核独占状态,PG 分区 |
| 并发处理模型 | 多线程互斥调度 | 异步事件 + run-to-completion |
| 通信方式 | 共享内存或全局队列 | 跨核消息传递 |
| 调度粒度 | 操作系统线程调度 | 应用层轻量协程调度 |
To understand how Crimson OSD is re-designed for CPU scaling, we compare the architectural differences between Classic and Crimson OSD to explain how and why the design has been altered.
为了了解 Crimson OSD 如何针对 CPU 扩展进行重新设计, 我们比较了 Classic 和 Crimson OSD 之间的架构差异, 以解释设计是如何以及为什么被更改的
Then we discuss why Crimson builds on the Seastar framework, and how each major component is implemented for scaling. 然后,我们讨论为什么 Crimson 基于 Seastar 框架构建, 以及如何实现每个主要组件以进行扩展
重点:不是自己发明轮子,用Seastar framework 重新设计自己业务
Finally, we share the latest status towards this goal, and with meaningful performance results that might be helpful to illustrate the final vision.
最后,我们分享了实现这一目标的最新状态,以及有意义的性能结果, 这些结果可能有助于说明最终愿景。
单词: 最终愿景** → Final vision
关键性能结果** → Meaningful performance results
Crimson vs Classic OSD Architecture
Crimson vs Classic OSD 架构
疑问:架构是什么,解决什么问题,为什么重构
Ceph OSD is a part of Ceph cluster responsible for providing object access over the network, maintaining redundancy and high availability and persisting objects to a local storage device.
Ceph OSD 是 Ceph 集群的一部分,负责通过网络提供对象访问、维护冗余和高可用性,以及将对象持久保存到本地存储设备
Ceph OSD modularity such as Messenger, OSD services, and ObjectStore are unchanged in their responsibilities, Ceph OSD 模块化(如 Messenger、OSD 服务和 ObjectStore)的职责保持不变
1. OSD 模块职责不变
-
OSD(Object Storage Daemon) 是 Ceph 中的核心组件,负责数据的存储、复制、恢复和再平衡。
-
其中的子模块如:
-
Messenger:负责网络通信协议处理;
-
OSD services:执行如 peering、replication 等核心逻辑;
-
ObjectStore:提供与后端存储(如 BlueStore)的具体读写接口。
-
虽然进行了底层架构优化,但这些模块"该做什么“的职责(responsibilities)没变。
but the form of cross-component interactions and internal resource management are vastly refactored to apply the shared-nothing design and user-space task scheduling bottom up.
但跨组件交互和内部资源管理的形式被大大重构,
以自下而上地应用无共享设计和用户空间任务调度。
跨组件交互和资源管理重构
-
过去,Ceph 内部模块之间的交互以及资源调度多依赖于内核线程、全局锁、共享状态等机制,容易引起性能瓶颈和资源竞争。
-
现在 Ceph 重构了这部分:实现了更为清晰和独立的模块边界,采用现代分布式系统架构理念,如:
🔹 Shared-nothing design(共享无设计)
-
每个组件尽可能独立运行,不共享内存、不共享锁。
-
优点:
-
降低资源争用;
-
更好地并行扩展;
-
容错性和隔离性更强。
-
例如,多个 OSD 线程不会共享状态变量,而是通过消息传递(message passing)来通信。
🔹 User-space task scheduling(用户态任务调度)
-
Ceph 底层不再依赖操作系统内核的调度器(如 POSIX threads),而是将调度逻辑迁移到了用户空间。
-
常用技术包括:
-
协程(coroutines / fibers);
-
事件驱动框架(如 Seastar, io_uring 等);
-
自定义调度器(例如在 BlueStore/Crimson 中实现)。
-
确实,显式通信(如网络消息、IPC)相比共享内存通常会有更高的延迟和开销, 但为什么现代系统(如微服务、分布式数据库)仍广泛采用这种设计?关键在于权衡取舍和工程优化。以下是逐层解析:
1. 显式通信 vs. 共享内存的性能对比
| 维度 | 共享内存 | 显式通信(网络/IPC) |
|---|---|---|
| 延迟 | 极低(纳秒级,如CPU缓存访问) | 较高(微秒~毫秒级,依赖传输介质) |
| 吞吐 | 高(内存带宽可达GB/s) | 受网络带宽限制(如10Gbps≈1.25GB/s) |
| 扩展性 | 差(锁竞争随组件数增加而加剧) | 好(组件可分布式部署) |
| 容错性 | 差(单点故障易扩散) | 好(故障隔离性强) |
| 编程复杂度 | 高(需处理竞态、死锁) | 低(消息异步处理,逻辑解耦) |
2. 为什么显式通信仍被采用?
(1)扩展性需求压倒性能损耗
- 共享内存的瓶颈:当组件数量增加时,锁竞争、缓存一致性(Cache Coherency)会导致性能急剧下降(如Amdahl定律)。
- 显式通信的优势:通过水平扩展(加机器)线性提升性能,适合云计算、分布式场景。
(2)现代硬件/协议优化显式通信
- RDMA(远程直接内存访问):绕过OS内核,延迟可低至1μs(如InfiniBand)。
- 零拷贝技术:如Linux的
io_uring、DPDK,减少数据复制开销。 - 高效序列化:Protobuf、FlatBuffer比JSON/XML快10~100倍。
(3)异步化与批处理抵消延迟
- 消息批处理:如Kafka的Producer批量发送。
- 流水线化:重叠通信与计算(如GPU-CPU异构计算)。
- 协程/事件驱动:避免线程阻塞(如Go的Goroutine)
1)Shared-Nothing Design(无共享设计)
- 本质:系统组件(如进程、线程、节点)不共享内存或磁盘存储,仅通过显式通信(如网络消息、IPC)交互。
- 计算机中的典型应用:
- 分布式系统:如Kubernetes Pod、微服务架构(每个服务独立资源)。
- 数据库分片:如MySQL分库分表,每个分片独占资源。
- 高性能计算:MPI编程中进程间通过消息传递通信。
- 优势:
- 可扩展性:无共享状态=无锁竞争,易水平扩展。
- 容错性:单组件故障不影响其他组件。
- 确定性:避免共享内存的竞态条件(Race Condition)。
(2)User-Space Task Scheduling(用户态任务调度)
- 与传统内核调度的区别:
- 内核调度:由OS内核统一管理线程/进程,涉及特权级切换(上下文切换开销高)。
- 用户态调度:应用自行管理任务(如协程、轻量级线程),无需陷入内核。
- 典型实现:
- 协程库:如Go的Goroutine、Rust的Tokio。
- DPDK/SPDK:绕过内核直接管理网卡/磁盘。
SPDK和DPDK的关系 SPDK(Storage Performance Development Kit)和DPDK(Data Plane Development Kit)是两个由Intel开源的项目,用于优化存储和网络数据平面的性能。
尽管SPDK和DPDK是独立的项目,但它们之间存在紧密的关系和互补的作用。下面是它们之间的关系:
共同的目标:SPDK和DPDK的共同目标是通过提供高性能的软件库和工具,加速存储和网络数据平面的开发和部署。
共享的组件:SPDK和DPDK在某些方面共享相同的组件和技术。例如,它们都使用了User
The architecture of the Classic OSD isn’t friendly to multiple cores with worker thread pools in each component and shared queues among them.
Classic OSD 的架构对多个内核不友好,每个组件中都有 worker 线程池,并且它们之间有共享队列

In a simplified example, a PG operation requires to be firstly processed by a messenger worker thread to assemble or decode raw data stream into a message, then put into a message queue for dispatching. 在简化的例子中,PG 作需要首先由 Messenger 工作线程处理,将原始数据流组装或解码为消息,然后放入消息队列进行调度
Later, a PG worker thread picks up the message, after necessary processing, hands over the request to the ObjectStore in the form of transactions.
稍后,一个 PG worker 线程获取消息,经过必要的处理后,将请求以事务的形式交给 ObjectStore
After the transaction is committed, the PG will complete the operation and send the reply through the sending queue and the messenger worker thread again. 事务提交后,PG 将完成作,并再次通过发送队列和 Messenger 工作线程发送回复
Although the workload is allowed to scale to multiple CPUs by adding more threads into the pool, these threads are by default sharing the resources and thus require locks which introduce contentions.
事务提交后,PG 将完成作,并再次通过发送队列和 Messenger 工作线程发送回复
And the reality is more complicated as further thread pools are implemented inside each component, and the data path is longer if there are replications across the OSDs.
随着每个组件内部实施了更多的线程池,现实情况更加复杂, 如果跨 OSD 存在复制,则数据路径会更长。
A major challenge of the Classic architecture is that lock contention(锁争用) overhead scales rapidly with the number of tasks and cores, and every locking point may become the scaling bottleneck under certain scenarios.
Classic 架构的一个主要挑战是锁争用开销会随着任务和内核的数量而快速扩展, 并且每个锁定点在某些情况下都可能成为扩展瓶颈
Moreover, these locks and queues(队列) incur latency costs even when uncontended(没有争用).
此外,即使没有争用,这些锁和队列也会产生延迟成本
There have been considerable(相当大) efforts over the years on profiling and optimizations for finer-grained(更细粒度) resource management and fast path implementations to skip queueing.
多年来,人们在分析和优化更细粒度的资源管理和跳过排队的快速路径实现方面 付出了相当大的努力
单词:** Finer-grained Resource Management(细粒度资源管理)
- 目标:将资源(CPU、内存、I/O)的分配单位从"粗粒度”(如进程、线程)细化到"微粒度"(如协程、内存块、NUMA节点)。
- Fast Path Implementations(快速路径实现)
- 本质:在通用处理流程中识别高频/低延迟路径,通过绕过队列/锁/中间层直接处理。
- 案例:
- 网络协议栈:DPDK/XDP绕过内核协议栈(节省μs级延迟)。
- 存储栈:NVMe over Fabrics的
Zero-Copy RDMA。 - 数据库:LSM-Tree的MemTable直接写入(跳过WAL队列)。
- Skipping Queueing(跳过排队)
- 为什么需要跳过?
队列引入的延迟包括:入队/出队操作、等待调度、上下文切换。 - 如何跳过?
- 优先级抢占:实时任务直接抢占CPU(如Linux RT-Preempt)。
- 无锁设计:如Seastar框架的Shard-per-Core架构。
- 为什么需要跳过?
案例:分布式存储系统(如Ceph Bluestore)
| 优化目标 | 细粒度资源管理 | 快速路径实现 | 协同效应 |
|---|---|---|---|
| 写请求处理 | 每个NVMe SSD绑定独立CPU核心 | 直接调用SPDK轮询驱动,跳过内核队列 | 单设备吞吐达 1M+ IOPS |
| 元数据操作 | 元数据分区独占NUMA节点内存 | 无锁跳表(SkipList)替代B-Tree | 查询延迟降低 10倍 |
| 数据校验 | CRC计算专用硬件加速器(如Intel QAT) | 校验失败直接丢弃,不进通用路径 | 无效数据处理开销 |
There will be less low-hanging fruits in the future and the scalability seems to be converging into a certain multiplicator , 未来唾手可得的果实会更少
- Low-hanging fruits(唾手可得的机会)
→ 指不需要复杂努力即可实现的性能优化 - Scalability converging(可扩展性趋于收敛)
→ 暗喻性能随资源增加的收益递减(突破需架构革新)
例:千核扩展从线性(1→N)退化为亚线性(1→logN)
under a similar design. There are other challenges as well.
The latency issue will deteriorate(恶化) with thread pools and task queues, as the book keeping effort delegates tasks between the worker threads.
And locks can force context-switches which make things even worse.
延迟问题会随着线程池和任务队列的出现而恶化,因为记账工作会在工作线程之间委派任务。
锁可以强制上下文切换,这会使情况变得更糟。
The Crimson project wishes to address the CPU scalability issue with the shared-nothing design and run-to-completion model.
Crimson 项目希望通过无共享设计和运行到完成模型来解决 CPU 可扩展性问题
| 英文术语 | 中文含义 | 说明 |
|---|---|---|
| address | 解决;应对 | 在此指"处理并消除"某一技术难题。 |
| CPU scalability | CPU 可扩展性 | 指系统在增加更多 CPU 资源时,性能(吞吐量、并发处理能力)能否成比例提升。 |
| shared-nothing design | 共享无设计 | 分布式/并行系统设计原则,组件间不共享资源,通过消息传递实现协作。 |
| run-to-completion model | 运行到完成模型 | 任务在同一执行上下文中连续执行直至完成,避免中途切换,以降低调度和上下文切换开销。 |
| event-driven framework | 事件驱动框架 | 通过事件循环和回调机制管理任务,可与 run-to-completion 模式结合,实现高并发。 |
| user-space scheduling | 用户态调度 | 将任务调度逻辑放在用户空间,减少对内核调度的依赖,提升效率和可控性。 |
Basically, the design is to enforce each core, or CPU, to run one pinned thread and schedule non-blocking tasks in user space. 基本上, 该设计是强制每个内核或 CPU 运行一个固定线程,并在用户空间中调度非阻塞任务
Requests as well as their resources are sharded by cores, 请求及其资源按内核分片
so they can be processed in the same core until completion. 因此它们可以在同一内核中进行处理,直到完成
Ideally, all the locks and context-switches are no longer needed as each running non-blocking task owns the CPU until it completes or cooperatively yields. 理想情况下,不再需要所有的锁和上下文切换, 因为每个正在运行的非阻塞任务都拥有 CPU,直到它完成或协作产生。没有其他线程可以同时抢占任务

Although cross-shard communications cannot be eliminated entirely, those are usually for OSD global status maintenance and not in the data path. 虽然无法完全消除跨分片通信,但这些通信通常用于 OSD 全局状态维护,而不是在数据路径中
A major challenge here is that the expected changes are fundamental to core OSD operation – a considerable part of the existing locking or threading code cannot be reused, and needs to be redesigned while backward compatibility is maintained.
这里的一个主要挑战是预期的更改是核心 OSD 作的基础 – 现有锁定或线程代码的很大一部分无法重用,需要在保持向后兼容性的同时重新设计
Redesign requires holistic understanding of the code with inherent caveats.
It is another challenge to implement low-level thread-per-core and user-space scheduling using shared-nothing architecture.
重新设计需要对代码有整体的理解,但有固有的注意事项。使用无共享架构实现低级每核线程和用户空间调度是另一个挑战
Crimson seeks to build the redesigned OSD based on Seastar, an asynchronous programming framework with all the ideal characteristics to meet the above goals.
Crimson 寻求基于 Seastar 构建重新设计的 OSD,Seastar 是一个异步编程框架, 具有满足上述目标的所有理想特性。
Crimson OSD 示例代码,展示如何基于 Seastar 构建一个简单的异步服务
Seastar Framework Seastar 框架
Seastar is ideal for the Crimson project because it not only implements the one-thread-per-core shared-nothing infrastructure in C++,
Seastar 是 Crimson 项目的理想选择,因为它不仅在 C++ 中实现了每核一线程的无共享基础设施,
but also provides a comprehensive set of features and models that have been proven to be effective for performance and scaling in other applications. 而且还提供了一套全面的功能和模型,这些功能和模型已被证明对其他应用程序中的性能和扩展有效。
Resources are by-default not shared between shards, and Seastar implements its own memory allocator for lockless allocations. 默认情况下,资源不在分片之间共享,Seastar 实现了自己的内存分配器,用于无锁分配
The allocator also takes advantage of the NUMA topology to assign the closest memory to the shard. 分配器还利用 NUMA 拓扑将最近的内存分配给分片
For some inevitable cross-core resource sharing and communications, Seastar enforces them to be handled explicitly: If a shard owns resources from another core, it must hold them by foreign pointers; And if a shard needs to communicate with other shards, it must submit and forward the tasks to them. 对于一些不可避免的跨核资源共享和通信,Seastar 强制显式处理它们:如果一个分片拥有来自另一个核心的资源,它必须通过外部指针来保存它们 ;如果一个分片需要与其他分片通信,则必须向它们提交和转发任务。
This forces the programmers to restrain their needs to go cross-core and helps to reduce the analysis scope for the CPU scalability issues. 这迫使程序员克制他们跨核的需求,并有助于缩小 CPU 可扩展性问题的分析范围。
Seastar also implements high-performance non-blocking primitives for the inevitable cross-core communications. Seastar 还为不可避免的跨核通信实现了高性能的非阻塞原语。
The conventional program with asynchronous events and callbacks is notoriously challenging to implement, understand and debug. 众所周知,具有异步事件和回调的传统程序在实现、理解和调试方面非常具有挑战性
And non-blocking task scheduling in user space requires implementation to be pervasively asynchronous. 用户空间中的非阻塞任务调度需要普遍异步的实现。
Seastar implements the futures, promises and continuations (f/p/c) as the building blocks to organize the logic. Seastar 实现了 futures、promise 和 continuations (f/p/c) 作为组织逻辑的构建块。
类别:c++11 特性呀,和其他语言也这样特性
The futures and promises makes code easier to write and read by grouping logically connected, asynchronous constructs together, rather than scattering them in plain callbacks.
futures 和 promise 通过将逻辑连接的异步结构分组在一起,而不是将它们分散在普通回调中,使代码更易于编写和阅读。
Seastar also provides higher level facilities for loops, timers, and to control lifecycles and even CPU shares based on the futures. Seastar 还为循环、计时器以及基于期货的生命周期甚至 CPU 份额提供了更高级别的工具
To further simplify applications, Seastar encapsulates both networking and disk accesses to the world of shared-nothing and f/p/c-based design. 为了进一步简化应用程序,Seastar 将网络和磁盘访问封装到无共享和基于 f/p/c 的设计世界中
笔记:这个 st 协程一样,另外一个轮子 不要还没说基础过,本质一样,
The complexity and nuanced control to adopt different I/O stacks (such as epoll, linux-aio, io-uring, DPDK, etc) are transparent to the application code.
采用不同 I/O 堆栈(如 epoll、linux-aio、io-uring、DPDK 等)的复杂性和细微控制对应用程序代码是透明的。
疑问:什么意思 ,用户不用管只调用相关接口
- Seastar 在内部会根据内核版本和配置,自动选择使用
linux-aio、io-uring或者回退到基于epoll的异步实现。 - 应用无需修改任何一行,就可以在不同系统上取得最优 I/O 性能。
- 上层代码只跟
listen、socket::send、packet等 Seastar 网络 API 打交道。 - Seastar 内部可基于
DPDK(在配置启用时)或内核epoll/io-uring实现高性能用户态/内核态 I/O。 - 对应用来说,完全"透明":无需关心底层是用哪种网络框架

Run-to-completion performance 运行到完成性能
The Crimson team has implemented most of the critical features of OSD for read and write workloads from RBD clients. Crimson 团队已经为 RBD 客户端的读取和写入工作负载实施了 OSD 的大部分关键功能
The effort includes re-implementations of the messenger V2 (msgr2) protocol, heartbeat, PG peering, backfill, recovery, object-classes, watch-notify, etc., with continuous stabilization efforts to add CI test suites. 这项工作包括重新实现信使 V2 (msgr2) 协议、心跳、PG 对等、回填、恢复、对象类、监视通知等,并持续稳定工作以添加 CI 测试套件。
Crimson has reached a milestone where we can validate run-to-completion design in a single shard with sufficient stability.
Crimson 已经达到了一个里程碑,我们可以在单个分片中验证具有足够稳定性的运行到完成设计。
Considering fairness and reality, the single-shard run-to-completion is validated by comparing Classic and Crimson OSD with the BlueStore backend, under the same random 4KB RBD workload, and without replication. 考虑到公平性和现实性,在相同的随机 4KB RBD 工作负载下,通过将 Classic 和 Crimson OSD 与
BlueStore 后端进行比较来验证单分片运行到完成,并且无需复制
Both OSDs are assigned 2 CPU resources. 两个 OSD 都分配了 2 个 CPU 资源
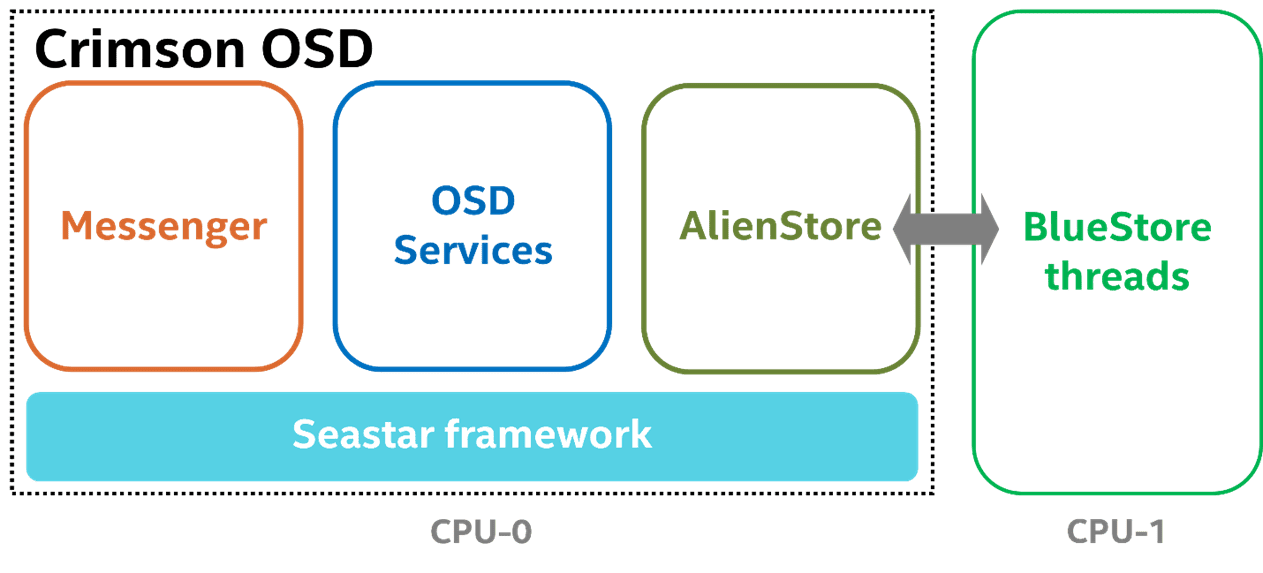
The Crimson OSD is special because Seastar requires an exclusive core to run the single-shard OSD logic in the reactor.
It implies that the BlueStore threads must be pinned to the other core, with AlienStore introduced to bridge the boundary between the Seastar thread and BlueStore threads and to submit IO tasks between the two worlds.
In contrast, the Classic OSD has no restrictions to use the assigned 2 CPUs.
。Crimson OSD 很特别,因为 Seastar 需要一个专用内核才能在反应器中运行单分片 OSD 逻辑。这意味着 BlueStore 线程必须固定到另一个内核,引入 AlienStore 来弥合 Seastar 线程和
BlueStore 线程之间的边界,并在两个世界之间提交 IO 任务。相比之下,Classic OSD 对使用分配的 2 个 CPU 没有限制。
The performance result shows that with BlueStore, the Crimson OSD has roughly 25% better performance for random-reads and has about 24% better IOPS than the Classic OSD for the random-write case.
Further analysis shows that the CPU is underutilized in the random-write scenario, as ~20% CPU is consumed in busy-polling, suggesting Crimson OSD is not the likely bottleneck here.
性能结果表明,使用 BlueStore 时,Crimson OSD 的随机读取性能比 Classic OSD 高约 25%,与经典 OSD 相比,随机写入情况的 IOPS 高约 24%。
进一步的分析表明,在随机写入场景中,CPU 未得到充分利用,因为 ~20% 的 CPU 在忙轮询中消耗,这表明 Crimson OSD 不是这里可能的瓶颈。
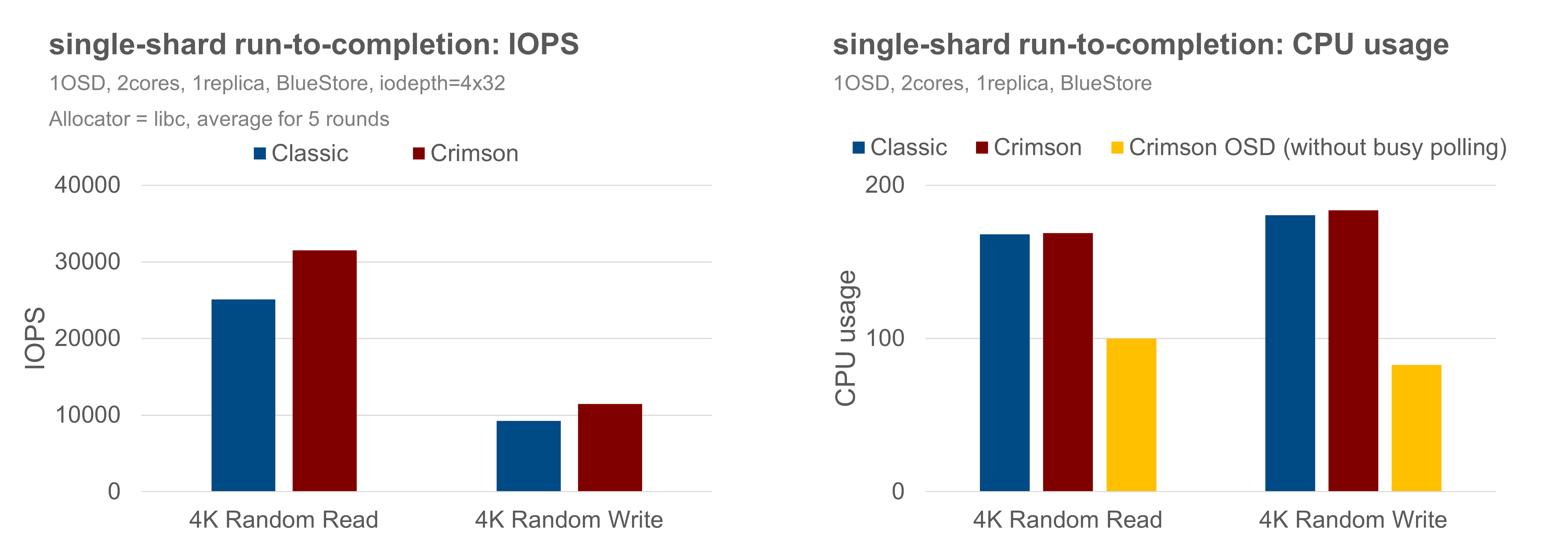
There is also extra overhead for the Crimson OSD to submit and complete IO tasks, and synchronize between the Seastar and BlueStore threads.
So, we repeat the same set of experiments against the MemStore backend, with both OSDs assigned 1 CPU. Crimson OSD delivers about 70% better IOPS in random-read and is about 25% better than the Classic OSD in the random-write case, as shown below, agreeing with the assertion in the previous experiment that Crimson OSD could do better.
Crimson OSD 提交和完成 IO 任务以及在 Seastar 和 BlueStore 线程之间同步也会产生额外的开销。 因此,我们对 MemStore 后端重复同一组实验,两个 OSD 都分配了 1 个 CPU。Crimson OSD 在随机读取中提供的 IOPS 提高了约 70%,在随机写入情况下比经典 OSD 高出约 25%, 如下所示,这与之前实验中关于 Crimson OSD 可以做得更好的断言一致。
Multi-shard Implementation 多分片实现
The path towards a multiple-shard implementation is clear. 实现多分片实现的道路很明确。
Since IO in each PG is already logically sharded, there is no significant change to the IO path. 由于每个 PG 中的 IO 已在逻辑上分片,因此 IO 路径没有重大变化
The major challenge is to identify places where cross-core communication is inevitable, and design new solutions to minimize the exposure and its impact to the IO path, which will need to be on a case-by-case basis. 主要挑战是确定跨核通信不可避免的位置,并设计新的解决方案以最大限度地减少暴露及其对 IO 路径的影响,这需要根据具体情况进行
In general, when an IO operation is received from the Messenger, it will be directed to the OSD shard according to the PG-core mapping, and will run in the context of the same shard/CPU until completion. 通常,当从 Messenger 收到 IO 作时,将根据 PG 核心映射将其定向到 OSD 分片,并将在同一分片/CPU 的上下文中运行,直到完成
Note that in the current phase the design choice not to modify the RADOS protocol has been made for simplicity.
请注意,在当前阶段,为了简单起见,已选择不修改 RADOS 协议。
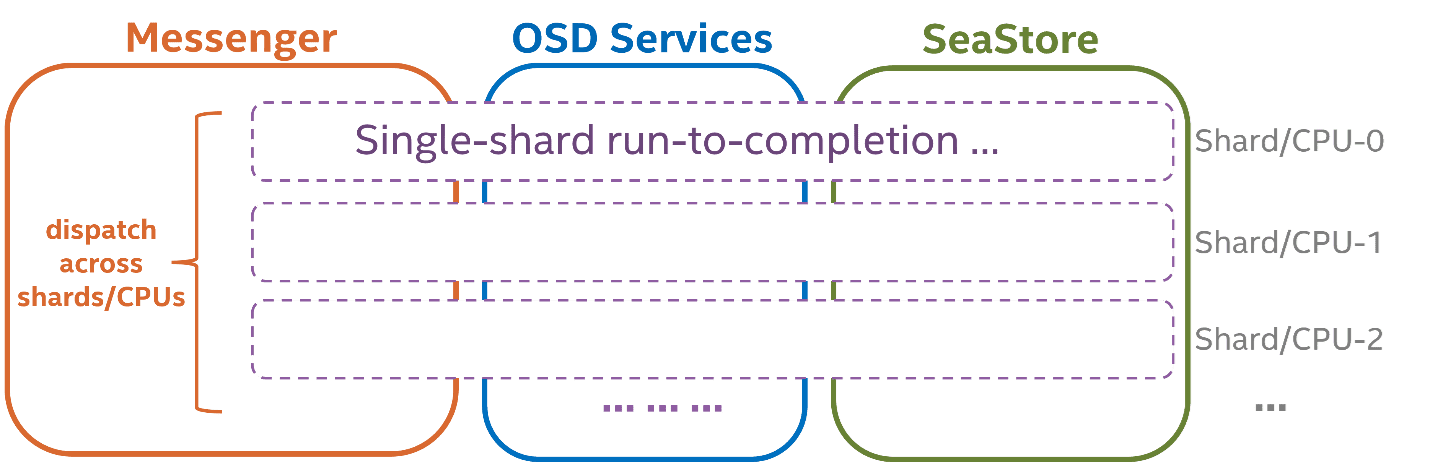
用一个比喻说明
-
单栈滑雪道:所有滑雪者(请求)都在同一条滑道(线程/核)上滑下来,排队等待。
-
多栈滑雪道:根据滑雪者的编号(PG ID),他们被分配到不同的滑道(核心)上去滑。
-
滑道内部:拐弯、加速等操作(IO 逻辑)都一样,不管你在哪条滑道。
-
滑道之间:极少数滑雪者会被移到另一条滑道(跨核通信,比如全局状态更新),但这不干扰"滑雪体验主流程"。
-
OSD
OSD is responsible for maintaining global status and activities shared between PG shards, including heartbeat, authentication, client management, osdmap, PG maintenance, access to the Messenger and ObjectStore, and so on.
OSD 负责维护 PG 分片之间共享的全局状态和活动,包括检测信号、身份验证、客户端管理、osdmap、PG 维护、对 Messenger 和 ObjectStore 的访问等。
A simple principle towards a multi-core Crimson OSD is to keep all processing relating to shared state on a dedicated core. If an IO operation wants to access the shared resource, it either needs to access the dedicated core in order, or to access an exclusive copy of the shared information that is kept synchronized.
多核 Crimson OSD 的一个简单原则是将与共享状态相关的所有处理都保存在专用内核上。如果 IO 作想要访问共享资源,它要么需要按顺序访问专用核心,要么访问保持同步的共享信息的独占副本。
There are two major steps to achieve this goal. The first step is to allow IO operations to run in multiple OSD shards according to the PG sharding policy, with all the global information including PG status maintained in the first shard. This step enables sharding in the OSD but requires all the decisions about IO dispatching to be made in the first shard. Even if the Messenger can run in multiple cores at this step, messages will still need to be delivered to the first shard for preparation (PG peering, as an example) and determining the correct PG shard before being submitted to that shard. This can result in extra overhead and unbalanced CPU utilization (the first OSD shard is busy and other shards are starved, etc). So, the next step is to extend the PG-core mapping to all the OSD shards, so that the received message can be dispatched to the correct shard directly.
实现此目标有两个主要步骤。第一步是允许 IO 作根据 PG 分片策略在多个 OSD 分片中运行,包括 PG 状态在内的所有全局信息都保留在第一个分片中。此步骤在 OSD 中启用分片,但要求在第一个分片中做出有关 IO 调度的所有决策。即使 Messenger 可以在此步骤中在多个内核中运行,消息仍需要传送到第一个分片进行准备(例如 PG 对等连接)并确定正确的 PG 分片,然后再提交到该分片。这可能会导致额外的开销和 CPU 利用率不平衡(第一个 OSD 分片繁忙,其他分片不足等)。因此,下一步是将 PG-core 映射扩展到所有 OSD 分片,以便可以将收到的消息直接分派到正确的分片。
ObjectStore ¶ ObjectStore ( 对象存储) ¶
There are three ObjectStore backends supported for Crimson: AlienStore, CyanStore and SeaStore
AlienStore provides backward compatibility with BlueStore . CyanStore is a dummy backend for tests, implemented by volatile memory. SeaStore is a new object store designed specifically for Crimson OSD with shared-nothing design. The paths towards multiple shard support are different depending on the specific goal of the backend.
Crimson 支持三个 ObjectStore 后端:AlienStore、CyanStore 和 SeaStore。AlienStore 提供与 BlueStore 的向后兼容性。CyanStore 是一个用于测试的虚拟后端, 由 volatile 内存实现。SeaStore 是专为 Crimson OSD 设计的新对象存储,采用无共享设计。根据后端的具体目标,实现多个分片支持的路径会有所不同。
AlienStore
AlienStore is a thin proxy in the Seastar thread to communicate with BlueStore that uses POSIX threads, (alien world from a Seastar perspective). There is no special work to do towards multiple OSD shards because the IO tasks are already synchronized for alien world communications. There are no Crimson specific customizations in the BlueStore because it is impossible to truly extend the BlueStore into shared-nothing design as it depends on the 3rd party RocksDB project which is still threaded. However, it is acceptable to pay reasonable overhead in exchange for a sophisticated storage backend solution, before Crimson can come up with a native storage backend solution (SeaStore) which is optimized and stable enough.
AlienStore 是 Seastar 线程中的一个瘦代理,用于与使用 POSIX 线程的 BlueStore 通信(从 Seastar 的角度来看是外星世界)。对于多个 OSD 分片,无需执行特殊工作,因为 IO 任务已与外星世界通信同步。BlueStore 中没有特定于 Crimson 的自定义,因为不可能真正将 BlueStore 扩展到无共享设计中,因为它依赖于仍然线程化的第三方 RocksDB 项目。但是,在 Crimson 提出足够优化和稳定的本机存储后端解决方案 (SeaStore) 之前,支付合理的开销以换取复杂的存储后端解决方案是可以接受的。
CyanStore
CyanStore in Crimson OSD is the counterpart of MemStore in the Classic OSD.
The only change towards multiple-shard support is to create independent CyanStore instances per shard. One goal is to make sure the dummy IO operation can complete in the same core to help identify OSD-level scalability issues if there are any. The other goal is to do direct performance comparisons with the Classic at the OSD level without complex impacts from the ObjectStore.
Crimson OSD 中的 CyanStore 是经典 OSD 中 MemStore 的对应物]。
多分片支持的唯一变化是为每个分片创建独立的 CyanStore 实例。一个目标是确保虚拟 IO 作可以在同一内核中完成,以帮助识别 OSD 级别的可扩展性问题(如果存在)。另一个目标是在 OSD 级别与 Classic 进行直接性能比较,而不会受到 ObjectStore 的复杂影响。
SeaStore
SeaStore is the native ObjectStore solution for Crimson OSD, which is developed with the Seastar framework and adopts the same design principles.
SeaStore 是 Crimson OSD 的原生 ObjectStore 解决方案,它是使用 Seastar 框架开发的,并采用相同的设计原则。
Although challenging, there are multiple reasons why Crimson must build a new local storage engine. Storage backend is the major CPU resource consumer, and the Crimson OSD cannot truly scale with cores if its storage backend cannot. Our experiment also proves that the Crimson OSD is not the bottleneck in the random write scenario.
尽管具有挑战性,但 Crimson 必须构建新的本地存储引擎的原因有很多。存储后端是主要的 CPU 资源消耗者,如果 Crimson OSD 的存储后端不能,则 Crimson OSD 无法真正使用内核进行扩展。我们的实验还证明,Crimson OSD 并不是随机写入场景中的瓶颈。
Second, the CPU-intensive metadata managements with transaction support in the BlueStore are essentially provided by RocksDB, which cannot run in the native Seastar threads without reimplementation.
Rather than re-implementing the common purpose key-value transactional storage for BlueStore, it is more reasonable to rethink and customize the according designs at a higher level - the ObjectStore. Issues can be solved more easily in the native solution than in the 3rd-party project which must be general to all the use cases that may be even unrelated.
其次,BlueStore 中具有事务支持的 CPU 密集型元数据管理基本上是由 RocksDB 提供的,如果不重新实现,它就无法在本地 Seastar 线程中运行。 与其为 BlueStore 重新实现通用的键值事务存储,不如在更高级别 - ObjectStore 重新考虑和自定义相应的设计。与第三方项目相比, 在本地解决方案中可以更轻松地解决问题,因为第三方项目必须适用于所有甚至可能不相关的用例。
The third consideration is to bring up native support to heterogeneous storage devices as well as hardware accelerators that will allow users to balance costs and performance according to their requirements. It will be more flexible for Crimson to simplify the solution to deploy the combination of hardware if it has better controls over the entire storage stack.
第三个考虑因素是提供对异构存储设备以及硬件加速器的原生支持,这将允许用户根据自己的需求平衡成本和性能。如果 Crimson 对整个存储堆栈有更好的控制,那么简化解决方案以部署硬件组合将更加灵活。
SeaStore is already functional in terms of single shard reads and writes, although there are still efforts left for stability and performance improvement. The current efforts are still focused on the architecture rather than corner-case optimizations. Its design for the multiple-shard OSD is clear. Like the CyanStore, the first step is to create independent SeaStore instances per OSD shard, each running on a static partition of the storage device. The second step is to implement a shared disk space balancer to adjust the partitions dynamically, which should be fine to run in the background asynchronously because the PGs have already distributed the user IO in a pseudo random way. The SeaStore instances may not need to be equal to the number of OSD shards, adjusting this ratio is expected as the third step according to the performance analysis.
SeaStore 在单分片读取和写入方面已经正常运行,尽管仍有努力提高稳定性和性能。 目前的工作仍然集中在架构上,而不是极端情况下的优化。它对多分片 OSD 的设计很明确。 与 CyanStore 一样,第一步是为每个 OSD 分片创建独立的 SeaStore 实例, 每个实例都在存储设备的静态分区上运行。 第二步是实现共享磁盘空间平衡器来动态调整分区, 这在后台异步运行应该没问题,因为 PG 已经以伪随机方式分发了用户 IO。 SeaStore 实例可能不需要等于 OSD 分片的数量,根据性能分析,调整此比率预计是第三步。
Summary and Test configurations 摘要和测试配置
In this article,
we have introduced why and how the Ceph OSD is being refactored to keep up with the
hardware trends, 在本文中,我们介绍了为什么以及如何重构 Ceph OSD 以跟上硬件趋势
design choices made, performance results for single-shard run-to-completion implementation, 所做的设计选择、单分片运行到完成实现的性能结果
and the considerations to make Crimson OSD truly multi-core scalable.
以及使 Crimson OSD 真正具有多核可扩展性的注意事项。
Test scenarios:
- Client: 4 FIO clients
- IO mode: random write and then random read
- Block size: 4KB
- Time: 300s X 5 times to get the average results
- IO-depth: 32 X 4 clients
- Create 1 pool using 1 replica
- 1 RBD image X 4 clients
- The size of each image is 256GB
Test environment:
- Ceph version (SHA1): 7803eb186d02bb852b95efd1a1f61f32618761d9
- Ubuntu 20.04
- GCC-12
- 1TB NVMe SSD as the BlueStore block device
- 50GB memory for MemStore and CyanStore
| 特性 | RDMA | DPDK | XDP |
|---|---|---|---|
| 工作层级 | 用户态 | 用户态 | 内核态 |
| 核心机制 | 直接内存访问,支持单边操作 | 用户态轮询,直接访问网卡 | eBPF 程序在驱动层处理数据包 |
| 零拷贝支持 | ✅ 是(硬件支持) | ✅ 是(用户态内存池) | ✅ 是(AF_XDP 模式) |
| 延迟表现 | 极低(μs 级,适用于 HPC 和存储) | 低(适用于高吞吐场景) | 低(适用于 L2/L3 层快速处理) |
| 典型应用场景 | 分布式存储、AI 训练、HPC | NFV、SDN、网络负载均衡 | DDoS 防护、边缘过滤、内核态负载均衡 |
| 硬件依赖 | 高(需支持 RDMA 的 NIC,如 RoCE、InfiniBand) | 中(需支持 DPDK 的 NIC) | 低(大多数网卡支持,部分功能需驱动支持) |
| 控制面处理 | 用户态 API,需注册内存和队列对 | 用户态线程控制,需管理内存池和队列 | 内核态 eBPF 管理,用户态可通过 AF_XDP 交互 |
| 3FS 集群由 180 个存储节点组成,每个存储节点配备 2×200 Gbps InfiniBand 网卡和 16 个 14TiB NVMe SSD。180 节点聚合读取吞吐量达到约 6.6 TiB/s。 |
3FS 主要有 4 大核心:Cluster Manager,Metadata Service,Storage Service 和 Client,各个模块之间都使用 RDMA 网络连接
https://deepseek.csdn.net/67c6d414d649b06b61c7d28a.html?utm_source=chatgpt.com 内核旁路(Kernel Bypass)是一种高性能计算和网络通信领域的重要技术,其核心思想是绕过操作系统内核
以下是针对初学者从零基础到掌握内核旁路(Kernel Bypass)技术的系统学习计划,涵盖理论知识、实战技能和项目实践,适用于网络开发、系统性能优化或高性能计算领域的工程师。
🧭 学习路径概览
| 阶段 | 目标 | 关键内容 | 推荐时间 |
|---|---|---|---|
| 阶段 1 | 打下基础 | 操作系统、网络协议、Linux基础 | 1–2 周 |
| 阶段 2 | 理解内核旁路原理 | DPDK、XDP、UIO、NUMA、零拷贝 | 2–3 周 |
| 阶段 3 | 动手实践 | 搭建环境、运行示例、性能测试 | 2–4 周 |
| 阶段 4 | 项目实战 | 构建高性能网络应用、调优 | 4–6 周 |
| 阶段 5 | 进阶与拓展 | eBPF、RDMA、云原生网络 | 持续学习 |
🧩 阶段 1:基础知识
目标:掌握操作系统和网络通信的基本概念,为深入学习内核旁路技术打下坚实基础。
学习内容:
-
操作系统原理:进程与线程、内存管理、系统调用、上下文切换等。
-
计算机网络基础:TCP/IP协议栈、Socket编程、网络I/O模型。
-
Linux基础:Shell命令、文件系统、进程管理、网络配置。(The Byte)
推荐资源:
-
《操作系统概念》 by Abraham Silberschatz
-
《计算机网络:自顶向下方法》 by James F. Kurose
-
Linux官方文档和在线教程
⚙️ 阶段 2:理解内核旁路原理
目标:深入理解内核旁路技术的原理、优势以及常见实现方式。
学习内容:
-
内核与用户空间的通信机制。
-
内核旁路的动机:减少上下文切换、降低延迟、提高吞吐量。
-
主要技术:
推荐资源:
-
DPDK官方文档:
-
XDP教程和示例代码:
-
UIO驱动开发指南:(华为开发者空间)
🛠️ 阶段 3:动手实践
目标:搭建实验环境,运行内核旁路技术的示例程序,进行性能测试。
实践内容:
-
搭建DPDK开发环境:配置HugePages、绑定网卡驱动。
-
运行DPDK示例程序:如l2fwd(Layer 2 Forwarding)。
-
使用XDP加载eBPF程序,实现简单的数据包过滤。
-
性能测试:使用工具如iperf、pktgen进行网络性能评估。(博客园)
推荐资源:
-
DPDK官方示例代码:
-
XDP教程和示例代码:
-
Linux网络性能测试工具指南:
🚀 阶段 4:项目实战
目标:应用所学知识,开发高性能网络应用,进行性能优化和调试。
项目建议:
-
开发基于DPDK的网络负载均衡器。
-
实现基于XDP的防火墙或数据包过滤器。
-
构建高性能网络监控系统,实时分析网络流量。(华为开发者空间)
优化技巧:
-
使用大页内存(HugePages)减少TLB miss。
-
绑定线程到特定CPU核心,减少上下文切换。
-
利用NUMA架构优化内存访问。
🌐 阶段 5:进阶与拓展
目标:探索内核旁路技术的高级应用和未来发展方向。
学习内容:
-
eBPF(Extended Berkeley Packet Filter):内核可编程性增强。
-
RDMA(Remote Direct Memory Access):远程直接内存访问技术。
-
云原生网络:如Cilium、Kube-Proxy的替代方案。
-
安全性与隔离性:内核旁路技术在安全领域的挑战与对策。(维基百科)
推荐资源:
📚 推荐学习资源
-
DPDK官方文档:
-
XDP教程和示例代码:
-
《Linux高性能服务器编程》 by 游双
-
《深入理解Linux网络内幕》 by Christian Benvenuti
通过以上系统的学习计划,您将能够从零基础逐步掌握内核旁路技术,具备开发高性能网络应用的能力。在实践过程中,建议多参与开源社区,阅读相关项目的源代码,提升实战经验。
如果您有兴趣,我可以为您推荐一些具体的开源项目和实践案例,帮助您更好地应用所学知识。
到底什么是TCP/IP协议栈,看完这篇你就明白!
https://www.caimore.com/NEWS-show-1401.html
RocksDB 源码分析 – I/O
https://youjiali1995.github.io/rocksdb/io/
page cache 是什么数据结构组成的?如何存储,如何查找,
从架构师角度回答,并且考虑细节
- 避免背诵 八股文,只是概念,没考虑实际项目情况和知识情况
- 背景 大学课程和实际10 年项目开发经验
https://youjiali1995.github.io/essay/2023-summary/我在 PingCAP 一共待了3年8个月,是我目前职业生涯(6年7个月)的 55.7%。离开 PingCAP 倒不是不看好它的发展,也不是自己发展的不好,而是数据库对我来说太难了。
我认为它仍是中国 infra 领域技术水平最高、最尊重人的公司之一。PingCAP 有着不错的企业文化且 WLB;有着完善的新人培养体系也对新人非常耐心,新人参与到复杂且成熟的项目中来,会在代码、测试、可观测性、排查和解决问题、合作等各个方面得到培养和提升;
这个领域也过于内卷,比如卷 TPC-C 等 benchmark,很可能过度满足了市场的需要,出现了性能的过度供给,既创造不了行业价值也不能为用户创造价值。最有效的竞争方式并不是卷,而是提供全新的功能和体验在另一个维度竞争,实现降维打击。产品如此,人也如此。
苦难本身没有任何意义,苦难就是苦难。难的事情不代表它本身需要那么难,更可能是基础、方向错了,基础要打牢,要在正确的方向、框架上做,而不是在不正确的框架上补,什么都想做很可能什么都做不好,壮士断腕的魄力和决心不是每个人都有的。
异步编程核心是 event loop,基本模型都是单个/多个线程/进程阻塞在 epoll 这种 I/O 多路复用的系统调用,有事件就绪一般就在当前线程直接处理了,长时间的工作会扔到单独的线程池里执行,防止阻塞 event loop。Rust 把这一整套模型拆成了多个部分