C++面试周刊(5):程序员必须知道的数字|搞定长尾延迟青铜秒变王者

文章目录
各位老师好!
这是CPP面试冲刺周刊 (c++ weekly) 陪你一起快速冲击大厂面试 第5期
周刊目标:
- 不是成为C++专家,而是成为C++面试专家
本期内容:
- 程序员必须知道的数字,不知道就会被坑
避坑指南:
- 如果你熟悉C++17/20特性,你说用的GCC版本是4.8,这个就是说谎!至少需要7.x
- 假如你研究分布式存储,提供io_uring、NUMA架构,操作系统内核版本如果是3.x,你说谎!至少需要5.x
- 延迟数据的“温柔陷阱”:99% vs 99.99%
历史文章:
一、背景
在大规模分布式系统和高并发场景下, 很多线上故障的根源都不是“代码写错”,而是交付一个产品 依赖环境信息太多了
你必须知道的数字包括:
- 操作系统版本(Linux Kernel)
- glibc 版本(GNU C Library)
- 软件依赖版本(例如 Redis、MySQL、Kafka)
- 核心性能指标(延迟、P99、P999)
- 系统资源限制(
ulimit、文件描述符数量)
这些数字看似琐碎,但在实际生产环境中,99% 的线上事故都和版本、性能指标、依赖库相关。
| 案例 | 版本变化 | 问题 | 损失 | 解决办法 |
|---|---|---|---|---|
| 美团 tcache 内存膨胀 | glibc 2.28 | 新增 tcache 导致内存暴涨 | 宕机 4 小时 | 降级 glibc,关闭 tcache |
| 某券商内核升级 | Linux 4.18 → 5.10 | epoll 退化 | TPS 降低 30% | 打补丁 + 参数调优 |
| Redis ACL 性能劣化 | Redis 5.0 → 6.2 | ACL 权限校验开销大 | CPU+200% | 关闭 ACL 或升级客户端 |
| Kafka 客户端崩溃 | Kafka 2.3 → 3.1 | 协议版本不兼容 | 整个集群不可用 | 降级客户端 |
二、操作系统内核版本:决定你能用哪些特性
2.1 为什么关心操作系统内核版本
Linux 内核和发行版不是“版本号”,而是“能力边界”。
操作系统版本不仅仅是一个数字,它直接决定了 glibc、IO 栈、内核调度 等底层行为。
案例1:CentOS 7.6 → 7.9 升级导致Redis性能雪崩
案例背景
一家互联网公司在线上环境把 CentOS 7.6 → 7.9,glibc 从 2.17 升级到了 2.28。
升级完成后,Redis QPS 从 10w/s 掉到 2w/s,延迟从 0.3ms 飙升到 2ms+。
排查过程
- 怀疑 Redis 自身问题,重启无效
- 怀疑内核参数,调整 TCP backlog 无效
- 最终通过
perf top和strace发现,大量线程阻塞在malloc_trim→madvise(MADV_DONTNEED)系统调用上 - 根因:glibc 2.28 引入了
malloc_trim的 aggressive 策略,导致频繁释放内存到 OS,引起内核锁竞争 - 根因分析:glibc 升级至 .28 后,
malloc_trim策略更激进,大量内存回收触发频繁锁竞争。 大量大键在短时间内过期,触发了 Redis 的延迟删除机制,而随后触发的 glibc malloc_trim 操作阻塞了主线程,导致命令响应超时。 - 解决:通过
MALLOC_TRIM_THRESHOLD_=0禁用自动 trim,性能恢复。 export MALLOC_TRIM_THRESHOLD_=0 - 禁用自动trim的潜在代价是,Redis进程可能会比之前占用更多的常驻内存(RSS),因为很少主动将空闲内存归还OS
- 效果: 在启动Redis服务前设置此环境变量后,Redis的内存分配器不再频繁尝试将内存交还操作系统,从而避免了激烈的锁竞争。测试表明,此操作后Redis的QPS立即恢复到了升级前的10万/s水平,系统态CPU占用也回归正常。
- 对于Redis这类高性能内存数据库,社区普遍推荐使用
jemalloc 作为默认内存分配器,其性能和多线程扩展性通常优于ptmalloc2。在编译Redis时可通过make MALLOC=jemalloc指定,这可以从根本上避免此类ptmalloc2的问题。
搜索关键词:
- CentOS 7.6 7.9 Redis 性能下降
- glibc 2.28 malloc_trim https://github.com/mruby/mruby/issues/5047
- 内存泄漏之malloc_trim
- MALLOC_TRIM_THRESHOLD_ Redis 性能
- 在 nosql 系统中发现的内存暴增现象及其潜在原因
- https://www.slideshare.net/slideshow/glibc-memory-management/10455454
总结:
- 最少知识:
- 在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap 这些系统调用实现的
- mmap:glibc大内存是128k,majflt对于性能的损害是致命的,随机读一次磁盘的耗时数量级在几个毫秒
- 当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)导致 cpu 增加,缓存不命中
- 禁止malloc调用mmap分配内存,禁止内存紧缩
案例 2 io_uring 导致 Ngin 短链性能下降
2021 年某金融交易系统升级内核从 4.18 → 5.10,结果导致 Nginx 性能下降 30%,
因为新内核默认启用了 io_uring,但是应用并没有适配。
- io_uring在网络编程方面的优化更适合长连接场景,在长连接场景下最高有20%多的提升。短连接场景还有待优化,短连接场景,io uring相对于event poll非但没有提升,甚至在某些场景下有5%~10%的性能下降
- epoll:
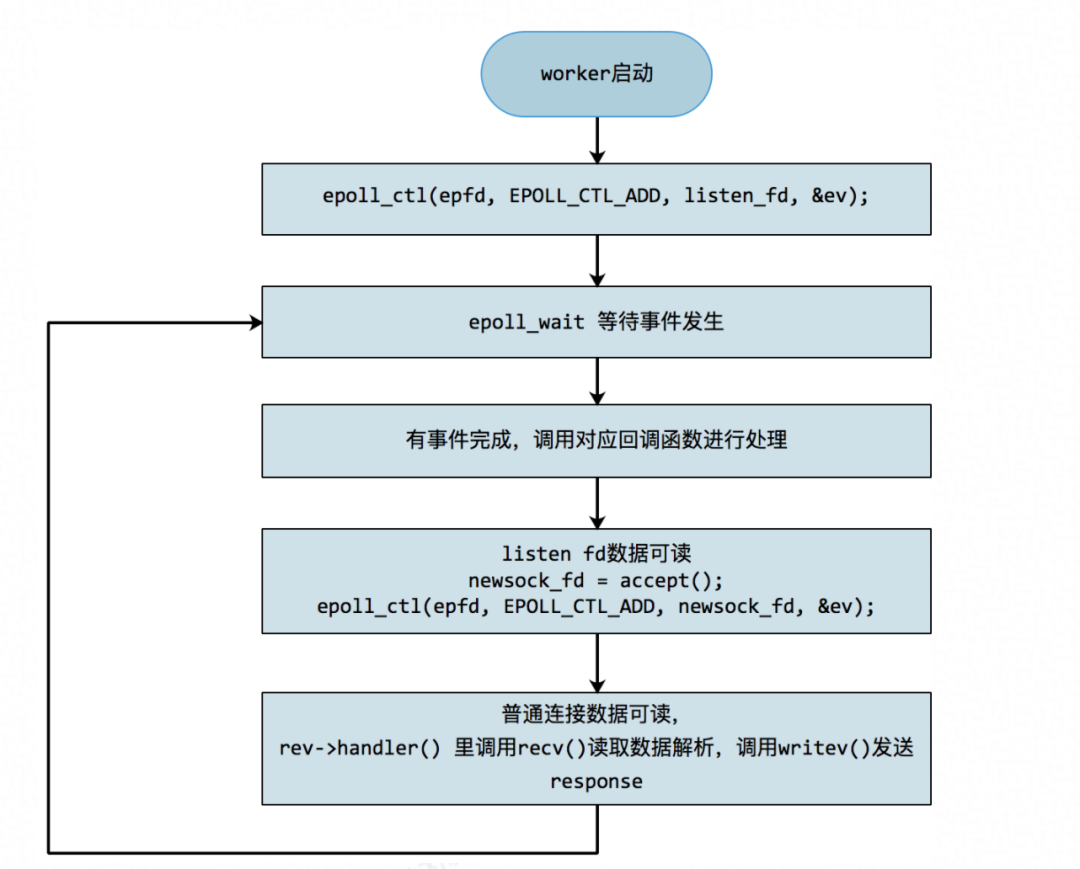
- io_uring
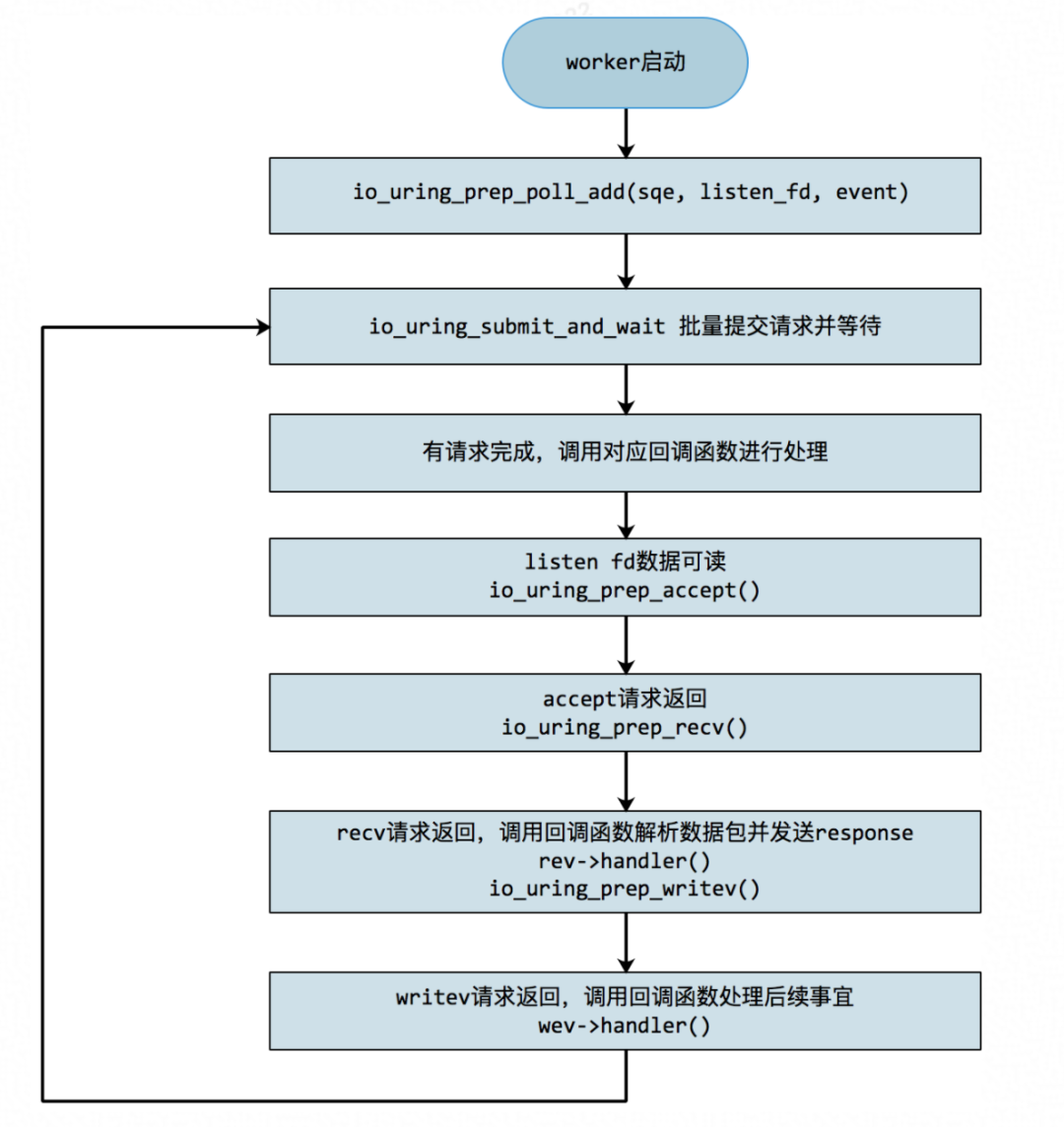
我们曾帮某公司做 TiDB 集群迁移,开发同事为了追求高性能,在 5.4 内核上开发并启用了 io_uring。
结果一上线,RHEL7(内核 3.10)直接报错:
|
|
原因:3.10 内核根本不支持 io_uring 系统调用。
代价:紧急回滚 + 重写 IO 模型,损失一周时间。
2.2 内核版本查看
| 发行版 | 代表版本 | 为什么重要 | 查看命令 |
|---|---|---|---|
| CentOS/RHEL 7 | 内核 3.10,glibc 2.17 | 大量生产环境仍在用,缺少 io_uring、statx 等系统调用 |
name -r |
| CentOS/RHEL 8 | 内核 4.18,glibc 2.28 | 引入 cgroup v2、内核 eBPF 增强 |
同上 |
| Ubuntu 20.04 | 内核 5.4,glibc 2.31 | io_uring 支持良好 | lsb_release -a |
| Ubuntu 22.04 | 内核 5.15,glibc 2.35 | 高性能 IO、BPF tracing、密钥管理更完善 | 同上 |
| Alpine | 3.17+ | 轻量 Docker 基础镜像,但用 musl 而非 glibc,兼容性坑点多 |
cat /etc/alpine-release |
更多信息:https://www.kernel.org/
| 内核版本 | 重点特性/改动 | 应用关注点/影响 |
|---|---|---|
| 3.x (2011-2015) | - 改进了 Ext4、Btrfs 文件系统 - 支持新的硬件架构(ARM、PowerPC) - 引入了 perf_event 性能计数器增强 - 初步支持 cgroups v1 |
- 文件系统优化对 I/O 性能有影响 - cgroups 可用于资源限制和容器化 |
| 4.x (2015-2019) | - 支持 overlayfs,为容器提供文件系统支持 - 改进 TCP/IP 网络栈 - 引入 io_uring 的初步概念(4.19 预备接口) - 支持更大内存 (>64GB) 和 NUMA 改进 - 安全增强:Seccomp、Live Patching 初步支持 |
- 容器和微服务性能提升 - 高并发网络应用受 TCP 栈优化影响 - 高性能异步 I/O 可预期,但需适配 |
| 5.x (2019-至今) | - 正式引入 io_uring 异步 I/O(5.1) - 增强多队列支持,减少内核锁竞争(5.6+) - 改进 cgroups v2、BPF 功能 - 支持 CPU 架构优化(AMD Zen、ARM64 SVE) - 内核增强安全特性:Lockdown 模式、堆隔离、KASLR 强化 - 支持更高效的 epoll/wait queue、内存管理优化 |
- 高频交易、低延迟应用可通过 io_uring 获取性能优势 - 容器化、资源管理更灵活 - 系统调用行为微调可能影响老应用性能 |
⚠️ 重要总结与建议
-
CentOS 7:已结束官方支持
-
CentOS 8:已提前终止维护,不应在任何新环境部署。
- 替代方案:原 CentOS 的继任者是 CentOS Stream(滚动发布版本)。对于需要稳定、免费且与 RHEL 二进制兼容的用户,
- 推荐迁移至:Rocky Linux
三、gcc 版本是多少?
3.1 gcc与c++标准库有关
| GCC 版本 | 默认 C++ 标准 | 支持 libstdc++ 特性 | 对应 glibc 兼容性 |
|---|---|---|---|
| 4.8 | C++11 | 智能指针、std::thread |
glibc ≥ 2.17 |
| 4.9 | C++11/C++14部分 | std::make_unique |
glibc ≥ 2.18 |
| 5.1 | C++14 | 完整 C++14 支持 | glibc ≥ 2.19 |
| 6.x | C++14/C++17部分 | std::optional(部分) |
glibc ≥ 2.23 |
| 7.x | C++17 | 完整 C++17 支持 | glibc ≥ 2.25 |
| 8.x | C++17/C++20部分 | std::span(部分) |
glibc ≥ 2.28 |
| 9.x | C++17/C++20 | 完整 C++20 支持 | glibc ≥ 2.28 |
| 10.x+ | C++20 | 完整 C++20/部分 C++23 | glibc ≥ 2.30 |
如果你学习 c++20 语法,你说用的 gcc 版本是 4.8 这个就是说谎呀?
gcc –version
gcc (GCC) 8.5.0 20210514 (Tencent 8.5.0-23)
| 系统 | glibc | GCC | C++ 标准 | 问题/注意事项 |
|---|---|---|---|---|
| RHEL7 / CentOS7 | 2.17 | 4.8 | C++11 | std::make_unique 需要 backport;std::filesystem 不可用 |
| Ubuntu 18.04 | 2.27 | 7.5 | C++17 | 完整支持 C++17;IO/线程性能稳定 |
| Ubuntu 20.04 | 2.31 | 9.3 | C++20 | 默认可用 std::span、std::format;注意向下兼容 |
| Debian 11 | 2.31 | 10.2 | C++20 | 适合新特性,但需注意部分 glibc API 对 kernel 要求 |
3.2 为什么要了解
- 系统化的编译,为 Ceph 带来 15%-30% 的综合性能提升是完全可行的,尤其是在 CPU 密集型和内存密集型工作负载下
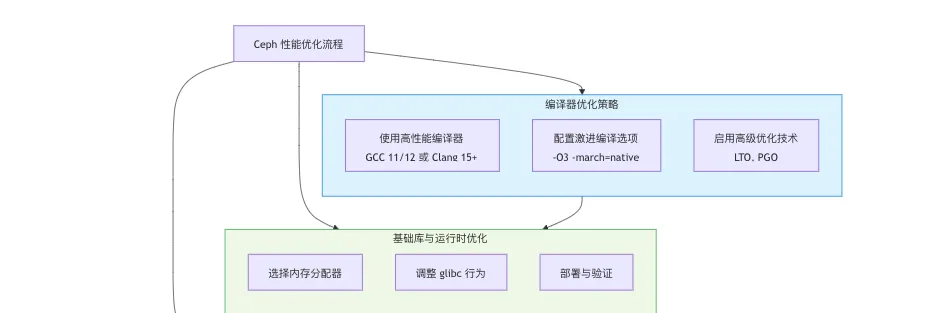
命令速查
|
|
Ceph 性能极度依赖 CPU 效率,尤其是对数据路径(如 OSD 的 librados)的编译优化至关重要。
| 优化策略 | 具体命令/配置 | 预期收益 | 风险与故障 |
|---|---|---|---|
| 1. 使用新版编译器 | 使用 GCC 11/12 或 Clang 15+ 替代系统旧版 GCC(如 4.8.5)。 | 新编译器对现代 CPU(如 Zen 3, Ice Lake)支持更好,自动向量化优化可带来 ~5% 的性能提升。 | 新编译器可能引入极少数未知 bug,需通过完整功能测试。 |
| 2. 激进优化选项 | CFLAGS="-O3 -march=native -mtune=native" CXXFLAGS="-O3 -march=native -mtune=native" |
-march=native生成最适合当前 CPU 指令集的二进制码,可提升 ~10-15% 的计算密集型任务性能。 |
致命风险:二进制码与当前 CPU 强绑定,迁移到不同架构(如从 Intel 迁至 AMD)会导致非法指令崩溃。 |
| 3. 链接时优化 (LTO) | CFLAGS="-flto=auto"并在链接时也添加 -flto=auto。 |
允许编译器跨文件优化,消除未使用的代码路径,减小二进制体积并提升性能 ~1-3%。 | 大幅增加编译时间和内存消耗,可能遇到链接器 bug。 |
| 4. 性能导向优化 (PGO) | 分三步: 1. 编译插桩版本:-fprofile-generate 2. 用真实负载训练(如 cosbench) 3. 用采集数据重新编译:-fprofile-use |
编译器根据真实运行 profile 优化热点代码,可获得 ~10% 以上的最大性能收益。 | |
| Ceph 是内存和锁密集型应用,尤其 OSD 进程频繁分配/释放内存。 |
| 优化策略 | 具体命令/配置 | 预期收益 | 风险与故障 |
|---|---|---|---|
| 1. 替换内存分配器 | 使用 jemalloc或 tcmalloc替代 glibc 的 ptmalloc2。 ./configure --with-jemalloc |
解决多线程内存分配锁竞争,显著降低内存碎片。提升高并发场景性能 ~5-20%,并稳定延迟。 | 增加依赖复杂性。极端情况下,分配器自身可能成为瓶颈(需监控)。 |
| 2. 调整 glibc malloc 行为 | 针对仍使用 ptmalloc2的场景: export MALLOC_ARENA_MAX=4 export MALLOC_MMAP_THRESHOLD_=131072 |
MALLOC_ARENA_MAX限制内存域数量,控制内存碎片化和总内存占用。MMAP_THRESHOLD_调整分配策略。 |
MALLOC_ARENA_MAX设置过低可能增加锁竞争,需根据线程数调整。 |
| 3. 禁用自动内存归还 | export MALLOC_TRIM_THRESHOLD_=0 |
彻底阻止 glibc 频繁调用 malloc_trim,消除由此引发的性能毛刺和锁竞争。对 RocksDB(Ceph 后端)等性能提升显著 |
四、 软件版本:
除了操作系统和 glibc,应用软件的版本差异同样会坑你。
4.1 以 Redis 为例
案例1 背景
某公司 Redis 4.0 在 RHEL7 上运行正常,
但迁移到 Debian11(glibc 2.31)后,
CPU 占用率暴涨到原来的 3 倍。
原因
- Redis 内部大量使用
jemalloc,但 glibc 2.31 在mmap+munmap策略上和老版本差异极大 - jemalloc 老版本未适配新 glibc 的
madvise策略,导致频繁 Page Fault 结论 - 数字:Redis 4.0 + glibc 2.17 → CPU 20%
- 数字:Redis 4.0 + glibc 2.31 → CPU 60%
- 解决:升级 Redis 至 6.2,jemalloc 新版优化了 mmap 行为
五 、延迟
5.1 基本数字
什么是延迟?指 API 响应请求所需的时间
P99(也称为 99th percentile,99百分位数)是衡量系统响应时间分布的一个 统计指标, 代表在所有请求中,99%的请求的响应时间 小于或等于该值, 而只有1%的请求比它慢。
| 指标 | 含义 | 优缺点 |
|---|---|---|
| 平均响应时间 | 所有请求响应时间的平均值 | 易受极端值影响,不能反映尾部延迟 |
| P99响应时间 | 99%的请求响应时间小于该值 | 更能反映极端情况下的性能瓶颈 |
| 操作 | 耗时 | 说明 |
|---|---|---|
| L1 Cache | ~1ns | CPU 最近缓存 |
| L2 Cache | ~4ns | |
| L3 Cache | ~10ns | 多核共享 |
| DRAM | ~100ns | 大量随机访问会爆慢 |
| 本地 NVMe 读 | 50μs - 150μs | Ceph、TiDB IO 核心 |
| 10GbE RTT | ~100μs | 数据中心常见 |
| RDMA RTT | 1-2μs | 极限低延迟 |
| 系统调用 | 100ns - 1μs | futex()、getpid() |
| 磁盘落地写 | 1-10ms | WAL / Binlog 性能关键 |
L1 cache reference ……………………. 0.5 ns Branch mispredict ………………………. 5 ns L2 cache reference ……………………… 7 ns
Mutex lock/unlock ……………………… 25 ns Main memory reference …………………. 100 ns
Compress 1K bytes with Zippy …………. 3,000 ns = 3 µs Send 2K bytes over 1 Gbps network ……. 20,000 ns = 20 µs SSD random read …………………… 150,000 ns = 150 µs
Read 1 MB sequentially from memory ….. 250,000 ns = 250 µs Round trip within same datacenter …… 500,000 ns = 0.5 ms Read 1 MB sequentially from SSD* ….. 1,000,000 ns = 1 ms
Disk seek ……………………… 10,000,000 ns = 10 ms Read 1 MB sequentially from disk …. 20,000,000 ns = 20 ms Send packet CA->Netherlands->CA …. 150,000,000 ns = 150 ms
5.2 长尾延迟 → P99 比平均值更重要
线上系统调优时,平均耗时毫无意义,必须盯住 P99 / P999:
| 项目 | 内容 |
|---|---|
| P99定义 | 99%的请求响应时间低于该值 |
| 作用 | 定位尾部延迟,优化极端慢请求 |
| 监控方式 | 使用 Prometheus/Grafana/Datadog + Tracing |
| 优化手段 | 限流、缓存、异步化、输入优化、模型推理优化 |
P99与P999的区别
- P99:关注99%的请求(容忍1%的慢请求)。
- P999:更严格,99.9%的请求需达标(如金融交易系统)。
案例 1:Ceph 集群长尾
某 Ceph 集群平均 IO 延迟只有 5ms,但用户经常投诉“慢”。
分析 P999 后发现,1‰ 的请求耗时高达 1.2s。
最后定位到:
- 页缓存回收
- NUMA 跨节点访问
- futex 竞争
通过优化线程绑核 + 提升 glibc futex 实现,P999 降低 70%。
案例2 Redis 作为高性能缓存数据库的典型案例来看:
-
场景:金融交易系统使用 Redis 缓存热点数据,要求 P99 < 5ms,P999 < 20ms。
-
问题:在高并发下发现 P999 达到 50ms,远高于 P99。
-
原因分析:
-
大 key 阻塞:偶尔存在大对象 GET 操作阻塞其他请求。
-
内存碎片/GC:频繁过期或大对象回收导致延迟尖峰。
-
网络抖动:少数节点网络延迟增加尾部请求时间。
-
-
优化措施:
-
对大 key 使用异步分片读取或拆分策略
-
调整 Redis maxmemory 策略和碎片整理策略
-
在高峰期增加节点,避免单点热点阻塞
-
-
效果:
- P99 从 4.5ms 降至 4ms
- P999 从 50ms 降至 18ms
✅ 实践表明,Redis 的尾部延迟优化必须结合系统设计、缓存策略和网络条件综合考虑。
六、总结
- 操作系统版本 → 决定能不能用 io_uring、eBPF 等现代特性
- glibc 版本 → 决定二进制是否能跑
- 软件版本 → 不同内核和依赖的兼容坑
- 性能耗时数字 → 提前知道数量级,少走弯路
- 长尾延迟 → P99 比平均值更重要
广告时间
c++周刊目的陪你一起快速冲击大厂面试
小提示:不要把他看成一个出售给你产品,我只出售给自己 在公司做任何事情事情, 都必须清楚拆解需求功能,开发周期,最后得到什么结果, 同样面试准备也是如此,给自己一个期限 21 天,给自己大纲,然后给自己 21 天学习结果,这样自己才能安心准备下去。
曾经有一个让我心跳加速的岗位放在我面前,
我没有珍惜。
等到别人拿到 offer 的那一刻,
我才追悔莫及!
人世间,最痛苦的事情,
不是没钱吃饭,
也不是没房没车,
而是——错过了那个能让我逆天改命的机会!
如果上天再给我一次机会,
我一定会对那个岗位说三个字:
“我要你!”
如果非要在这份“心动”上加一个期限,
一万年太久了……
我只想要——21天!
你可能面临两种选择
① 犹豫不前:准备到天荒地老
“这个岗位太难了,我先准备一下吧。”
于是你准备1天、1周、1个月、1年……
等再回头,3年就这样过去了。
- 每天忙着搬砖,没时间系统复习
- 每次想起要准备,又感觉心里没底
- 面试知识点更新太快,拿着旧地图找新机会 最后,错过了一次又一次心动的岗位。
② 盲目回答:机会就在眼前,却抓不住
终于等来一场面试,
你觉得问题很简单,张口就答,
结果用“几千元思维”回答“百万年薪岗位”。
- 面试官问到C++底层实现,答不上来
- 设计题说到高并发架构,没实战经验
- 一紧张,连项目里真实做过的东西都讲不清
一次面试失利,也许就意味着和理想岗位失之交臂。
更残酷的是
在你犹豫的这几年里,
找工作的成本越来越高:
- 一个部门、一个领导,可能坚持一年就被解散
- 一个项目,可能在10年、20年后,
曾经复杂的业务规则、先进的架构,早已被淘汰 - 市场上新的技术和面试要求,每年都在不断升级
等你回过头来,发现不仅机会没了,
连准备的方向都变了。
21天C++面试冲刺周刊

不是让你成为C++专家, 而是让你成为C++面试专家。
不是让你疯狂学习新知识, 而是帮你重新整理已有知识,
让你的能力与面试题精准对齐。
因为,21天就够了,
足够让我火力全开,
- 一边补齐 C++ 知识点,
- 一边刷爆经典面试题,
- 一边撸穿开源项目,
- 让自己变得不可替代!
核心方法论:
让你学到每个 c++知识,都关联一个经典面试,并对对应开源项目实践
- 系统备战
每天 20~30 分钟,聚焦 C++ 核心知识,
三周时间完成高效梳理。 - 经典面试题
每个知识点都关联一个高频面试题,
让你知道“为什么考”和“怎么答”。 - 开源项目实践
通过真实项目理解底层原理,
不背答案,而是用实践打动面试官。 - 场景驱动学习
还原真实面试场景,
帮你学会“怎么说服面试官”。
21天,你会获得什么?
- 一份完整的C++面试知识地图
- 一套高频题+解析+项目实践组合拳
- 一次全链路模拟面试体验
- 三周后,面对面试官,你能自信说出:
“问吧,准备好了。”
这也是我的面试方法:
-
如果一开始就直接学某个知识点,我常常感觉不到它的实际价值。
-
所以我会先尝试树立一个整体的大局观,就算过程中被现实“啪啪打脸”了又怎样?
-
把每一次面试都当成一场陪练,用面试官的专业视角和真实项目来反推和校正自己的理解,不是更好吗?这种即时、高质量的反馈,是你看多少书、自己一个人闷头琢磨多久,都很难获得的。 整体知识看板(欢迎提供更多线索):
-
第一周:c++基础知识高频面试题解析【当前位置】

-
第二周: 专注分布式存储,数据库广告搜索 Ai 辅助驾驶 大厂热门后端领域项目(基本功)拆解
-
第三周:系统架构设计,用未来 10 年发展目标,重新设计原来系统
最动人的作品,为自己而写,刚刚好打动别人
1️⃣ 如果有更多疑问,联系小王,一起交流,进步

2️⃣ 关注公众号:后端开发成长指南(回复"面经"获取)获取过去我全部面试录音和面试复盘。

抬头看天:走暗路、耕瘦田、进窄门、见微光
- 不要给自己这样假设:别人完成就等着自己完成了,大家都在一个集团,一个公司,分工不同,不,这个懒惰表现,这个逃避问题表现。
- 别人不这么假设,至少本月绩效上不会写成自己的,至少晋升不是你,裁员淘汰就是你。
- 目标:在跨越最后一道坎,拿百万年薪,进大厂。