面试官:为什么大厂拒绝使用shared_ptr(shared_ptr vs intrusive_ptr)?

文章目录
各位老师好(老师是山东对人的尊称,就像称呼帅哥美女一样)
C++周刊 (c++ weekly)第二期开始了
本期预告:
- 本期我们将深入理解shared_ptr
- 帮你破解大厂经典面试题智能指针使用场景
- 并解读它在开源项目具体实现。 周刊目标:
- 让你学到每个 c++知识,都关联一个经典面试,并对对应开源项目实践
一、主题阅读:c++高频面试题
| 序号 | 知识地图 | 题目 |
|---|---|---|
| 1 | 新特性 | 一分钟讲透:c++新特性string_view |
| 2 | 库的编译链接 | 如何给一个高速行驶的汽车换轮胎(实现一个可扩展c++服务) |
| 3 | STL | Traits 技术 |
| 4 | 新特性 | if constexpr |
| 5 | 新特性 | 面试题:C++中shared_ptr是线程安全的吗? |
| 6 | 模板 | C++17 新特性 std::optional |
| 7 | class | c++类的成员函数,能作为线程的参数吗 |
| 8 | 编译器 | const 如何保证const不变 |
| 9 | 值语义 | 一道面试题看深拷贝构造函数问题 |
| 10 | 值语义 | 智能指针究竟在考什么 |
| 11 | 指针 | 使用 C++ 智能指针遇到的坑 |
二、Ceph 为什么放弃大量使用 shared_ptr
| 阶段 | 特点 | 问题 | 优化 |
|---|---|---|---|
| 早期 | 大量使用 shared_ptr 捕获 this |
循环引用、内存泄漏 | 改成 weak_ptr |
| 中期 | shared_ptr 在百万 IOPS 下性能瓶颈 |
5~15% CPU 时间耗在原子操作上 | 引入 intrusive_ptr |
| 后期 | 进一步优化异步回调 | 异步 lambda 多层嵌套仍可能泄露 | 状态机 + 弱引用管理 |
| 模块 | 历史实现 | 问题表现 | 现状 |
|---|---|---|---|
| AsyncMessenger | 原始版大量 std::shared_ptr<Connection> |
回调闭包循环引用;锁竞争高 | 全面迁移 intrusive_ptr |
| ObjectCacher | 老版本使用 shared_ptr<Object> |
高频拷贝带来 10% CPU overhead | 新版部分改 intrusive_ptr,部分用裸指针 |
| BlueStore | shared_ptr<Buffer>、shared_ptr<Extent> |
buffer 分配 + 原子操作开销大 | 大量切 intrusive_ptr |
| Objecter | 用 shared_ptr<Op> 追踪请求 |
回调泄漏问题明显 | 改 intrusive_ptr + 智能 weak 回调 |
| librados | 客户端 API 仍暴露 shared_ptr |
兼容性考虑 | 对外 shared_ptr,内部 intrusive_ptr |
2.1 问题背景
Ceph 没有完全放弃 shared_ptr,但在核心路径上几乎全部替换成 intrusive_ptr。【why】
在 Ceph 的设计中, 几乎所有核心模块(ObjectCacher、AsyncMessenger、BlueStore 等) 都会频繁创建和销毁对象【有什么影响】
在这种高并发、高 IOPS 的场景中,shared_ptr 的几个特性变成了性能瓶颈。
1. 性能问题:原子引用计数过慢
shared_ptr 内部维护一个 控制块,包含:
- 对象指针
- 原子引用计数(strong + weak)
- 自定义 deleter
在 Ceph 这种热点路径中,每次增减计数都触发 原子操作 → CPU 开销非常高。[why]
问题示例:
|
|
在一个100GB/s带宽、百万IOPS的集群中,假设每个IO请求在生命周期内平均经历10次 shared_ptr的拷贝/析构,那么每秒就会发生 100万 * 10 = 1000万次 原子操作。
Profiling 发现,仅仅是执行这些原子操作,就可能消耗掉 5-15% 的总CPU时间。
这意味着CPU有超过十分之一的算力没有用于处理真正的数据
来源 :reddit
Slow assignment operations. 赋值操作缓慢
- Assigning to a
shared_ptrrequires a synchronized atomic operation, which is over 10 times slower than a raw pointer assignment. - 对
shared_ptr进行赋值需要同步原子操作,这比原始指针赋值慢 10 倍以上 - The slowdown is even greater for highly concurrent code.
- 对于高并发代码,这种速度下降更为显著
来源:# Evaluating the Cost of Atomic Operations on Modern Architectures
- 在测试的多个 Xeon、Ivy Bridge、Haswell 架构上,原子操作(如 CAS 和 Fetch-and-Add)都有很高的延迟,而且即使指令没有依赖关系,原子操作也会破坏指令级并行性。
- 这说明在高频场景下,每一次原子操作都可能成为性能瓶颈
2 内存碎片
一个 std::shared_ptr<T>的生命周期需要至少两次内存分配(如果不使用 make_shared):
new T:分配对象本身。- new control_block`:分配控制块(包含引用计数、弱计数、删除器等)。
即使使用 make_shared优化,将两次分配合并为一次,
控制块和对象T仍然在内存上是紧邻的同一个内存块。这带来了新的问题:
-
内存放大与碎片化: 假设
T很小(比如一个几十字节的请求头),但控制块的大小是固定的(通常为几十字节)。这导致每个逻辑对象实际占用的内存远大于其数据本身,降低了内存使用效率。频繁创建和释放数百万个这样的混合块,会严重加剧内存碎片化。 -
缓存不友好(Cache Unfriendly): 这是更隐蔽的性能杀手。当代码访问
T的数据成员时,它会把整个内存块(包含控制块)加载到CPU缓存行(通常为64字节)中。
3 循环引用:回调链释放不掉
eph 在底层大量使用 事件驱动 + 异步回调 模型,特别是在网络通信、对象缓存、IO 路径上,比如:
AsyncMessenger:处理消息收发。- ObjectCacher`:管理对象缓存。
BlueStore:底层存储引擎,所有读写异步完成后用回调通知上层- Ceph 大量使用异步回调模式,
shared_ptr捕获this导致循环引用。
2018 年左右的 Ceph Luminous → Mimic 演进中引入,提交记录可以追溯到:
commit: ceph/ceph@4b6c9ef
title: “msg/async: avoid shared_ptr cycles by using weak_ptr in callbacks”
在 Ceph 的 src/msg/async/AsyncMessenger.cc 中,有大量异步消息收发和回调,比如:
|
|
过去 Ceph 在这块遇到的典型问题:
-
当客户端关闭连接时,
AsyncConnection预期应该析构。 -
但由于 lambda 捕获了
self,直到回调触发前,这个对象都无法释放。 -
如果连接中断,回调可能永远不会触发,造成内存泄漏。
**解决办法:弱引用 (这个办法不好,上来无法判断是否产生循环)
2.2 解决办法:
intrusive_ptr 的核心思想
The intrusive_ptr class template stores a pointer to an object with an embedded reference count
intrusive_ptr 来自 Boost,但 Ceph 做了定制优化:
boost::intrusive_ptr
- boost::intrusive_ptr一种“侵入式”的引用计数指针,它实际并不提供引用计数功能,
- 而是要求被存储的对象自己实现引用计数功能,
- 并提供intrusive_ptr_add_ref和intrusive_ptr_release函数接口供boost::intrusive_ptr调用。
- 为什么 intrusive_ptr 没有进入标准库?
- boost::intrusive_ptr为什么叫做倾入指针
|
|
| 特性 | intrusive_ptr |
std::shared_ptr |
|---|---|---|
| 内存开销 | 一次分配。计数器在对象内部,无额外控制块。 | 两次分配(或一次合并分配)。有外部控制块开销。 |
| 内存布局 | 缓存友好。对象和计数器在一起,常在同一缓存行。 | 可能缓存不友好。对象和控制块可能分离。 |
| 性能 | 稍高。无额外分配,缓存局部性更好。但原子操作开销仍在。 | 稍低。有分配开销,可能缓存不友好。 |
| 侵入性 | 是。必须修改类定义,添加计数器和友元函数。 | 否。无需修改类即可使用,是非侵入式的。 |
| 易用性 | 复杂。需要手动实现引用计数逻辑,容易出错。 | 简单。开箱即用,自动化程度高。 |
| 适用场景 | 1. 极致性能优化(如Ceph)。 2. 需要与已有内置引用计数的C结构体交互。 3. 需要与shared_ptr共享所有权(但不能直接转换)。 |
绝大多数通用场景。安全、方便,是默认首选。 |
| 特性 | shared_ptr(标准库) |
intrusive_ptr(Ceph) |
|---|---|---|
| 引用计数存储位置 | 堆外,独立 control block | 对象内嵌在类中 |
| 原子操作 | 每次拷贝/析构都原子 | 可选,局部无锁优化 |
| 生命周期管理 | 自动 | 自动 |
| 内存占用 | 需要额外分配 control block | 零额外分配 |
| 循环引用 | 容易发生 | Ceph 通过弱引用 + 显式解环 |
| 性能 | 高并发下性能瓶颈 | Ceph 实测降低 5~10% CPU 消耗 |
核心优化点:
-
引用计数内嵌 → 少一次内存分配
-
原子操作可控 → 大部分情况下局部无锁
-
更容易做 weak_ptr → 避免循环引用
2.2.2 举例说明
|
|
然后 intrusive_ptr 会这样调用:
|
|
三、oceanbase禁用智能指针
不允许使用智能指针,允许通过 Guard 类自动释放资源。
boost 库支持智能指针,包括 scoped_ptr、shared_ptr 以及 auto_ptr。
很多人认为智能指针能够被安全使用,尤其是 scoped_ptr,
不过 OceanBase 已有代码大多都手动释放资源,且智能指针用得不好容易有副作用,
因此,不允许使用智能指针。
OceanBase 禁止智能指针不是倒退,而是一种在特定领域(高性能基础软件)下的高级工程权衡。
| 比较 | std::shared_ptr | OceanBase方案 |
|---|---|---|
| 引用计数 | 原子操作,开销大 | 轻量级原子操作 |
| 内存布局 | 控制块和数据分离 | 可合并分配 |
| 跨线程传递 | 依赖原子操作 | 消息队列 + 引用计数 |
| 任务调度 | 无内置支持 | 内置线程池 + 任务队列 |
| 缓存友好性 | 差 | 好 |
| 内存分配 | 2次 | 1次(合并分配) |
OceanBase 跨线程对象传递的完整解决方案
-
明确所有权管理 - 使用 ObSharedGuard 替代 shared_ptr,提供更精确的控制
-
自定义引用计数 - 轻量级原子操作,避免 std::shared_ptr 的开销
|
|
- 消息队列/Actor模型 - 线程池 + 任务队列,实现线程间的安全通信
class ObOccamThreadPool
三、总结:
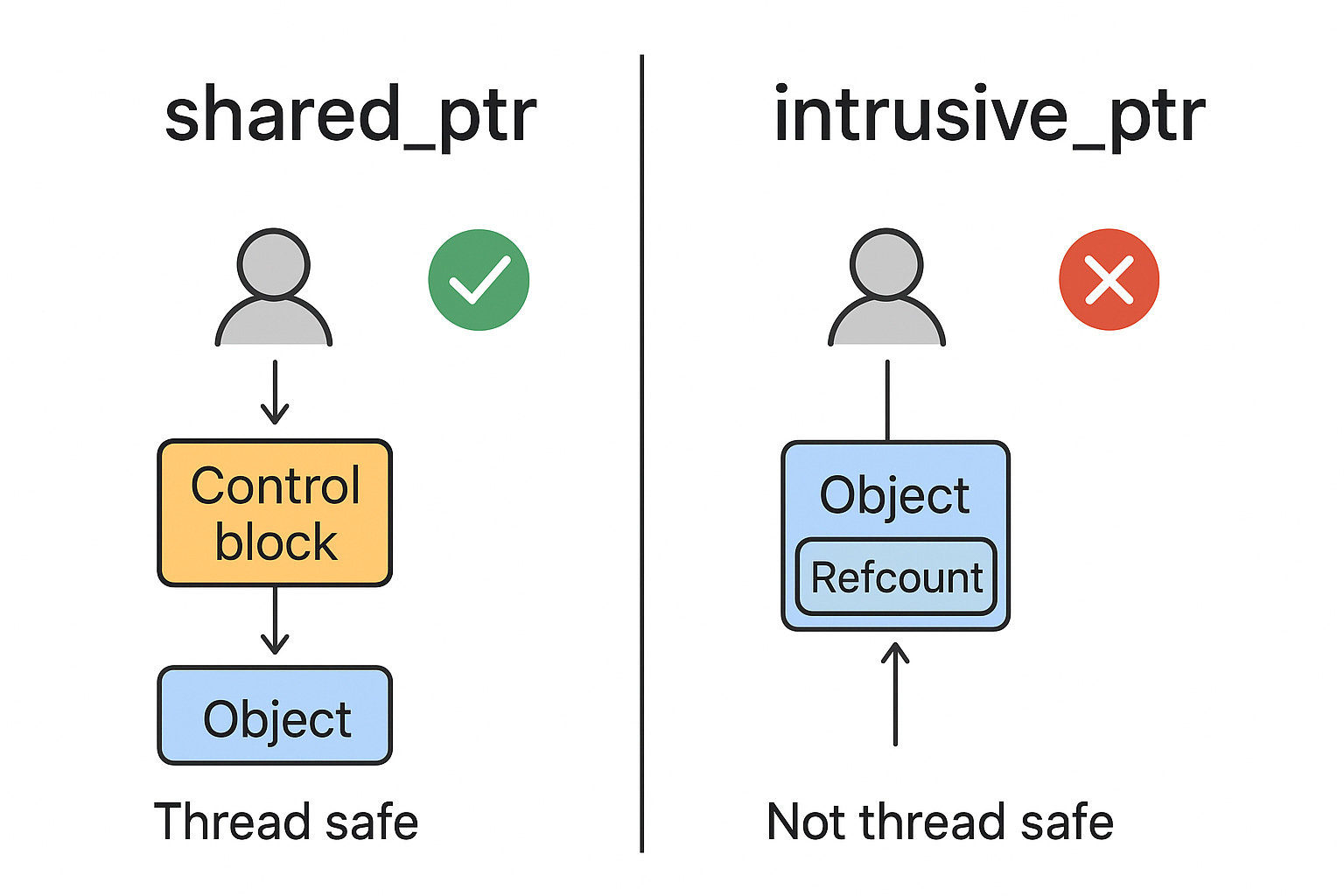
| 特性 | shared_ptr |
intrusive_ptr |
|---|---|---|
| 引用计数位置 | 独立控制块 | 对象内部 |
| 线程安全 | 原子操作,线程安全 | 默认非线程安全 |
| 内存开销 | 控制块额外开销 | 无额外开销 |
| 性能 | 原子操作略慢 | 高性能,需手动管理线程安全 |
| 使用复杂度 | 低,直接使用 make_shared |
高,需要对象实现 add_ref/release |
| 循环引用风险 | 可能,需要 weak_ptr |
可能,需要手动管理 |
| 典型应用 | 普通 C++ 项目,多线程共享 | 高性能库/缓存对象(如 Ceph) |
最后 如何保证线程安全
-
与
shared_ptr对比-
shared_ptr内部引用计数是 原子操作,在多个线程中复制、销毁智能指针是安全的。 -
intrusive_ptr需要你自己保证在多线程访问时加锁或使用原子计数。
-
-
实际使用方式
-
单线程场景:直接使用
intrusive_ptr就安全。 -
多线程场景:
-
可以把
refcount定义成std::atomic<int>,或者 -
在外部加锁管理对象生命周期。
-
-
经典书籍
-
Effective Modern C++: 42 Specific Ways to Improve Your Use of C++11 and C++14
-
C++20 模板元编程
 推荐语:
玄之又玄,众妙之门
推荐语:
玄之又玄,众妙之门
什么是玄而又玄呢?传统的解释有很多种,对多数程序员来说,都不大好理解。
在我看来,玄就是抽象。玄之又玄,就是抽象了再抽象。 (Ai目前还做不到)
人类的大脑喜欢生动具体的东西,比如小孩子都喜欢听故事, 无论是“小马过河” 还是“后羿射日”都有具体的场景、“人”和物。 长大了以后喜欢刷剧也是类似的原因。 每部剧都在一个具体的时空中讲一个故事。没有哪部剧没有人物,只有“道可道,非 常道”。
因此,做抽象是很难的事情。也因此,很多代码都是不够抽象的,
- 今天需要 int 类 型的 max()函数,那么就写个int 类型的;
- 明天需要float 类型的,就把int 类型的复制一 份,改成float 类型的。
- 日积月累,整个项目里就有很多长相类似的代码了。
- 如何提炼这样的代码,消除重复,把它们合众为一呢?
- 传统C++中的模板技术就是为解决这个问题而设计的,现代C++将其发扬光大,去 除约束,增加功能,使其成为现代C++语言的一大亮点。
- 对于希望深入掌握C++的开发者而言,理解模板是进阶C++编程的必经之路。从泛 型编程(Generic Programming)、模板元编程(Template Metaprogramming),到C++20 概 念(Concepts),这些技术都在现代C++开发中占据了重要地位。
参考资料
- https://csguide.cn/cpp/memory/shared_ptr.html
- https://www.reddit.com/r/cpp/comments/1bo6boj/stdshared_ptr_is_poor_gc_c_shouldnt_be_poor/
- https://stackoverflow.com/questions/2139266/avoiding-indirect-cyclic-references-when-using-shared-ptr-and-weak-ptr
- https://www.boost.org/doc/libs/1_89_0/libs/smart_ptr/doc/html/smart_ptr.html#intrusive_ptr