Linux高性能网络详解从 DPDK、RDMA 到 XDP(上)

文章目录
【注意】最后更新于 August 7, 2024,文中内容可能已过时,请谨慎使用。
点击蓝色关注。
文末有福利,先到先得


一、明确学习目的和方式
1. 看招聘岗位
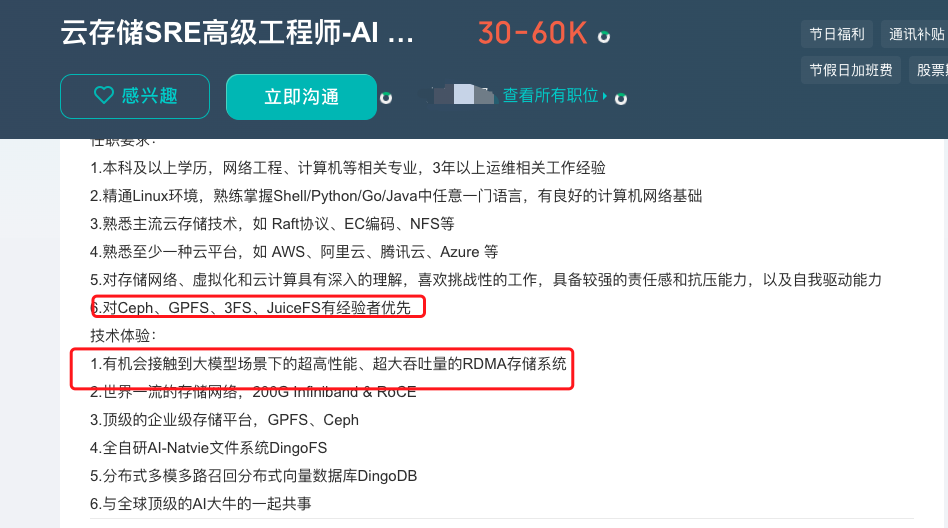
6.对Ceph、GPFS、3FS、JuiceFS有经验者优先
技术体验:
1.有机会接触到大模型场景下的超高性能、超大吞吐量的RDMA存储系统
2.世界一流的存储网络,200G Infiniband
2. 只看一本书 我选择这本

- 来源 https://www.zhihu.com/question/657890643
- 为了节省成本 我我选择电子书
- 电子书上传到微信读书,上下班等公交车看一 看
3. 了解作者,搜索作者公开视频,加速理解

-
刘伟,拥有 14 年网络设备开发领域的从业经验,当前就职于浪潮电子信息产业股份有限 公司体系结构研究部,负责高性能网卡的架构设计和驱动程序开发工作。在此之前,曾以驱 动团队和网络接入设备产品开发负责人的身份在上海诺基亚贝尔固网事业部工作了 7 年;还 曾经就职于中兴通讯和上海爱吉信息技术有限公司,负责多款通信产品的研发工作
-
作者刘伟老师还在B站放了自己的课程录播,方便学习::浪潮信息驱动工程师: RDMA 高性能架构基本原理、设计方案优点等介绍 | 龙蜥大讲堂 83 期
-
ppt 地址 :https://www.yuque.com/anolis-docs/courses/peczxk


-
文章:# 高性能网络通信架构 RDMA 的设计与实现https://www.infoq.cn/article/d9w4NK2l1Pi8FIMi24K4
序言:
二、看视频笔记:RDMA 高性能架构设计 | 龙蜥大讲堂83期
socket过程
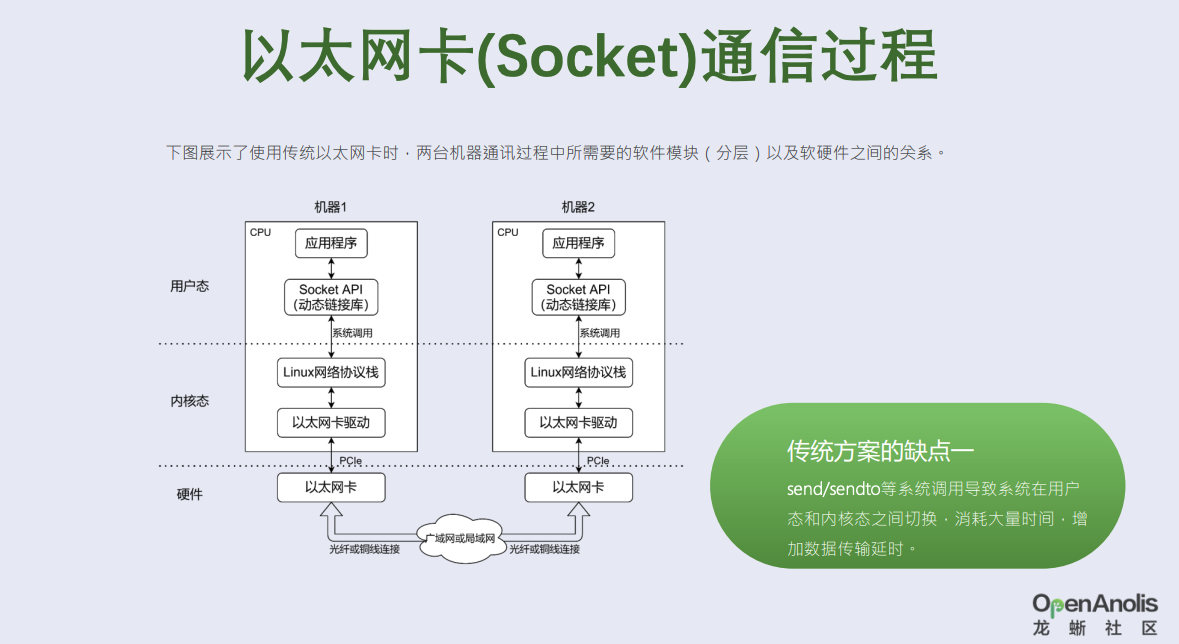
小义提问1 :王者:可以直接说系统调用耗时大,我是青铜,我思考是什么是系统调用?和函数调用有什么区别?
调试用户态程序
int main() { read(fd, buf, 100); }
用 gdb ./your_binary 调试时:
- 你 看不到内核栈
- 因为系统调用发生后,CPU进入内核态执行的是 OS 的代码,不属于你的进程空间
📌 所以你在 gdb 里最多能看到调用 read() 这一层,然后就跳出去了
| 用户态函数 | 内核态系统调用 |
|---|---|
socket() |
sys_socket |
bind() |
sys_bind |
listen() |
sys_listen |
accept() |
sys_accept4 |
connect() |
sys_connect |
read()/recv() |
sys_read / sys_recvfrom |
write()/send() |
sys_write / sys_sendto |
close() |
sys_close |
| 阅读: | |
| https://www.cnblogs.com/gtarcoder/articles/5278074.html |
假设用户运行 bash执行命令:
bash调用fork()→ 内核为新子进程分配 task_struct 和内核栈- 子进程执行
execve("/bin/ls")→ 加载新程序,重置用户栈(原有用户栈被释放) ls程序调用write()→ 触发栈切换:- CPU 自动切到该进程的内核栈
- 内核用此栈保存寄存器、参数
ls退出 → 内核释放该进程的内核栈和 task_struct
- 内核栈是进程描述符(
task_struct)的核心成员,其生命周期与进程绑定。 - 用户态无法感知内核栈存在,硬件在中断/系统调用时自动切
切换过程如下:
另外一个例子: 05 | 栈的魔法:从栈切换的角度理解进程和协程
为什么一次 fork 后,会有两种不同的返回值?这是 因为 fork 方法本质上在系统里创建了两个栈,这两个栈一个是父进程的,一个是子进程的。 创建的时候,子进程完全“继承”了父进程的所有数据,包括栈上的数据
小义提问2 :内核栈多大,长什么样子
| 项目 | Linux 早期(<4.x) | Linux 5.x |
|---|---|---|
task_struct 和内核栈 |
一起分配(紧凑) | 分开分配 |
thread_info |
独立结构 | 内嵌在内核栈底部 |
task_struct 如何找栈 |
指针 task->stack |
同样 |
| 内核如何找回当前任务 | 栈 → thread_info → task | 每 CPU 存 current_task 指针,优化性能 |
参考:
- kernel 3.10内核源码分析–内核栈及堆栈切换https://100why.cn/content/1894681.html
- Linux进程内核栈与thread_info结构详解–Linux进程的管理与调度(九) https://blog.csdn.net/gatieme/article/details/51577479
- 进程在内核态运行时需要自己的堆栈信息, 因此linux内核为每个进程都提供了一个内核栈kernel stack
- 在 Linux 5.x 中,
task_struct是单独分配的结构,而内核栈是通过alloc_thread_stack_node()分配的固定大小内存(8KB/16KB),
task_struct里包含了一个stack指针,用来指向它自己的内核栈
小义提问3:用户栈,内核栈,网络协议栈区别?
| 维度 | 用户栈 (User Stack) | 内核栈 (Kernel Stack) | 网络协议栈 (Network Stack) |
|---|---|---|---|
| 所属空间 | 用户空间 | 内核空间 | 内核空间(部分逻辑在用户空间) |
| 所有者 | 每个用户进程独有 | 每个进程/线程独有 | 全局共享(所有进程共用) |
| 核心作用 | 存储用户程序运行时的临时数据 | 存储内核态代码执行时的上下文 | 分层处理网络数据包(收发、路由等) |
| 操作对象 | 函数参数、返回地址、局部变量等 | 系统调用参数、中断上下文、寄存器值 | 网络数据包(sk_buff结构) |
| 生命周期 | 进程创建时分配,退出时销毁 | 进程创建时分配,退出时销毁 | 系统启动时初始化,关机时销毁 |
| 触发场景 | 用户函数调用 | 系统调用、中断、异常 | 数据包到达网卡/用户发送网络请求 |
| 访问权限 | 用户程序可读写 | 仅内核态代码可访问 | 仅内核态代码可访问 |
| 典型大小 | MB 级(可动态扩展) | 固定 8KB~16KB | 无固定大小,动态管理缓冲池 |
sk_buff是 Linux 内核网络子系统中用于描述网络数据包的结构体,它是放在内核堆(heap)里的内核数据结构,不是内核栈,也不会存在于栈空间。
| 项目 | sk_buff |
内核栈(kernel stack) |
|---|---|---|
| 是什么 | struct sk_buff,用于描述网络包及其元数据 | 每个线程进入内核时分配的执行栈 |
| 属于哪块内存 | 内核堆(kmalloc、slab 分配器) | 内核栈空间(固定 8KB / 16KB) |
| 生命周期 | 由网络子系统控制,通常存在较长时间 | 临时的:只在系统调用、中断期间生效 |
| 数据用途 | 包含 IP/TCP 头、payload、控制信息等 | 保存内核函数的调用栈、局部变量、返回地址等 |
| 是否可以被中断使用 | ✅ 可以被软中断等使用 | ❌ 内核栈不可重入、不可并发使用 |
| 每线程是否唯一 | ❌ 否,多个线程共享使用 | ✅ 是,每个线程一个内核栈 |
 |
Linux内核:sk_buff解析 https://www.cnblogs.com/tzh36/p/5424564.html
https://linuxkernel.org.cn/doc/html/latest/networking/skbuff.html
以太网卡的数据流

- 需要CPU全程参与数据包的封装和解析, 在数据量大时将对CPU将造成很重的负担。
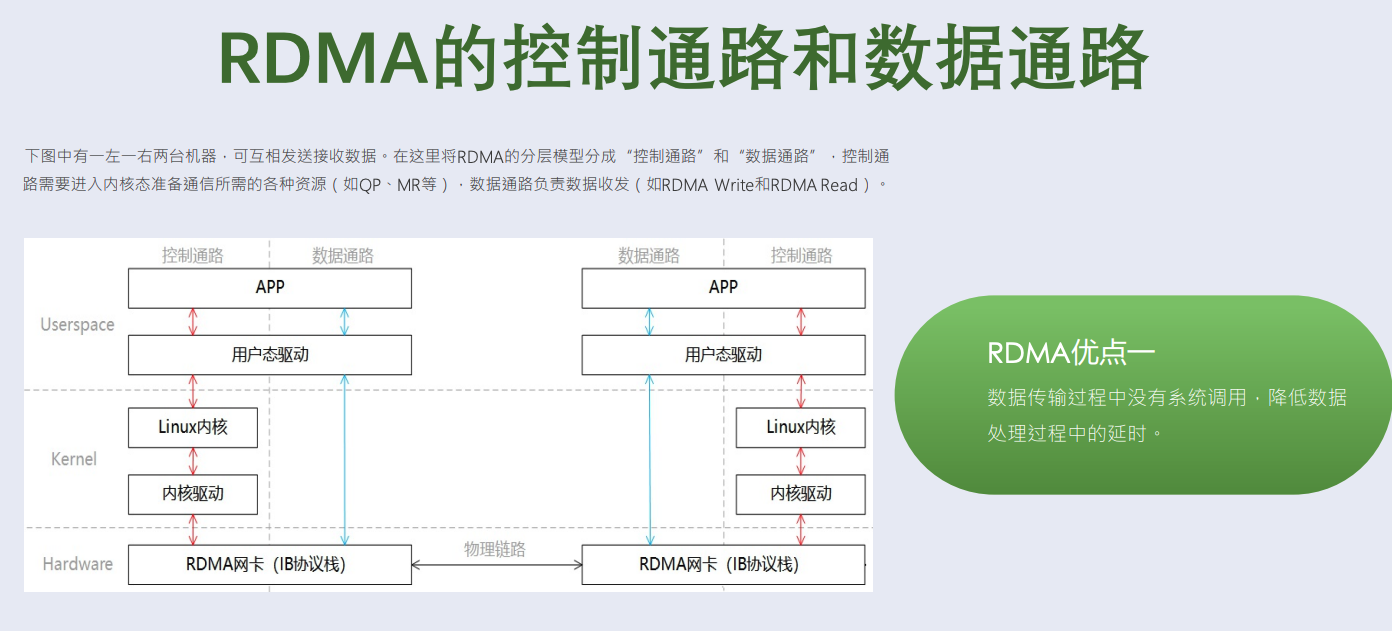
小义提问 4:rdma 完全不需要内核吗?数控分离是什么意思
| 比较维度 | 控制通路(Control Path) | 数据通路(Data Path) |
|---|---|---|
| 主要职责 | 初始化资源,准备通信 | 发送、接收数据 |
| 是否需内核? | ✅ 是 | 否(用户态完成) |
| 是否频繁调用? | 初始化阶段调用一次 | ✅ 高频调用 |
| 是否绕过内核? | 否 | ✅ 是,zero-copy |
| 是否性能敏感? | 否 | ✅ 是(对吞吐和延迟非常敏感) |
| RDMA(Remote Direct Memory Access)架构中的控制通路和数据通路分离是高性能网络的核心设计,这种分层模型彻底解耦了资源管理和数据传输,以下是深度解析: |
🔌 控制通路 (Control Path)
作用
在内核态创建、配置和管理通信资源,确保数据通路的可靠性和安全性。 核心操作
-
QP(Queue Pair)创建
- 发送队列(SQ)和接收队列(RQ)组成,需内核分配内存并初始化权限。
-
MR(Memory Region)注册
1 2 3// 用户态:申请内存并注册为 MR void *buf = malloc(SIZE); ibv_reg_mr(pd, buf, SIZE, IBV_ACCESS_REMOTE_WRITE);- 内核将用户内存的物理地址映射给网卡,供远程直接访问。
- 内存钉住(Pinning):锁定物理页禁止换出(确保 DMA 地址有效)。
-
CQ(Completion Queue)关联
- 内核建立事件通知机制,当数据传输完成时通知用户态。
⚠️ 为何需进入内核态?
资源涉及硬件访问、内存隔离、进程权限等敏感操作,必须由内核强制保护!
🚀 数据通路 (Data Path) 作用 在用户态直接发起和接收数据,完全绕过内核和 CPU 拷贝。
核心操作
-
RDMA Write
1 2// 用户态:直接向对端内存写入数据(无需对方参与) ibv_post_send(qp, &wr); // wr 指定远程 MR 地址和数据- 左侧网卡通过 DMA 读取本地内存 → 封装报文 → 右侧网卡 DMA 写入目标内存。
-
RDMA Read
1 2// 用户态:直接从对端内存读取数据 ibv_post_send(qp, &rdma_read_wr);- 左侧网卡向右侧发起读取请求 → 右侧网卡 DMA 读取内存 → 返回数据到左侧内存。
-
完成通知
- 传输完成后,网卡向 CQ 写入事件 → 用户态轮询 CQ 或通过事件驱动获知结果。
✅ 核心优势:
- 零内核切换:数据传输无需陷入内核(ns 级延迟)
- 零 CPU 拷贝:网卡 DMA 直达用户内存
- 零协议栈开销:卸载 TCP/IP 协议处理到网卡(RoCE/InfiniBand)
小义提问5:还是看不懂?新发明概念DMA 可以操作用户态态内存吗?
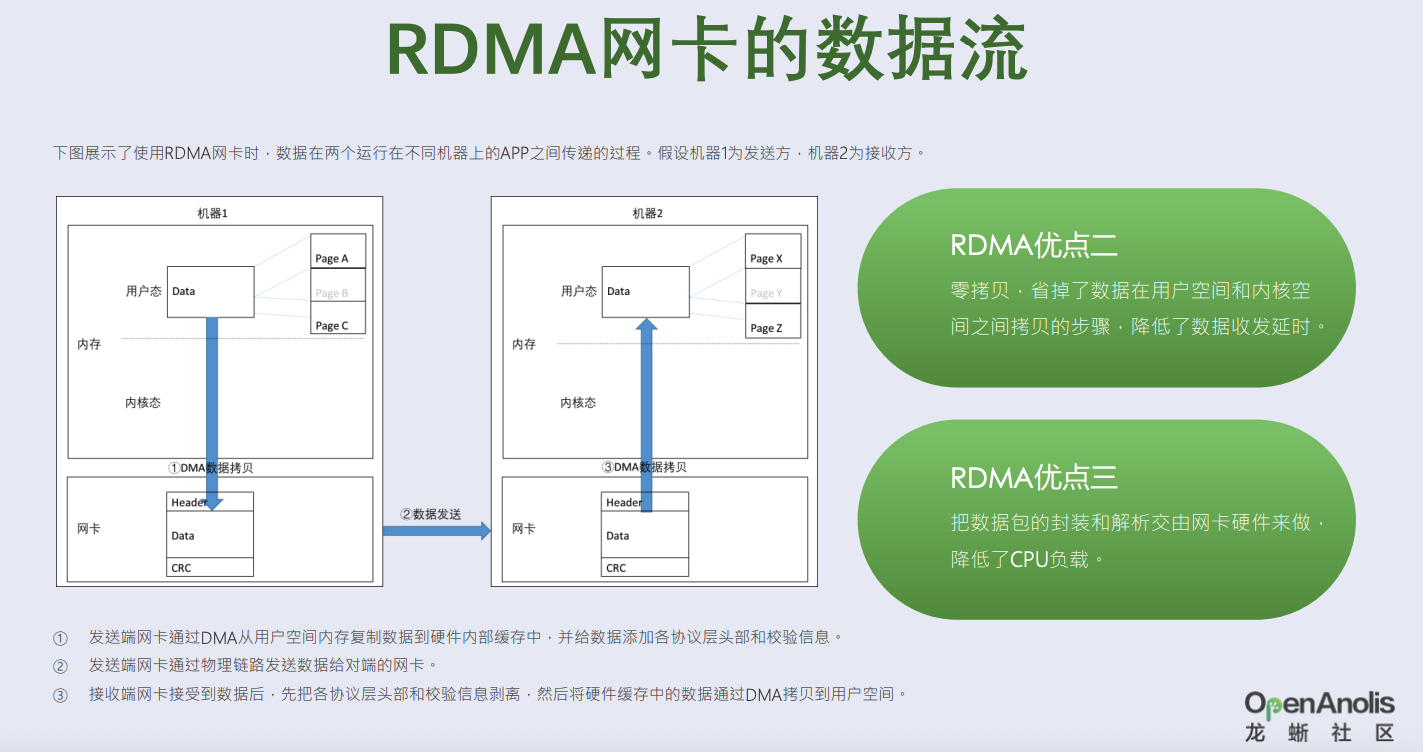
-
DMA的核心目标是解放CPU,
-
直接内存访问(Direct Memory Access, DMA)技术的核心是允许外部设备绕过 CPU 直接与内存进行数据读写,从而显著减轻 CPU 负担并提升数据传输效率。
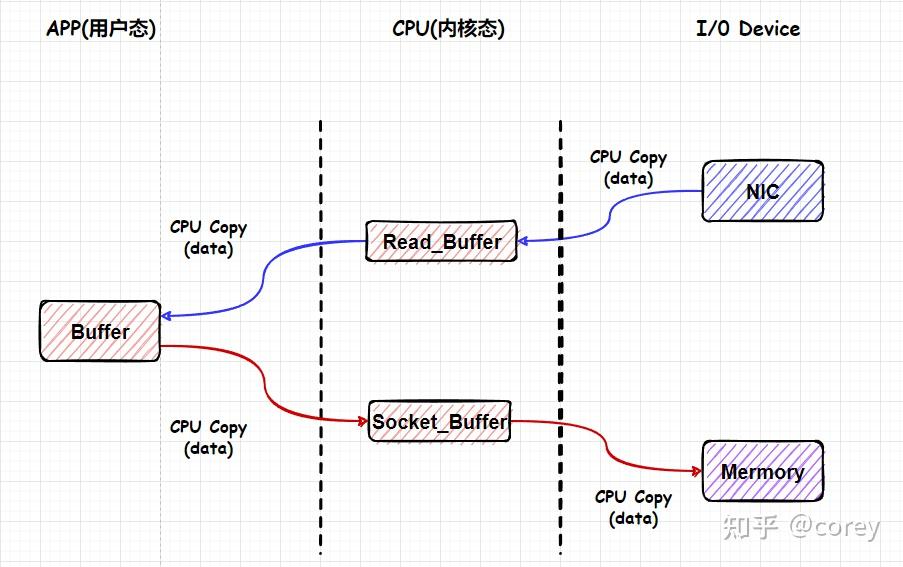
- 内存 当然可以是用户态的 在嵌入式驱动开发中,我们经常需要将大量数据从内存传输到设备,或者反过来。 如果你还在用 memcpy() + write() 来搬数据,那你的驱动性能可能只发挥了 30%。 要想高效,就得引入DMA(Direct Memory Access)机制 —— 让设备绕过CPU、直连内存,高速搬运。
|
|
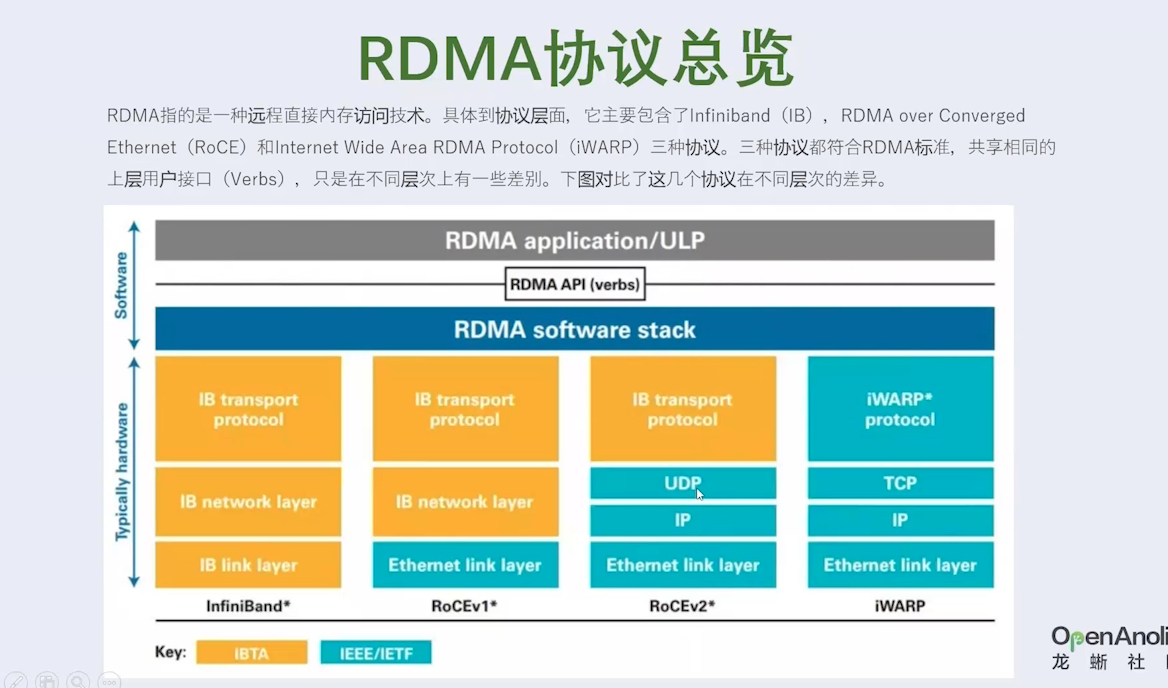
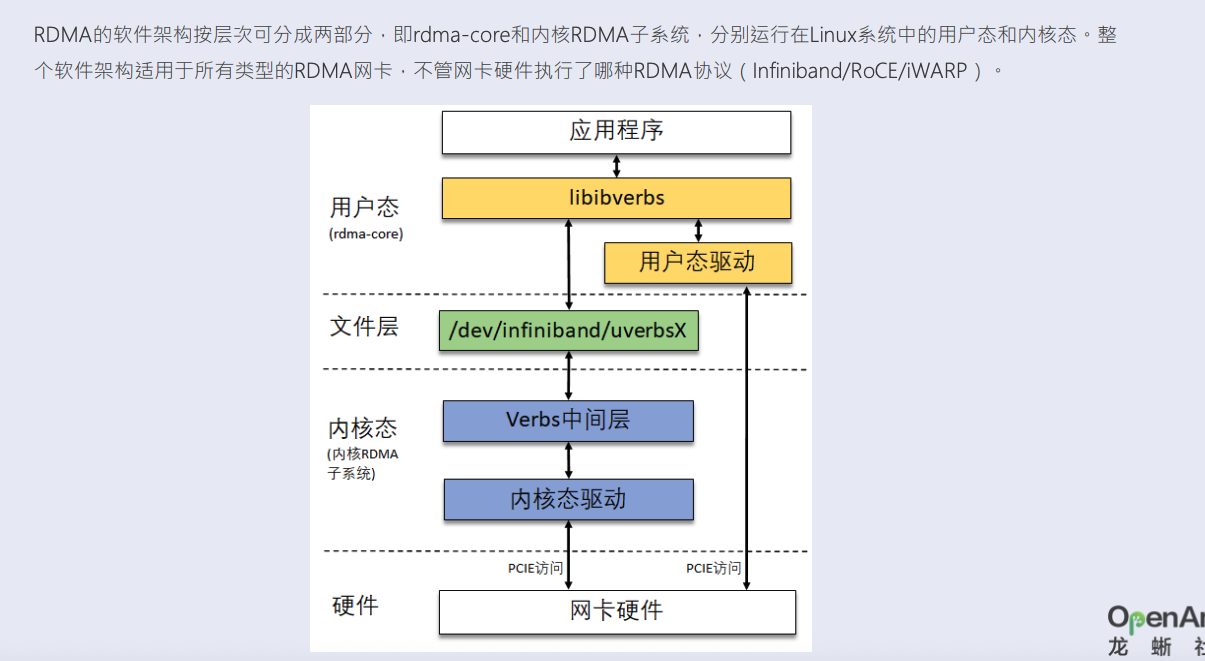
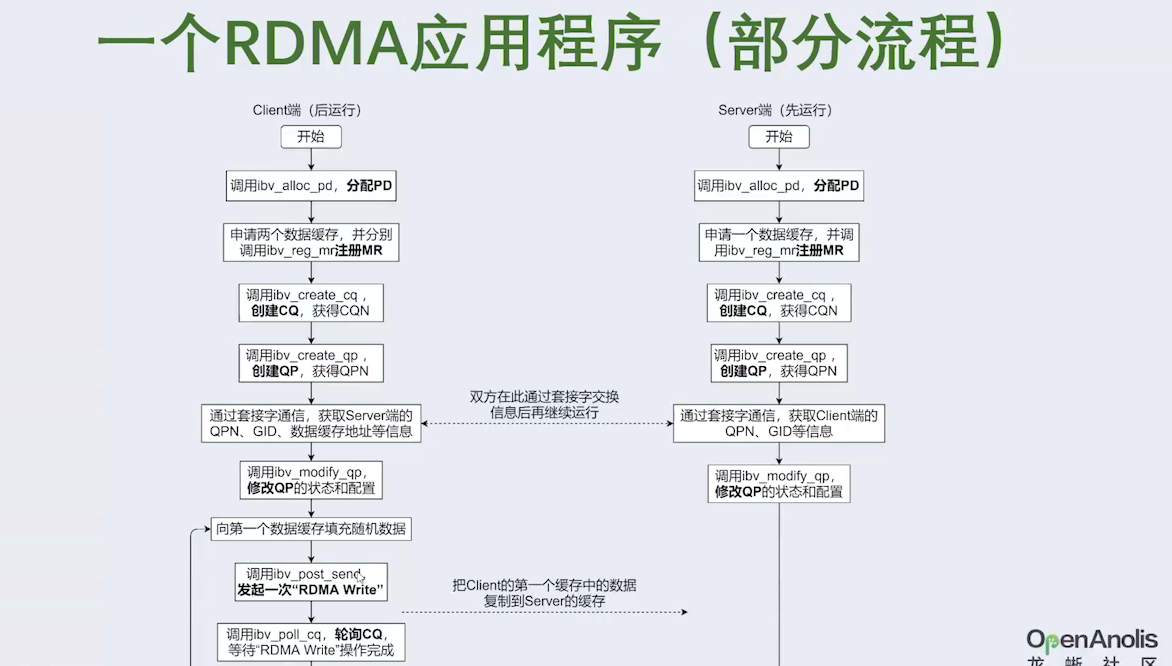
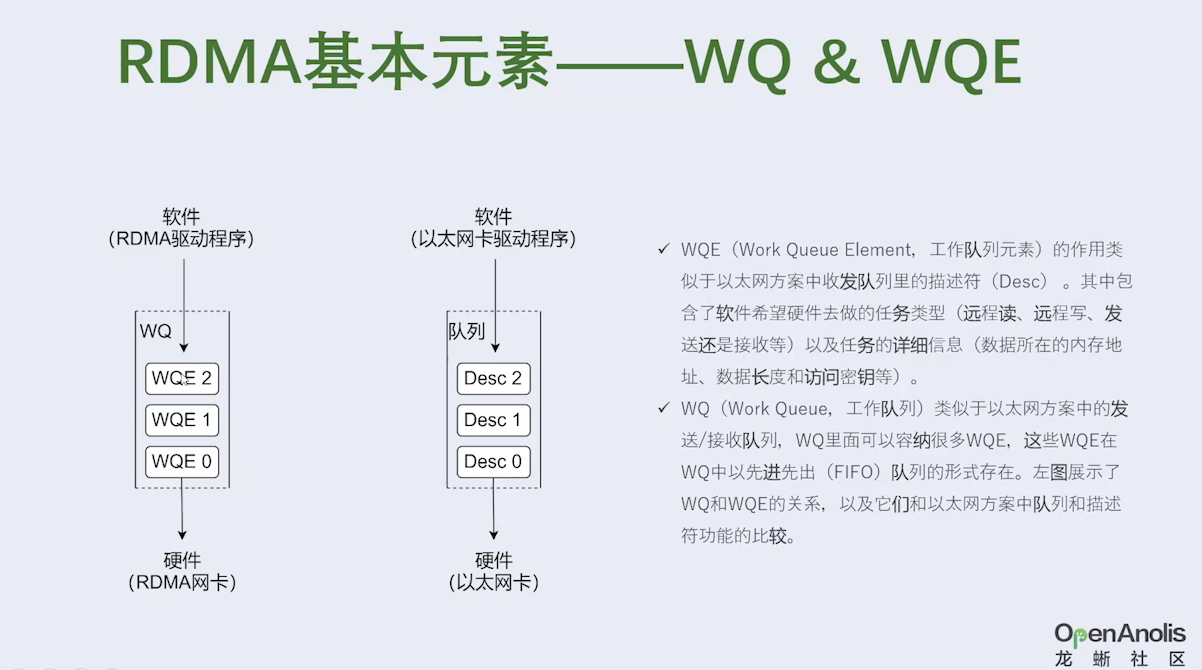
三、看 Linux高性能网络详解从 DPDK、RDMA 到 XDP(上)
序言 了解作者经历
今年是我毕业后进入通信行业的第 14 个年头。这些年来通信行业迅猛发展,新技术层出
不穷。从无线网络的 3G、4G、5G,到固定宽带的 DSL、GPON、EPON、NG-PON2,各种凝
聚了通信领域研发人员智慧和汗水的新技术不仅改善了人们的生活,也让我们国家在高科技
领域不断缩小和发达国家的差距,甚至在某些领域实现反超。身处时代发展的浪潮之中,每
每想起我自己的工作也为社会进步贡献了绵薄之力,世界各地都在运行着自己参与研发的设
备,就会心潮澎湃。
从毕业后进入一家小公司——上海爱吉开始,到后来工作过的中兴通讯和上海诺基亚贝
尔,我一直都在参与各种通信设备的研发工作,并且始终在嵌入式软件领域深耕细作。嵌入
式软件工程师,是一个对工作者拥有的计算机知识的广度和深度要求都比较高的岗位,所涉
及的领域从应用程序的需求,到操作系统的架构;从各种总线的配置,到对硬件行为的理解。
嵌入式软件从业人员需要与各种软件和硬件模块的负责人沟通协作。工作繁忙的同时,也得
到了大量锻炼个人技能的机会。
由于工作需要,我阅读了大量 Linux 操作系统以及网络相关的书籍和资料,在从大师们
的作品中汲取知识的同时,也惊叹于他们对系统细致入微的理解和深入浅出的讲解。因此一
直以来都非常希望能像他们一样,写出自己的作品。不过在写作本书之前,虽然平时颇有些
技术积累,也时常进行知识分享,但始终无法成体系,所以一直未能如愿。
2020 年 4 月以来,由于个人兴趣,加上朋友的建议,我开通了公众号“布鲁斯的读书圈”,
并时常在上面发表一些读书笔记和技术见解,慢慢地积累了一些彼此联系比较紧密的系列文
章。在进入浪潮公司后,由于部门领导的信任,我有幸负责了浪潮基于 FPGA 的 RDMA 网卡
的技术调研、方案设计以及驱动程序和测试工具的开发工作,由此进入高性能网卡研究领域。
其间也调查了其他一些高性能网络方案的原理和实现,比如 DPDK、XDP 等,并为一个开源
的基于 FPGA 的 100G 网卡方案 Corundum 编写了 DPDK 驱动程序。
本书以作者亲身的工作研究和总结为基础,从软硬件结合的视角详细论述了几种基于
Linux 系统的新兴高性能网络技术方案,主要涉及 DPDK、RDMA、XDP 等。本书图文并茂、
深入浅出,既有高屋建瓴的原理阐述与分析,也有抽丝剥茧的核心代码讲解,还有细致入微
的实战操作技巧和数据结果,体现了作者对驱动技术娴熟的驾驭能力,是一本十分精彩的、
贴合 Linux 驱动开发工程师学习路线的参考指导书。
第一章节:计算机网络概述
- 以太网是目前应用最普遍的局域网技术。(机房)
- 协议栈 计算机网络体系结构的具体的软件实现
- 封装和解析
- 最大传输单元
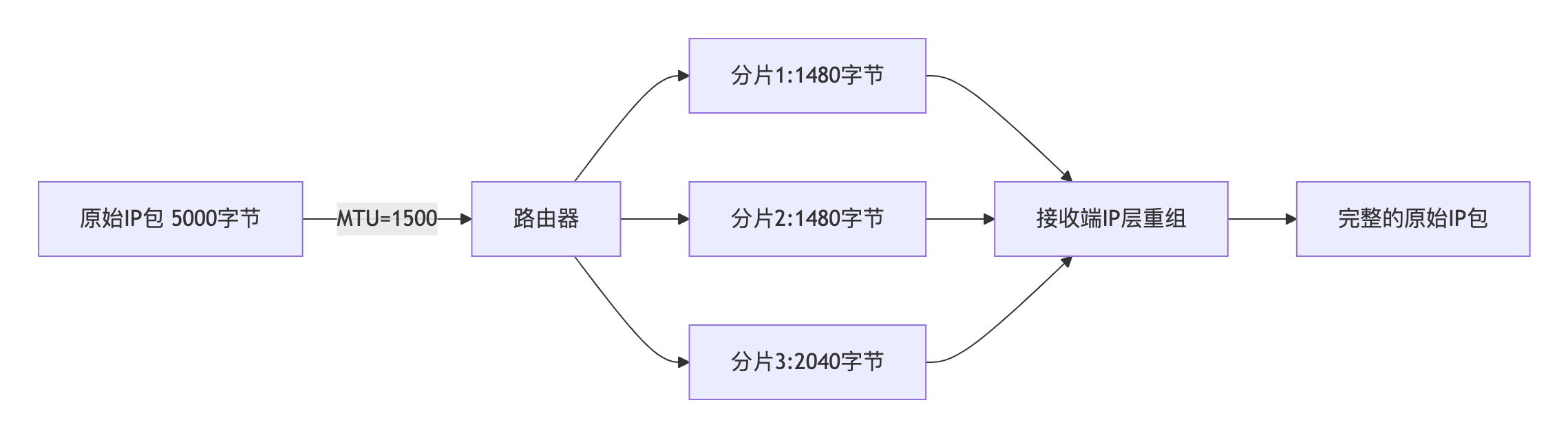
最大传输单元(maximum transmission unit,MTU)是指数据链接层上能通过的最大负载
的大小(以字节为单位)。标准以太网的 MTU 是 1500 字节。
- 分片
如果 IP 层有数据包要发送,而数据包的长度超过了 MTU,IP 层就要对数据包进行分片
(fragmentation)操作,使每一片的长度都小于或等于 MTU。我们假设要传输一个 UDP 数据
包,以太网的 MTU 为 1500 字节,一般 IP 报头为 20 字节,UDP 报头为 8 字节,数据的净荷
(payload)部分预留是 1500−20−8=1472 字节。如果数据部分大于 1472 字节,就会出现分片
现象。
- 交换机 与路由器区别?
- 交换机是一种多端口的网络桥接器(network bridge),工作在数据链路层,即 OSI 体系结构的第二层
- 路由器
路由器是一种网络设备,提供路由与转发两种重要机制。路由器可以决定数据包由源端
到目的端所经过的路径(即主机到主机的传输路径),这个过程称为路由;在路由器内部,
路由器还可以将输入端的数据包转发至适当的输出端,这个过程称为转发。 路由器工作在 OSI
体系结构的第三层,即网络层。
小义提问1:分片和粘包什么关系?
| 度 | 分片 (Fragmentation) | 粘包 (Packet Merging) |
|---|---|---|
| 发生层级 | 网络层(IP协议) | 传输层(TCP协议) |
| 触发原因 | 数据包长度 > 路径 MTU(最大传输单元) | TCP 的流式传输特性 + Nagle 算法优化 |
| 责任方 | 路由器或发送端主机 | TCP 协议栈(发送/接收缓冲区管理) |
| 数据单位 | IP 数据包 (Packet) | 应用层消息 (Message) |
| 重组位置 | 接收端网络层重组 | 接收端应用层解析 |
| 是否必要特性 | 是(IP协议核心功能) | 是(TCP协议设计结果,非缺陷) |
| 解决协议 | IP 分片字段 (DF/MF/Offset) | 应用层协议定义边界(如 Length-Header) |
| 典型场景 | 跨广域网传输(MTU 不一致) | 短时间高频小包发送(如RPC请求) |
- 分片丢失导致整个包作废(不支持部分送达)

分片(Fragmentation)和粘包(Packet Merging)是网络数据传输中两个不同层级、不同原因的现象,但它们共同指向数据重组问题。以下是深度对比解析:
- 网卡作为需要高速处理数据的设备,一般是通过 PCIe 总线和 CPU 相连,大多数网卡安装在普通家用计算机、小型工作站以及消费级电子产品上,这些应用场景
对速率的要求不高,一般情况下使用 1 个 1Gbit/s 及以下速率的网卡即可满足需求
- Mellanox MCX4121A-XCAT 统接口为 PCIe 3.0(8.0GT/s)×8。支持普
通以太网和 RoCE(RDMA over Converged Ethernet)功能。
📊 核心区别表
| 维度 | 分片 (Fragmentation) | 粘包 (Packet Merging) |
|---|---|---|
| 发生层级 | 网络层(IP协议) | 传输层(TCP协议) |
| 触发原因 | 数据包长度 > 路径 MTU(最大传输单元) | TCP 的流式传输特性 + Nagle 算法优化 |
| 责任方 | 路由器或发送端主机 | TCP 协议栈(发送/接收缓冲区管理) |
| 数据单位 | IP 数据包 (Packet) | 应用层消息 (Message) |
| 重组位置 | 接收端网络层重组 | 接收端应用层解析 |
| 是否必要特性 | 是(IP协议核心功能) | 是(TCP协议设计结果,非缺陷) |
| 解决协议 | IP 分片字段 (DF/MF/Offset) | 应用层协议定义边界(如 Length-Header) |
| 典型场景 | 跨广域网传输(MTU 不一致) | 短时间高频小包发送(如RPC请求) |
| 问内存的情况。 |
非统一内存访问(non-uniform memory access,NUMA)技术的出现就是为了克服 SMP
的上述缺点。NUMA 提供分离的存储器(内存)给处理器,大幅降低当多个处理器核访问同
一个存储器时因等待产生的性能损失
⚠️ 常见误区澄清
误区1:“TCP粘包是协议缺陷”
✅ 真相:粘包是 TCP流式传输特性 的自然结果,不是错误,而是通过应用层协议设计解决的问题。
误区2:“分片和粘包会同时发生”
✅ 真相:
- 分片在TCP之下发生,对应用透明
- 粘包在TCP之上发生,需应用处理 → 二者层次隔离,无直接关联
误区3:“UDP既不分片也不粘包”
✅ 修正:
-
UDP 支持IP分片(DF标志为0时)
-
UDP 没有粘包(但应用需处理丢包和乱序)
## 第二章 硬件
小义提问:什么南北桥,与零拷贝什么关系?
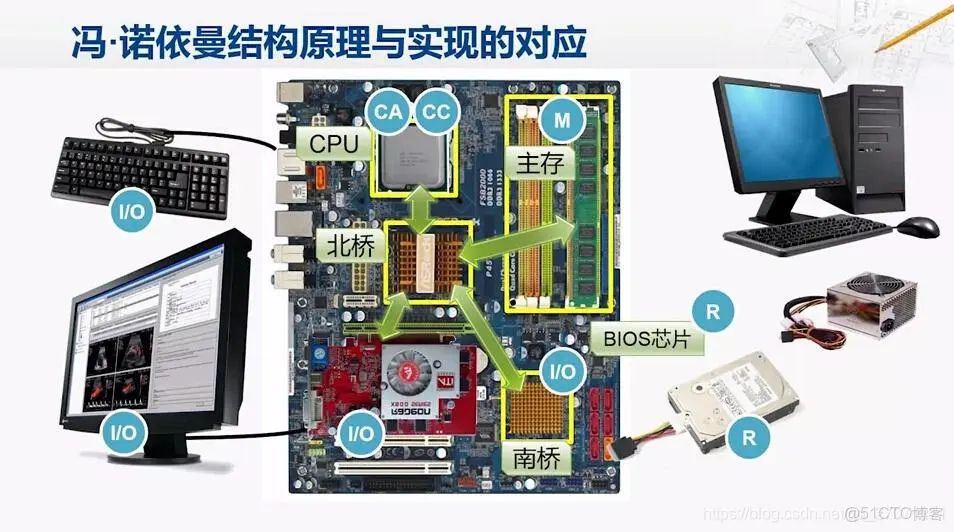
-
南北桥:代表中心化控制的I/O架构(南桥集权、北桥协管),适合低带宽时代;
-
RDMA:代表去中心化的硬件直连架构(网卡与内存直接对话),契合高性能计算需求
第三章:Linux 操作系统
- 如果说硬件是计算机系统的骨骼,那么软件就是计算机系统的灵魂
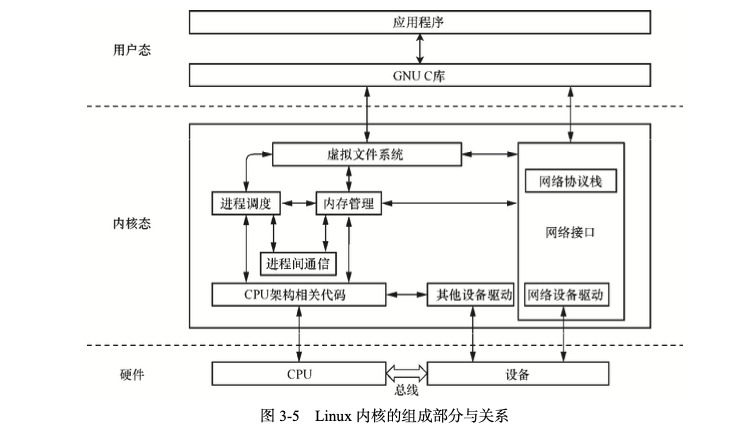
- 中断
- DMA 直接存储器访问(direct memory access, DMA)意为外设对内存的读写过程可以不用 CPU
参与而直接进行。
CPU 的最主要的工作是计算和控制,而不是进行数据复制,数据复制的工作白白浪费了
CPU 的计算能力,也减弱了它对全局的控制力。为了让 CPU 投入更有意义的工作中,人们设
计了 DMA 机制,比如总线上挂一个 DMA 控制器(现在一般网卡内部就自带这个功能),专
门用来读写内存。有了 DMA 控制器以后,当网卡想要从内存中复制数据时,除了一些必要
的控制命令,整个数据复制过程都是由 DMA 控制器完成的
CPU 除了关注一下这个过程的开始和结束,其他时间可以
做别的事情
最动人的作品,为自己而写,刚刚好打动别人
我在寻找一位积极上进的小伙伴,
一起参与神奇早起 30 天改变人生计划,做一个伟大产品取悦自己,不妨试试
1️⃣关注公众号:后端开发成长指南(回复"面经"获取)获取过去我全部面试录音和面试复盘

2️⃣ 感兴趣的读者可以通过公众号获取老王的联系方式。
加入我的技术交流群Offer 来碗里 (回复“面经”获取),一起抱团取暖
本群目标是:
抬头看天:走暗路、耕瘦田、进窄门、见微光
- 不要给自己这样假设:别人完成就等着自己完成了,大家都在一个集团,一个公司,分工不同,不,这个懒惰表现,这个逃避问题表现。
- 别人不这么假设,至少本月绩效上不会写成自己的,至少晋升不是你,裁员淘汰就是你。
- 目标:在跨越最后一道坎,拿百万年薪,进大厂。
低头走路:一次专注做好一个小事
- 不扫一屋 何以扫天下。
- 让自己早睡,早起,锻炼身体,刷牙保持个人卫生,多喝水 ,表达清楚 基本事情做好。