Ceph分布式锁的设计哲学与工程实践

文章目录
坚持思考,就会很酷。
大家好,这是进入大厂面试准备 第2篇文章,
”走暗路、耕瘦田、进窄门、见微光” 告诉我 面试关键就 项目 这个才是最考察基本功的地方。
- 知识地图:数据一致性—分布式锁
阅读本文你获得如何收益
✅ 在存储领域,分布式锁解决什么问题?
- 分布式扮演协调者角色,协调客户端并发写入,协调多副本数据同步,甚至故障后恢复。
- 支持 多读,多写,互斥三个等场景
✅ 分布式锁 怎么实现的?
- 锁机制 基于状态机设计的,内部能自我驱动改变,业务无需过多干预。
- 每个状态实现融入Ceph原有业务流程中。很难单独剥离出来。
- 锁本身设计确实十分简洁,锁类型 ,锁状态,锁类型不支持相互转换,锁状态可以相互转换,通过锁评估完成自动转换。 ✅ 具体怎么实现的?
- 预告:锁状态变化变成元数据,持久化到存储层,后面重点存研究BlueStore存储引起
- 预告:锁融入每个文件操作 :mkdir ,open 过程中 后面重点存研究IO流程 。
一、这个技术出现的背景、初衷和要达到什么样的目标或是要解决什么样的问题
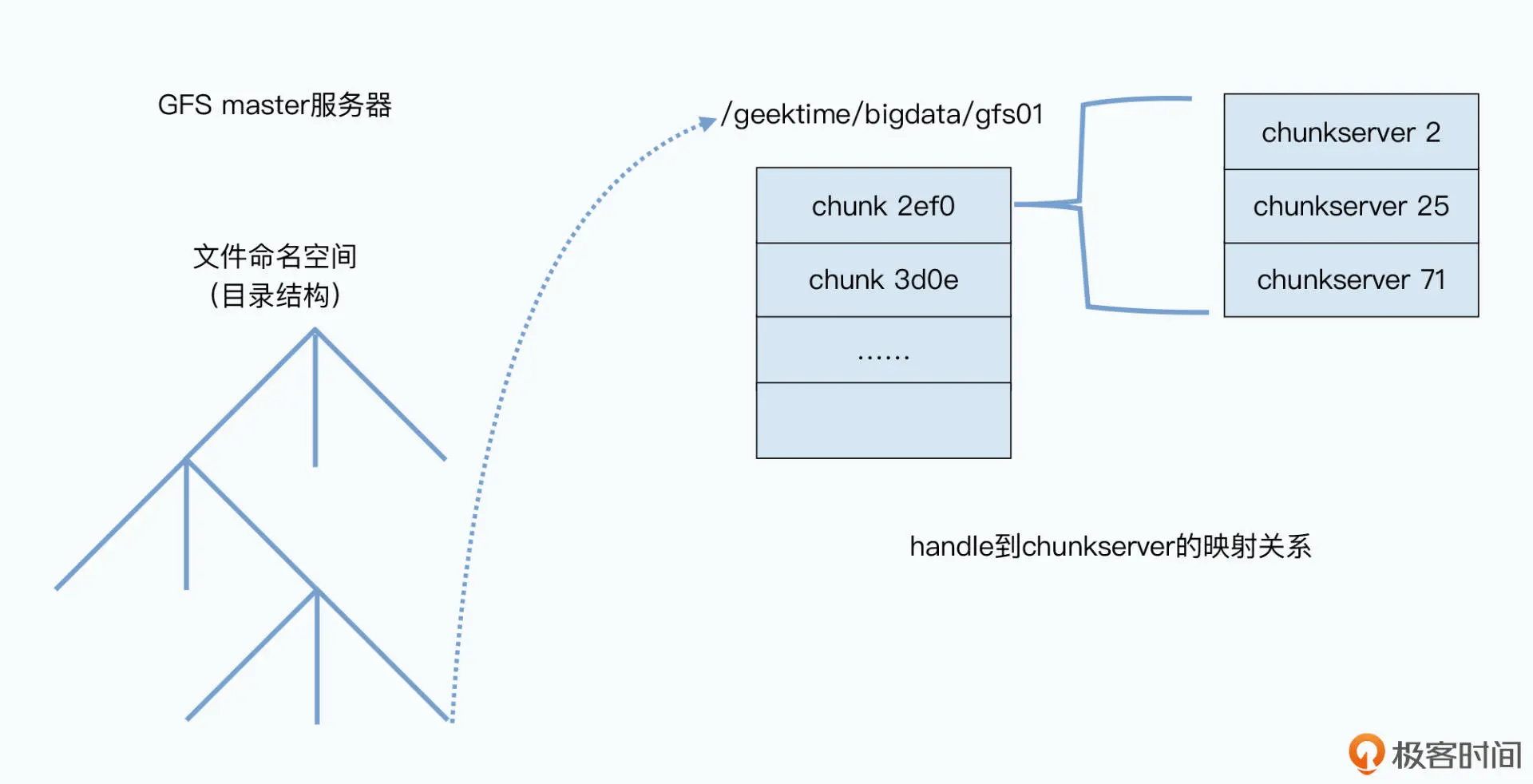
1.1 Ceph 解决横向扩展问题,单节点MDS读写平均1千QPS,扩展128节点读写在10 万次/秒。
在传统分布式文件系统(GFS)中,元数据管理集集中存储,一旦元数据服务器故障也会导致整个文件系统不可用。
画外音:为什么采用单Master存储
- GPFS 用来存储大文件,大文件数量有限,能将这个文件系统元数据加载到内容,单Master没毛病,正好正面了单Master设计是可行的
- GFS 直接使用了 Linux 服务上的普通文件作为基础存储层,并且选择了最简单的单 Master 设计。单 Master 让 GFS 的架构变得非常简单,通过对数据进行Checkpoints等也做到秒级切换。 (怎么做到的,加载数据不消耗时间吗?)
- 文件元数据数据结构3部分
- 目录树:例如 /data/geektime/bigdata/gfs01
- 文件被拆分成了哪几个数据快 chunk(64M)
- 数据快chunk 实际被存储在了哪些 chunkserver(存储节点)
- Ceph集群的推荐规模为10个存储节,GFS 规模上千个,
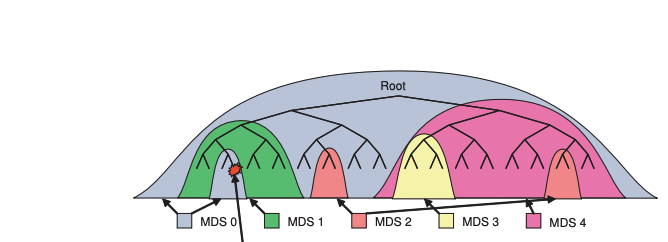
CephFS 的设计初衷就是要打破这一限制,通过将元数据与数据路径分离,
让客户端直接通过 CRUSH 算法访问 OSD 存储,
而由独立的 MDS 集群专注于元数据管理,
来源:Ceph: A Scalable, High-Performance Distributed File System
画外音:
- 如图2:元数据MDS只存储目录树,不维护 文件与对象之间关系,客户端通过crush算法计算出来
- Ceph 项目起源 于 2003 年 Sage 就读博士期间的研究课题(Lustre 环境中的可扩展问题).
- 牺牲单节点性能,追求横向扩展能力(如 128 节点集群总吞吐超 10万 OPS,单节点1千OPS)。
- 专为海量元数据场景设计(如超算中心百万级文件创建)
极端场景验证
- 并发创建文件(writefiles):
128 MDS 集群在 2 秒内完成 6.4 万客户端并发创建文件,写性能未显著低于读,表明架构设计有效均衡了读写负载。
- 并发创建文件(writefiles):
1.2 横向扩展的后果:多客户端并发修改同一文件 怎么办?
在CephFS中,元数据(如文件/目录的权限、大小、路径结构等)由多个MDS节点共同管理。
以下场景会导致数据不一致或性能问题:
- 并发写冲突:多个客户端同时修改同一文件或目录(例如同时删除和重命名),也可能MDS内部相互访问。
- 缓存不一致:不同MDS节点或客户端缓存了同一元数据的副本,修改后未及时同步,如何主副本数据达到一致,如果 没有达成一致,该如如何访问。
- MDS故障恢复:某个MDS节点宕机后,如何恢复其未完成的元数据操作并保持一致性?
通过上面描述 你猜测到 分布式锁是这样一个锁
扮演功能
- 多个客户端直接有序访问
- 多个元数据直接 副本达成一致
- 故障后还能自动恢复
- 保持锁的特性
- 肯定不是互斥锁 这个只能单机。
画外音:
- 具体是什么实现的还不清楚,继续往下看。
- 一个锁 怎么扮演这么多功能复杂吗?
二、这个技术的优势和劣势分别是什么
2.1 分布式锁 优点
高度抽象,业务参与很少。
- 系统自动驱动
- 场景:锁状态机根据条件(如权限变更、副本同步、租约超时)自动调整锁状态。
MDS中锁状态自动评估和变更由以下因素综合驱动:
- 请求驱动:客户端请求如读、写、打开文件等操作会触发锁状态评估 Server::handle_client_readdir–>mds->locker->eval
- 定期评估:定期检查锁状态以优化性能和资源利用 Locker::tick()—->eval_scatter_gathers();
- 客户端能力(Caps)变化 Locker::handle_client_caps –>mark_updated_scatterlock
2.2 分布式锁缺点是什么
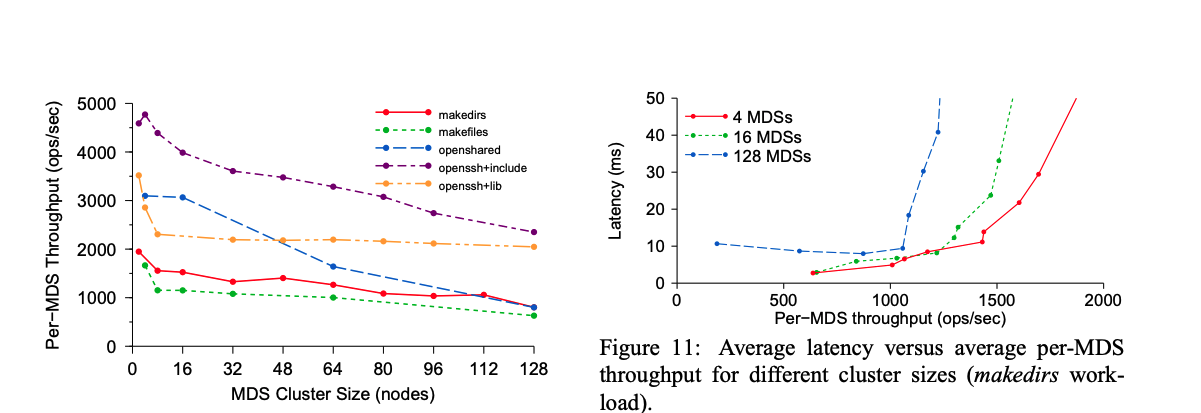
分布式锁运行在MDS服务中,看单个 MDS性能
画外音:
- 每个节点最大吞吐量为1-5千,这么弱我研究它干什么,CephFS Design Goals Infinitely scalable Avoid all Single Points Of Failure Self Managing
- 在CephFS目标就是无线扩展,避免单点。集群规模128节点 读写次/秒
- 单 MDS 测试:
- 读/写元数据操作均稳定在约 1000 次/秒(受单节点 CPU 限制)。
- 扩展性测试:
- 128 个 MDS 集群读吞吐量达 12.8 万次/秒,写吞吐量 10 万次/秒,验证近线性扩展能力。(一般企业规模部署没这么大)
扩展思考:为什么单节点这么慢,读写差不多?
- Ceph分布式锁阅读和理解很费劲,是不是一个缺点,太抽象了,高度抽象
三、这个技术适用的场景。任何技术都有其适用的场景,离开了这个场景
ceph 分布式锁机制通过结合
- <font color="#245bdb"RADOS 对象存储的锁持久化
- MDS 内部的多种锁类别(如 LocalLock、SimpleLock、ScatterLock)及 capability 缓存回收,在
- 多 MDS、跨网络、高并发访问场景下提供强一致性与高吞吐,同时支持动态子树分区的水平扩展和 HA 切换
这种设计特别适合包括高
-
大型并行计算 / 科研算力(HPC scratch)
在超算或科研集群里,成百上千个计算节点往往要并行创建、写入、读取同一个目录下的临时文件(scratch space)。CephFS 的分布式锁让这些节点可以安全地并发操作元数据,不会因冲突而卡住或错误。 -
容器化平台的共享持久卷
在 Kubernetes 等容器平台中,多个 Pod 可能要同时挂载同一份文件系统卷(CSI 卷)来读写日志、配置或共享数据。Ceph 分布式锁保证每个容器对目录树和文件的元数据访问都按序执行,避免写冲突和数据不一致。
四、技术的组成部分和关键点。
参考:
4.1 修改不同的元数据,采用不同的锁
目的:
不同的元数据(inode 和 dentry 中的)在不同情况下的行为不同,MDS 会使用不同类型的锁
锁类定义了处理分布式锁所需的相关锁类型的锁定行为。MDS 定义了4个锁类:
LocalLock 本地锁
Used for data that does not require distributed locking such as inode or dentry version information. Local locks are versioned locks. 定义:
-
用于不需要分布式锁定的数据,
-
本地锁是基于版本的锁。
特点:
- 仅需本地协调,适用于单个MDS(元数据服务器)内的元数据操作,避免跨节点通信开销
- 锁的资源 例如管理 inode(索引节点) 或 dentry(目录项) 的版本信息。 CEPH_LOCK_DVERSION - dentry版本锁 CEPH_LOCK_IVERSION - inode版本锁
日常比喻: 这就像你个人笔记本上的修改记录。
- 每次你修改笔记,你在修改记录页上记一笔
- 不需要告诉其他人你修改了记录
- 只在你的桌子上有效,不影响他人
simplelock:简单锁 共享读,排他写
SimpleLock - Used for data that requires shared read and mutually exclusive write. This lock class is also the base class for other lock classes and specifies most of the locking behaviour for implementing distributed locks.
定义:
- 用于需要共享读取和互斥写入的数据。
- 这种锁类也是其他锁类的基类,并为实现分布式锁指定了大部分锁定行为。
特点:
- 支持读共享/写互斥模式
- 支持跨MDS协作
- 影响范围
CEPH_LOCK_DN - 目录项锁 CEPH_LOCK_IAUTH - inode权限锁 CEPH_LOCK_ILINK - 硬链接锁 CEPH_LOCK_IXATTR - 扩展属性锁 CEPH_LOCK_ISNAP - 快照锁 CEPH_LOCK_IFLOCK - 文件锁管理锁 CEPH_LOCK_IPOLICY - 策略锁
举例: 当多个客户端读取同一目录内容,但只有一个客户端进行写入时:
- 多个客户端可获取目录的共享读锁
- 当需要创建/删除文件时,一个客户端需获取排他写锁
- 写操作时,所有读锁必须先释放
日常比喻:这像是办公室的会议室预订表。
- 只有一个人能修改预订记录(写)
- 多人可以同时查看预订表(读)
- 要修改时,必须确保没人正在更改
SimpleLock和sm_state_t的关系是:
-
定义与实现:sm_state_t定义锁行为,SimpleLock实现这些行为
-
数据与逻辑:sm_state_t包含状态数据,SimpleLock包含操作逻辑
-
配置与运行时:sm_state_t是静态配置,SimpleLock是运行时对象
-
通用与特化:不同锁类型使用不同的sm_state_t表,但共享SimpleLock代码
这种设计模式让Ceph能够用相同的代码基础实现多种不同行为的锁,同时保持代码清晰和行为一致。
ScatterLock:分散锁 共享读,共享写
ScatterLock - Used for data that requires shared read and shared write. Typical use is where an MDS can delegate some authority to other MDS replicas, e.g., replica MDSs can satisfy read capabilities for clients.
定义:
- 用于需要共享读取和共享写入的数据。
- 典型用途是MDS可以将部分权限委托给其他MDS副本, 例如,副本MDS可以满足客户端的读取能力请求。
特点:
- 支持读共享/写共享模式
- 允许权限委托给副本MDS
- 适用于可分散访问的数据
举例1 : 当多个客户端同时操作不同目录项时:
- MDS可以将部分目录的写权限委托给副本MDS
- 客户端A通过主MDS修改文件1的大小
- 同时,客户端B可以通过副本MDS修改文件2的大小
- 两个操作可以并行执行,无需互相等待
举例2
- 文件删除操作,一个文件目录分散到不同非MDS节点,MDS分别同时删除。 常比喻:
这像是管理多个部门的项目,每个部门可以独立更新自己负责的部分。
- 整体项目有一个主管理员
- 但各部门可以被授权管理自己的子项目
- 减少了向主管理员请示的次数 具体锁说明:
- INEST锁 - 控制目录统计信息(如文件数量)的更新
- IDFT锁 - 控制目录如何被分片和管理
code
ScatterLock是Ceph MDS中的一种特殊锁类型,允许数据的分散管理。它的核心特点是:
- 支持读写共享操作
- 允许将权限委派给其他MDS
- 适用于可分割的元数据(如目录统计信息)
class ScatterLock : public SimpleLock
ScatterLock应用示例:目录统计信息(INEST)
背景场景
假设有一个大型目录/data,包含上万个文件,由多个MDS和客户端共同访问:
-
MDS0是目录的权威节点(auth)
-
MDS1和MDS2是副本节点
-
多个客户端在不同子目录创建/删除文件
filelock:文件锁
定义:
- 文件锁是管理文件数据访问权限的专用锁,
- 控制客户端对文件内容的读取和写入操作。
它是一种更复杂的锁类型,结合了SimpleLock和ScatterLock的特性,专门处理文件I/O权限。
特点:
- 支持多级缓存模式
- 管理客户端读写权限
- 控制数据一致性和缓存行为
- 支持多种锁定状态以优化性能
|
|
4.2 无论何种类型的锁,都有一个state变量记录当前锁的状态。每个锁都有相关的状态机控制状态转移。
ScatterLock:分散锁 的状态
解决问题:多写
状态定义:(复杂跳过)
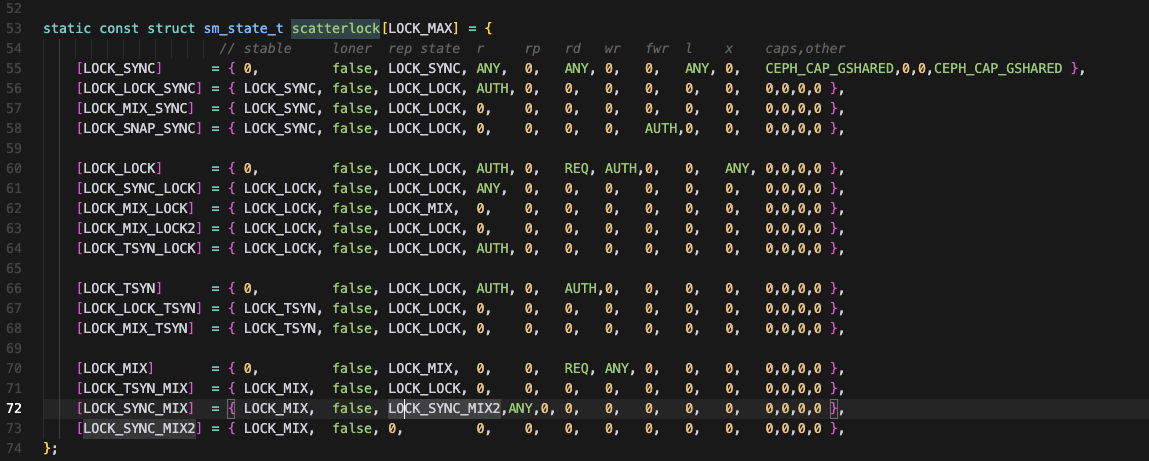
根据状态机可以确定:
- 下一步锁的状态(next_state)
- 其他副本的状态
- 允许谁可读(can_read)、谁可加读锁(can_rdlock)、谁可加写(can_wrlock)、谁可以加排他锁(can_xlock)等。这里的谁被抽象成为ANY、AUTH、XCL等。
- ANY指的任何拥有Object副本的MDS,
- AUTH(authority)指的是被授权Object的MDS,
- XCL指的是被授权Object的MDS或者排他执行的客户端。
- 对应的caps是什么,包括拥有Object副本的MDS的此时应该使用的caps(针对不同的角色也分为4种)
复杂程度而言,可以根据sm_state_t结构体里面定义的条数判
|
|
状态分析
SYNC:一种任意人都可读,可加读锁的状态;
LOCK:在无副本的情况下,可多写的状态;
MIX: 在有副本的情况下,需要多写的状态; 主本、副本都是MIX态; 锁从MIX迁移到其他状态时,会自动汇总副本inode上的数
五、技术的底层原理和关键实现
5.1 锁需要持久化吗?
Ceph 文件系统 ( CephFS ) 它构建于 Ceph 的分布式对象存储 RADOS 之上

锁状态机定义(sm_state_t)本身不需要持久化,它是代码中的静态结构。
但锁的当前状态需要持久化,这是通过以下机制实现的:
- MDS将当前的锁状态通过日志机制 或者元数据对象两种方式持久化
- 锁状态变更 → 日志记录(EUpdate) → 日志对象 → 定期写入元数据
- 编码方面持久化void CInode::encode_lock_state(int type, bufferlist& bl)
- 锁状态变更通过日志事务记录 EUpdate *le = new EUpdate(mdlog, “updated lock”);
- 日志记录最终会转化为元数据存储
- 元数据存储到RADOS
- 锁状态会作为inode/dentry的一部分存储到RADOS对象
CInode::store
-CInode::store 函数的主要目的是将当前的 inode(文件元数据)编码并写入到底层的 RADOS 对象存储中。
|
|
7 恢复机制
MDS重启或集群故障转移时,锁状态会从持久化存储恢复:
- handle_mds_map state change up:boot –> up:replay
- handle_mds_map state change up:replay –> up:reconnect
- handle_mds_map state change up:reconnect –> up:rejoin
- handle_mds_map state change up:rejoin –> up:active
5.2 为什么是自驱
锁类型与锁状态的区别
重要的是区分锁类型(不可变)和锁状态(可变):
- 锁类型:由类的继承关系确定,表示锁的功能和行为模式,不可转换
- LocalLock、SimpleLock、ScatterLock、FileLock
- 锁状态:锁在其生命周期中的当前状态,可以转换
- LOCK_SYNC、LOCK_EXCL、LOCK_MIX等
Ceph锁机制的自我调节特性
在Ceph中,锁状态转换具有自我驱动的特性,这是分布式系统中的一个关键设计。让我用简单的方式解释这个概念:
当说"锁机制依据各种条件自我驱动到合适的状态,无需业务主动干预"时,意思是:
-
自动状态优化:锁系统会根据当前系统状态和访问模式,自动调整锁的状态
-
透明于上层:上层业务代码不需要显式管理这些状态转换
-
智能适应:锁会根据使用情况"学习"并调整到最适合的状态
实际例子:文件锁(FileLock)自动调节
假设一个场景,文件先被单客户端写入,后来变成多客户端读取:
阶段1: 客户端A独占写入文件
- FileLock自动转为EXCL状态(独占) - 提供完整的写入权限
阶段2: 客户端A写完,多个客户端开始读取
- 系统检测到访问模式变化
- FileLock自动评估并转为SYNC状态(共享)
- 优化为多读取场景
整个过程中,业务层只请求了"我需要读"或"我需要写",而不需关心锁处于什么状态。
评估函数示例
看一个简化的file_eval函数,它负责评估文件锁状态:
|
|
这种设计的优势
-
降低复杂度:上层代码不需理解复杂的锁状态
-
自适应优化:系统根据实际使用模式自动优化
-
性能提升:锁状态总是趋向于最高效的配置
-
减少人为错误:避免手动状态管理的错误
)
案例 2:ScatterLock在Ceph中的真实应用:目录统计信息
问题背景
-
大型目录可能包含数百万文件
-
多个客户端在不同位置并发创建/删除文件
-
需要维护准确的目录统计信息(文件数、总大小等)
六、已有的实现和它之间的对比
| 特性 | CephFS 分布式锁 | Redis(Redlock) |
|---|---|---|
| 集成度 | 与 RADOS 对象存储深度耦合,锁信息作为对象属性由 MDS 内部 mds.locker 模块全权管理 |
依赖外部 Redis 实例,通过客户端执行原子命令(SET NX PX 等)实现,无需底层存储集成 |
| 锁粒度 | 细粒度:支持多种锁类型,包括目录项锁(SimpleLock)、目录统计锁(ScatterLock)、文件锁(FileLock)等 | 粗粒度:按单个 key 加锁,通常一个资源对应一个 Redis key;Redlock 通过在多数实例上加锁来实现互斥 |
| 故障模型 | 支持 active–standby(基于日志重放秒级接管)与 active–active(目录子树隔离故障影响范围最小)两种模式,依靠 RADOS 多副本保障一致性 | 基于租约(TTL)与多数派原则:客户端需在多数 Redis 实例上在租约时间内成功加锁,部分实例故障时仍能保证锁安全 |
| 性能(延迟) | 中等:每次加解锁需通过 MDS RPC 并写入 per-MDS 日志到 RADOS,读多写少时可依靠 capability 缓存显著降低延迟 | 极低:锁操作在内存中完成,单实例场景下通常只需一次网络往返,多实例 Redlock 也仅需少量命令 |
| 可扩展性 | 通过动态子树分区(Dynamic Subtree Partitioning)实现 MDS 水平线性扩展与元数据负载均衡 | 受限于 Redis 实例数量和分片拓扑,跨分片锁定需额外协调,大规模场景中扩展性有限 |
| 复杂度 | 高:涉及多种锁类型与状态机、cap 回收逻辑、MDS 与 RADOS 之间的日志同步与故障切换,运维和调优成本较大 | 低:实现逻辑简单,主要由客户端库负责,但需注意时钟漂移和网络抖动带来的租约安全问题 |
总结
- 高度抽象 ,把锁变成面向对象设计,抽象不同类型的锁
- 锁转换的触发机制,需要结合业务深入分析
- 锁状态变化随着文件indoe等信息进行 持久化
参考
-
【1】https://docs.ceph.com/en/reef/cephfs
-
【2】mkdir|mksnap流程源码分析|锁状态切换实例
-
【3】https://github.com/ceph/ceph/blob/main/doc/cephfs/mds-states.rst
-
【4】https://docs.ceph.com/en/latest/dev/mds_internals/locking/
如果您觉得阅读本文对您有帮助, 请点一下“点赞,转发” 按钮, 您的“点赞,转发” 将是我最大的写作动力!