庖丁解牛之LevelDB
 次阅读
次阅读
文章目录
【注意】最后更新于 February 8, 2022,文中内容可能已过时,请谨慎使用。
LevelDB
LevelDB是Google传奇工程师Jeff Dean和Sanjay Ghemawat开源的KV存储引擎
无论从设计还是代码上都可以用精致优雅来形容,非常值得细细品味。
一、这个技术出现的背景、初衷和要达到什么样的目标或是要解决什么样的问题
二、这个技术的优势和劣势分别是什么
三、这个技术适用的场景。任何技术都有其适用的场景,离开了这个场景
四、技术的组成部分和关键点。
五、技术的底层原理和关键实现
六、已有的实现和它之间的对比
| 产品 | 一致性 | 角色 | ||
|---|---|---|---|---|
| ZooKeeper | 过半 | leader,followers,Observer(只读节点) | ||
| Redis | conf | Master,Slave |
庖丁解LevelDB之概览 【todo任务执行中】
来呀:http://catkang.github.io/2017/01/07/leveldb-summary.html
接下来就将用几篇博客来由表及里的介绍LevelDB的设计和代码细节。
本文将从设计思路、整体结构、读写流程、压缩流程几个方面来进行介绍,从而能够对LevelDB有一个整体的感知。
设计思路
LevelDB的数据是存储在磁盘上的,采用LSM-Tree的结构实现。
LSM-Tree将磁盘的随机写转化为顺序写,从而大大提高了写速度。
为了做到这一点LSM-Tree的思路是将索引树结构拆成一大一小两颗树,较小的一个常驻内存,较大的一个持久化到磁盘,他们共同维护一个有序的key空间。
写入操作会首先操作内存中的树,随着内存中树的不断变大,会触发与磁盘中树的归并操作,而归并操作本身仅有顺序写。如下图所示:
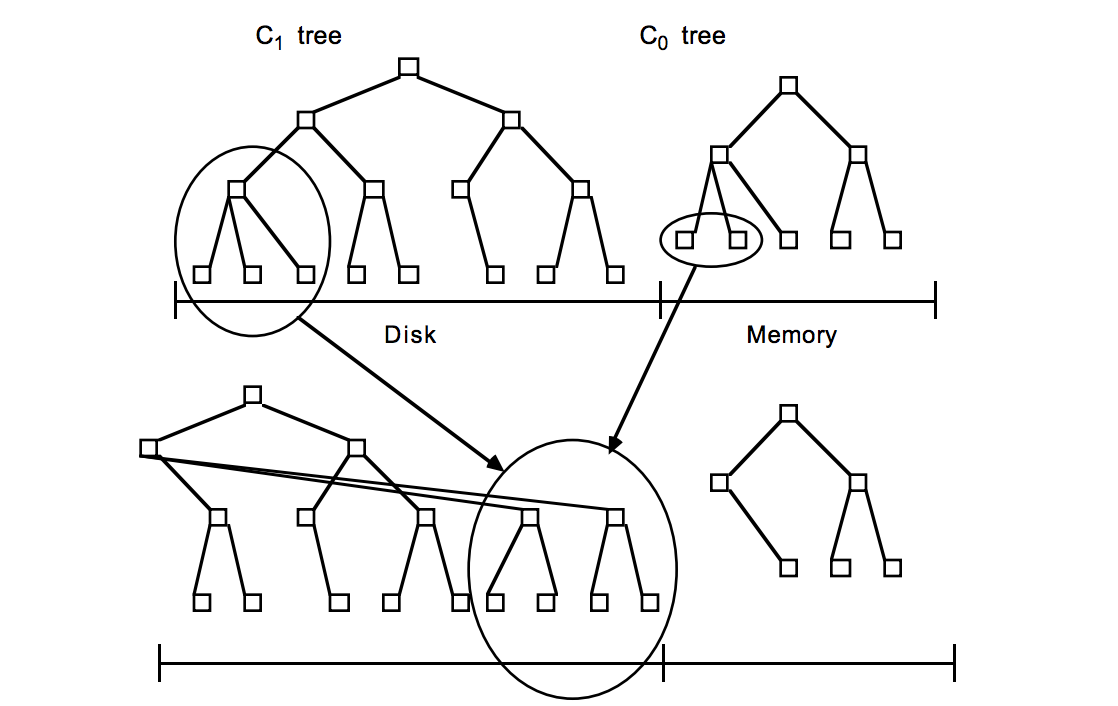
随着数据的不断写入,磁盘中的树会不断膨胀,为了避免每次参与归并操作的数据量过大,以及优化读操作的考虑,LevelDB将磁盘中的数据又拆分成多层,每一层的数据达到一定容量后会触发向下一层的归并操作,每一层的数据量比其上一层成倍增长。这也就是LevelDB的名称来源。
LSM-Tree示意图来源于论文:The Log-Structured Merge-Tree
Source Code:https://github.com/google/leveldb
看完了上面文字,我还是不懂 怎么办?不要说自己理解差 笨,拿出更多时间吧
|
|
从看文档开始:https://github.com/google/leveldb/blob/master/doc/index.md
- 如何读写操作的!!!
Leveldb源码解读(三)
https://hardcore.feishu.cn/docs/doccn4w8clvork96K3dqQnJRh9g
https://www.bilibili.com/video/BV1vP4y1Y7Ey?p=2
问:逻辑block 怎么用一个类表示呢?