FQA_Linux

文章目录
【注意】最后更新于 November 16, 2019,文中内容可能已过时,请谨慎使用。
修改日期 2019-11-29
当你的才华撑不起你的野心时,就应该静下心来好好学习。
知识卡
书籍
一、进程
问题1.1 execve 函数使用过程中注意事项
Linux中fork子进程后再exec新程序时文件描述符的问题?
小王回答:
假如进程A 400w,文件描述符,
for进程B后,进程占用400w相同描述符。
执行exec后,默认 对代码段,数据段,堆栈进行替换。因此 进程B 的占用内存空间 没有了,
但是类似指针替换一样,内核依然记录,该文件被进程B占用,但是进程B ,已经替换成进程C了,
会出现一些黑洞情况。需要执行
主进程在申请资源时候 采用 close-on-exec机制。
|
|
问1 :进程间通信方式
进程间通信 2个情况
第一个是 exchange data 传递数据 (跨主机 TPC,不跨主机 IPC)
第二个是 synchronize 同步(内核,非内核的) 信号灯
最常用的socket(TCP/UDP)
信号
一、 问:有哪2个信号不能被忽略?
答:
- 什么是信号:
软中断信号(signal,又简称为信号)用来通知进程发生了异步事件
信号是进程间通信机制中唯一的异步通信机制,一个进程不必通过任何操作来等待信号的到达
Signals are software interrupts
信号的异步性意味着,应用程序不用等待事件的发生,当信号发生时应用程序自动陷入到对应的信号处理函数中
|
|
操作系统不会为了处理一个信号而把当前正在运行的进程挂起,因为这样的话资源消耗太大了,如果不是紧急信号,是不会立即处理的,操作系统多选择在内核态切换回用户态的时候处理信号。
因为进程有可能在睡眠的时候收到信号,操作系统肯定不愿意切换当前正在运行的进程,于是就得把信号储存在进程唯一的 PCB(task_struct) 当中。
理解信号异步机制的关键是信号的响应时机,我们对一个进程发送一个信号以后,其实并没有硬中断发生,只是简单把信号挂载到目标进程的信号 pending 队列上去,信号真正得到执行的时机是进程执行完异常/中断返回到用户态的时刻。
让信号看起来是一个异步中断的关键就是,正常的用户进程是会频繁的在用户态和内核态之间切换的(这种切换包括:系统调用、缺页异常、系统中断…),所以信号能很快的能得到执行。
但这也带来了一点问题,内核进程是不响应信号的,除非它刻意的去查询。
所以通常情况下我们无法通过kill命令去杀死一个内核进程。

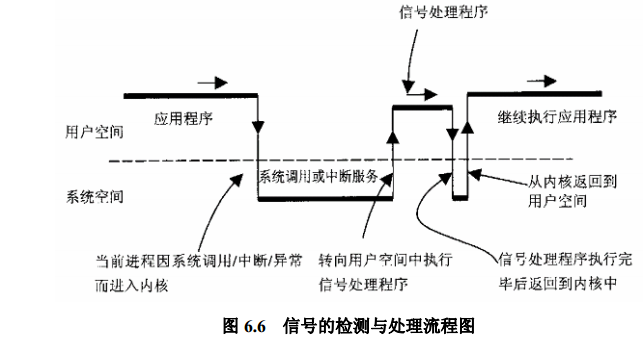
- 被忽略 进程对信号的三种响应方式之一
-
忽略信号
-
不采取任何操作、有两个信号不能被忽略:SIGKILL和SIGSTOP。
Ignore the signal. This works for most signals, but two signals can never be ignored: SIGKILL and SIGSTOP.
-
-
捕获并处理信号
- 内核中断正在执行的代码,转去执行先前注册过的处理程序。
-
执行默认操作
- 默认操作通常是终止进程,这取决于被发送的信号。
其中
SIGKILL和SIGSTOP信号不能被捕获、阻塞或忽略。 还是没有理解 不能被捕获
kill -s SIGKILL
这个强大和危险的命令迫使进程在运行时突然终止,
进程在结束后不能自我清理。危害是导致系统资源无法正常释放,一般不推荐使用,除非其他办法都无效。
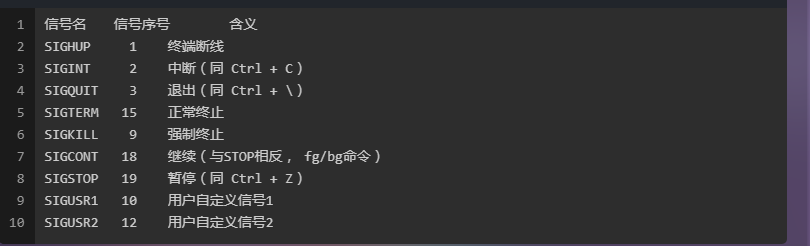
信号种类
Linux 3.2.0 each support 31 different signals
signal.h
| SIGHUP | 1 | 终端挂起或控制进程终止。当用户退出Shell时,由该进程启动的所有进程都会收到这个信号,默认动作为终止进程。 |
|---|---|---|
不可重入函数
|
|
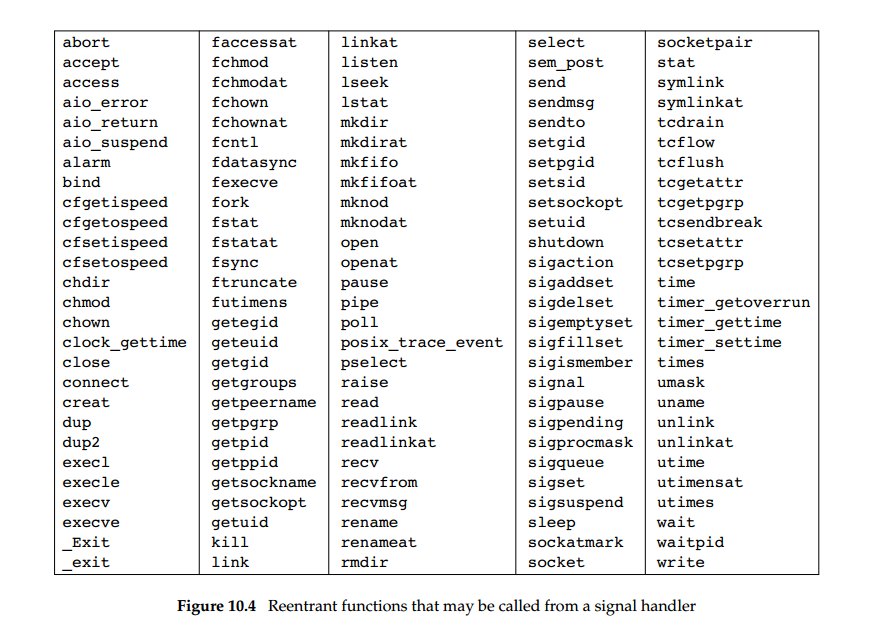
使用可重入函数进行更安全的信号处理(回顾历史)
https://www.ibm.com/developerworks/cn/linux/l-reent.html
在早期的编程中,不可重入性对程序员并不构成威胁;
函数不会有并发访问,也没有中断。
在很多较老的 C 语言实现中,函数被认为是在单线程进程的环境中运行。
可重入函数:
- 不为连续的调用持有静态数据。
- 不返回指向静态数据的指针;所有数据都由函数的调用者提供。
- 使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据。
- 绝不调用任何不可重入函数
出于以下任意某个原因,其余函数是不可重入的:
- 它们调用了
malloc或free。 - 众所周知它们使用了静态数据结构体。
- 它们是标准 I/O 程序库的一部分
https://www.ibm.com/developerworks/cn/linux/l-reent.html
现在,在信号处理器中您并不知道信号被捕获时进程正在执行什么内容。如果当进程正在使用 malloc 在它的堆上分配额外的内存时,您通过信号处理器调用 malloc,那会怎样?或者,调用了正在处理全局数据结构的某个函数,而 在信号处理器中又调用了同一个函数。如果是调用 malloc,则进程会 被严重破坏,因为 malloc 通常会为所有它所分配的区域维持一个链表,而它又 可能正在修改那个链表。
线程安全和可重入函数 阅读 20分钟
当使用流(stream)进行 I/O 时会出现类似的情况。
假定信号处理器使用 fprintf 打印一条消息,而当信号发出时程序正在使用同一个流进行 fprintf 调用。
信号处理器的消息和程序的数据都会被破坏,因为两个调用操作了同一数据结构:流本身。
经验 3
在大部分系统中,malloc 和 free 都不是可重入的, 因为它们使用静态数据结构来记录哪些内存块是空闲的。实际上,任何分配或释放内存的库函数都是不可重入的。这也包括分配空间存储结果的函数。
Linux 中可重入这个概念一般只有在 signal 的场景下有意义,叫 async-signal-safe。 很多线程安全的函数都是不可重入的,例如 malloc。 可重入的函数一般也是线程安全的,虽然据说有反例,但我没见过。 Posix中大多数函数都是线程安全的,但只有少数是 async-signal-safe。 见《Linux多线程服务端编程》第4.2节和第4.10节。
异步可重入函数与线程安全函数等价吗? 30分钟
https://www.zhihu.com/question/21526405
printf()等系统库函数是如何实现的?
https://www.zhihu.com/question/28749911
库函数/系统调用
同步


区别是什么?
Linux用户级进程跟内核线程(进程)有什么差别?
区别: 1)内核级线程是OS内核可感知的,而用户级线程是OS内核不可感知的。 2)用户级线程的创建、撤消和调度不需要OS内核的支持,是在语言(如Java)这一级处理的;而内核支持线程的创建、撤消和调度都需OS内核提供支持,而且与进程的创建、撤消和调度大体是相同的。
3)用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
4)在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
5)用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
为什么要区分用户态和内核态?
在CPU的所有指令中,有些指令是非常危险的,如果错用,将导致系统崩溃,比如清内存、设置时钟等。 如果所有的程序都能使用这些指令,那么系统死机的概率将大大增加。 所以,CPU将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通应用程序只能使用那些不会造成灾难的指令。 Intel的CPU将特权等级分为4个级别:Ring0~Ring3 Linux使用Ring3级别运行用户态,Ring0作为内核态。 Linux的内核是一个有机整体,每个用户进程运行时都好像有一份内核的拷贝。每当用户进程使用系统调用时,都自动地将运行模式从用户级转为内核级(成为陷入内核),此时,进程在内核的地址空间中运行
从用户空间到内核空间有以下触发手段?
1)系统调用:用户进程通过系统调用申请使用操作系统提供的服务程序来完成工作,比如read()、fork()等。系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现的。
2)中断:当外围设备完成用户请求的操作后,会向CPU发送中断信号。这时CPU会暂停执行下一条指令(用户态)转而执行与该中断信号对应的中断处理程序(内核态)
3)异常:当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
liunx
- 线程就是一段代码 和普通的代码没有区别
Threads in Linux are nothing but a flow of execution of the process. A process containing multiple execution flows is known as multi-threaded process.
For a non multi-threaded process there is only execution flow that is the main execution flow and hence it is also known as single threaded process. For Linux kernel , there is no concept of thread. Each thread is viewed by kernel as a separate process but these processes are somewhat different from other normal processes. I will explain the difference in following paragraphs.
Threads are often mixed with the term Light Weight Processes or LWPs. The reason dates back to those times when Linux supported threads at user level only. This means that even a multi-threaded application was viewed by kernel as a single process only. This posed big challenges for the library that managed these user level threads because it had to take care of cases that a thread execution did not hinder if any other thread issued a blocking call
- LWP 是内核层面 ,thread是用户层面 不是同一个事情
Threads are often mixed with the term Light Weight Processes or LWPs. The reason dates back to those times when Linux supported threads at user level only. This means that even a multi-threaded application was viewed by kernel as a single process only. This posed big challenges for the library that managed these user level threads because it had to take care of cases that a thread execution did not hinder if any other thread issued a blocking call
So, effectively we can say that threads and light weight processes are same. It’s just that thread is a term that is used at user level while light weight process is a term used at kernel level.



用户空间线程模型(M : 1)
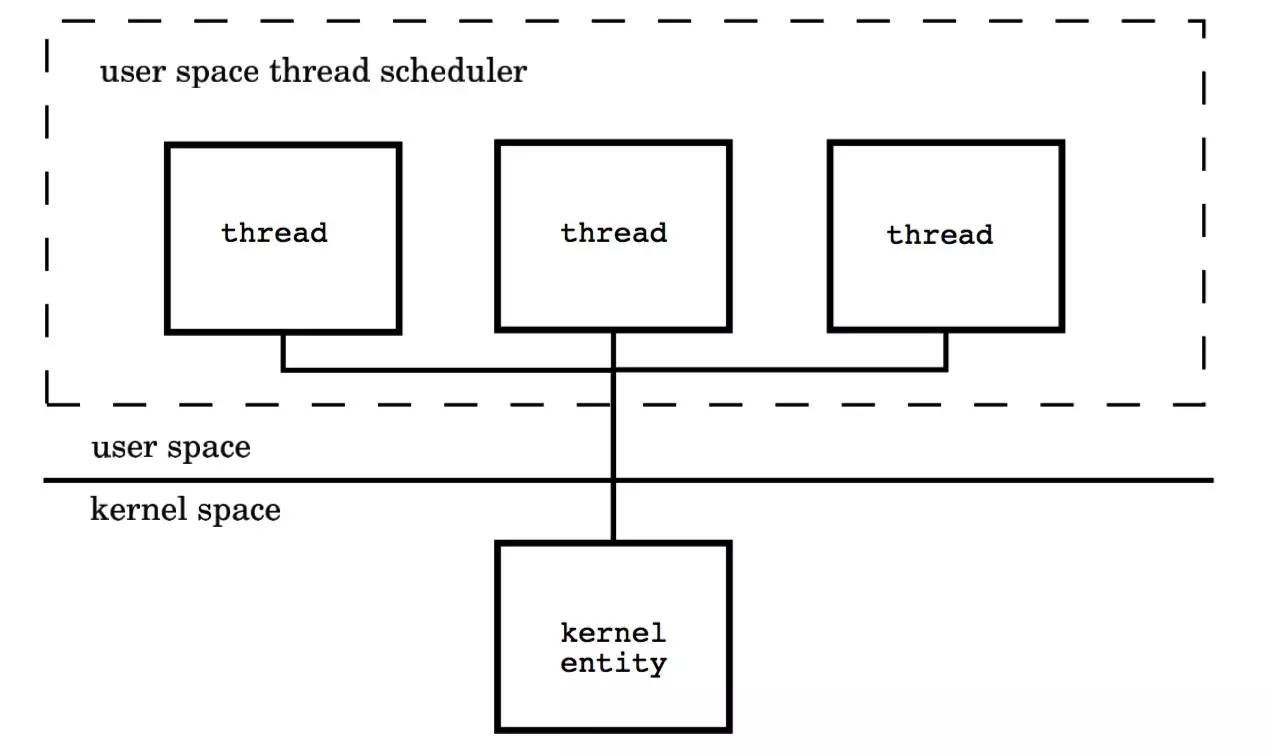
每个线程由内核调度器独立的调度,所以如果一个线程阻塞则不影响其他的线程。然而,创建、终止和同步线程都会发生在内核地址空间,这可能会带来较大的性能问题
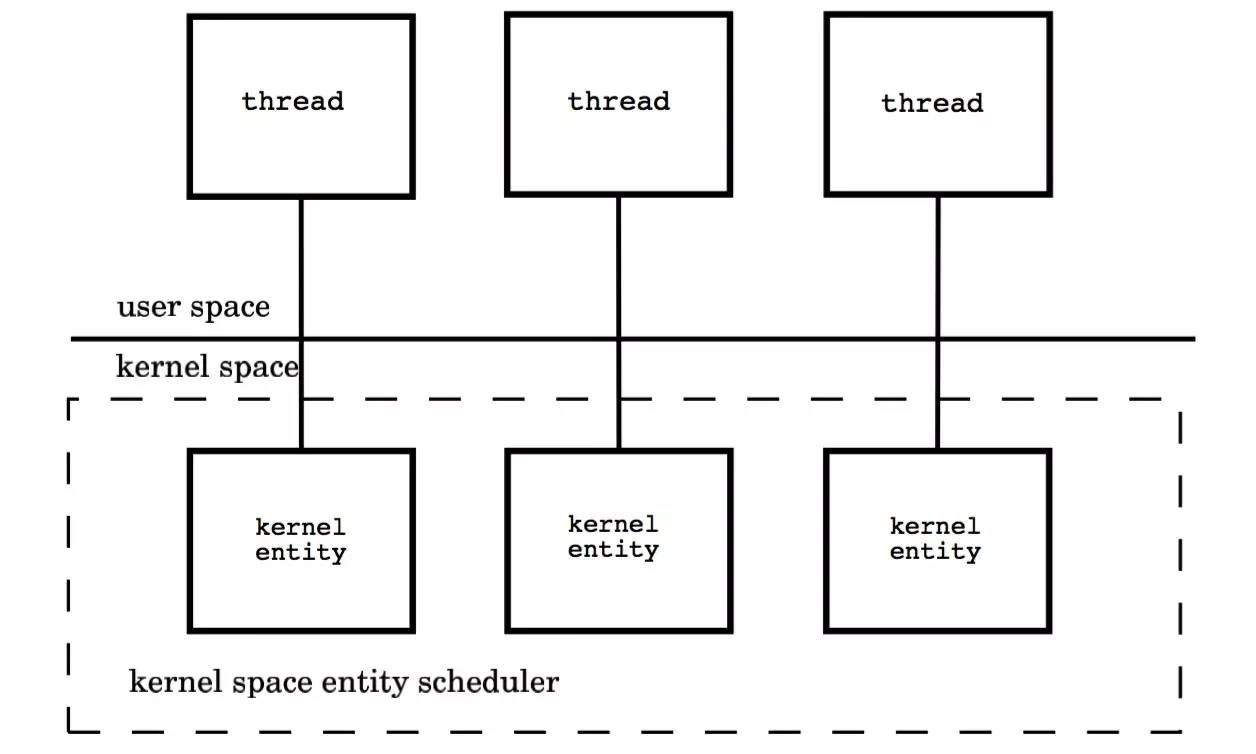
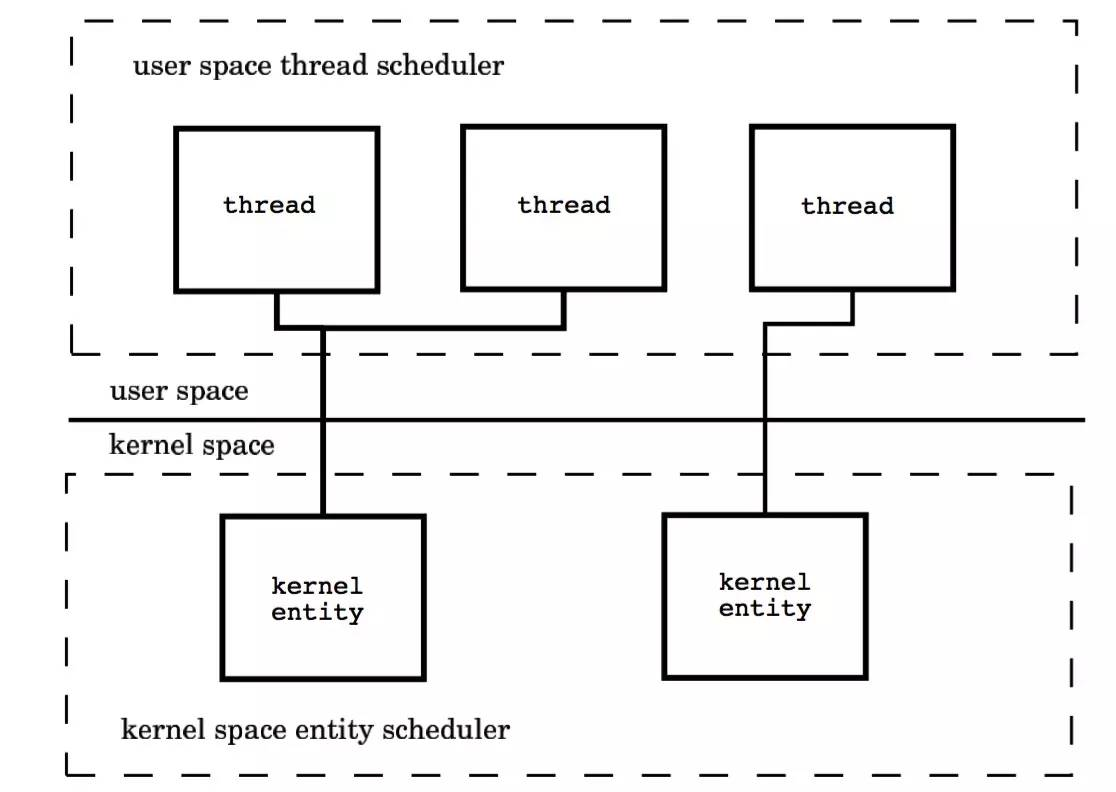
本质上是多个线程被绑定到了多个内核线程上,这使得大部分的线程上下文切换都发生在用户空间,而多个内核线程又可以充分利用处理器资源,模型图如下: [不明白] [不明白] [不明白]
jvm 线程实现相关研究,发现 java 线程的问题其实是基于 C++ 和 pthread 线程库的问题
https://crazyfzw.github.io/2018/06/19/thred-model/
Java的线程模型
一句话总结:Java 的线程是映射到操作系统的原生线程之上的。
JVM 没有限定 Java 线程需要使用哪种线程模型来实现, JVM 只是封装了底层操作系统的差异,而不同的操作系统可能使用不同的线程模型,例如 Linux 和 windows 可能使用了一对一模型,solaris 和 unix 某些版本可能使用多对多模型。所以一谈到 Java 语言的多线程模型,需要针对具体 JVM 实现。
https://stackoverflow.com/questions/10392800/how-does-pthread-implemented-in-linux-kernel-3-2
1 .内核级线程:切换由内核控制,当线程进行切换的时候,由用户态转化为内核态。切换完毕要从内核态返回用户态;可以很好的利用smp,即利用多核cpu。windows线程就是这样的。
- 用户级线程内核的切换由用户态程序自己控制内核切换,不需要内核干涉,少了进出内核态的消耗,但不能很好的利用多核Cpu,目前Linux pthread大体是这么做的。
clone
https://linux.die.net/man/2/clone
Windows
- 线程
在 Windows 中,线程是基本的执行单位。在进程的上下文中会有一个或多个线程在运行。
调度代码在内核中实现。
【线程是基本调度单位是window下概念不是liunx下概念呀】
Linux 内核使用的是进程模型,而不是线程模型。
Linux 内核提供了一个轻量级进程框架来创建线程;实际的线程在用户 空间中实现。
在 Linux 中有多种可用的线程库(LinuxThreads、NGPT、NPTL 等等)。本文中的资料基于 LinuxThreads 库
进程
Windows 中和 Linux 中的基本执行单位是不同的。在 Windows 中,线程是基本执行单位,进程是一个容纳线程的容器。
在Mac、Windows NT等采用微内核结构的操作系统中,进程的功能发生了变化:它只是资源分配的单位,而不再是调度运行的单位。在微内核系统中,真正调度运行的基本单位是线程。因此,实现并发功能的单位是线程。
https://zh.wikipedia.org/wiki/IOCP
IOCP特别适合C/S模式网络服务器端模型。因为,让每一个socket有一个线程负责同步(阻塞)数据处理,one-thread-per-client的缺点是:一是如果连入的客户多了,就需要同样多的线程;二是不同的socket的数据处理都要线程切换的代价。
线程的出现,是为了分离进程的两个功能:资源分配和系统调度。让更细粒度、更轻量的线程来承担调度,减轻调度带来的开销。
但线程还是不够轻量,因为调度是在内核空间进行的,每次线程切换都需要陷入内核,这个开销还是不可忽视的。协程则是把调度逻辑在用户空间里实现,通过自己(编译器运行时系统/程序员)模拟控制权的交接,来达到更加细粒度的控制。
线程的出现,是为了分离进程的两个功能:资源分配和系统调度。
线程的出现,是为了分离进程的两个功能:资源分配和系统调度。
线程的出现,是为了分离进程的两个功能:资源分配和系统调度。
原理[编辑]
通常的办法是,线程池中的工作线程的数量与CPU内核数量相同,以此来最小化线程切换代价。
一个IOCP对象,在操作系统中可关联着多个Socket和(或)文件控制端。
IOCP对象内部有一个先进先出(FIFO)队列,用于存放IOCP所关联的输入输出端的服务请求完成消息。
请求输入输出服务的进程不接收IO服务完成通知,而是检查IOCP的消息队列以确定IO请求的状态。 (线程池中的)多个线程负责从IOCP消息队列中取走完成通知并执行数据处理;
如果队列中没有消息,那么线程阻塞挂起在该队列。这些线程从而实现了负载均衡。
那如何优化呢?
NIO(Non-blocking I/O)
单Reactor单线程
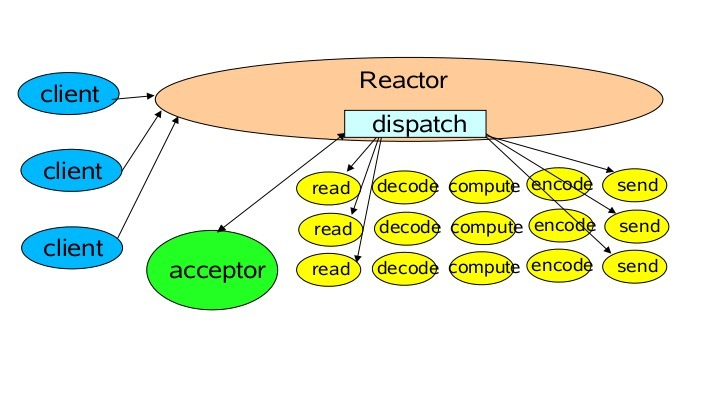
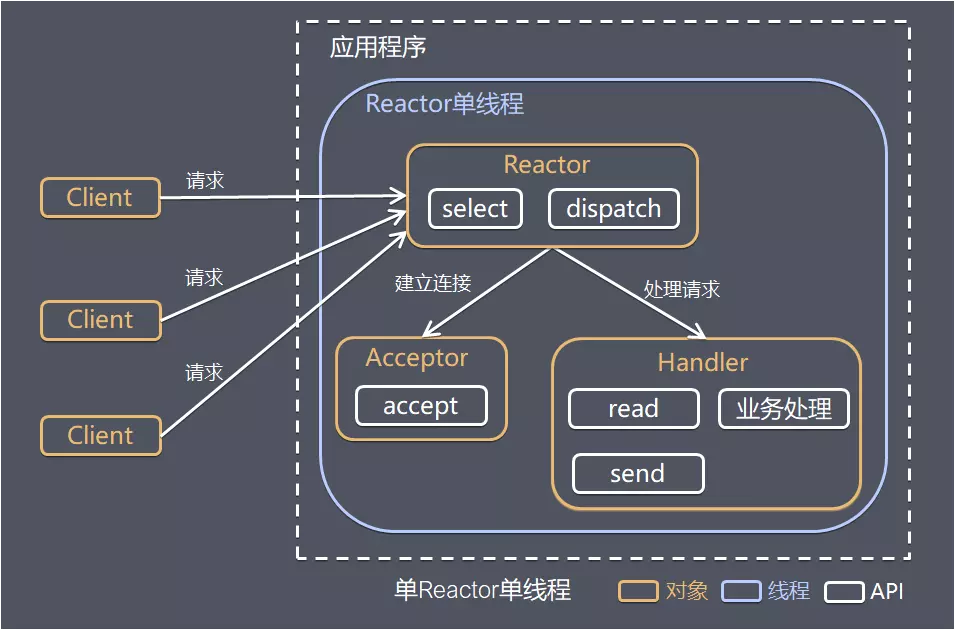
但由于是一个线程,对多核 CPU 利用率不高,一旦有大量的客户端连接上来性能必然下降,甚至会有大量请求无法响应。
最坏的情况是一旦这个线程哪里没有处理好进入了死循环那整个服务都将不可用!
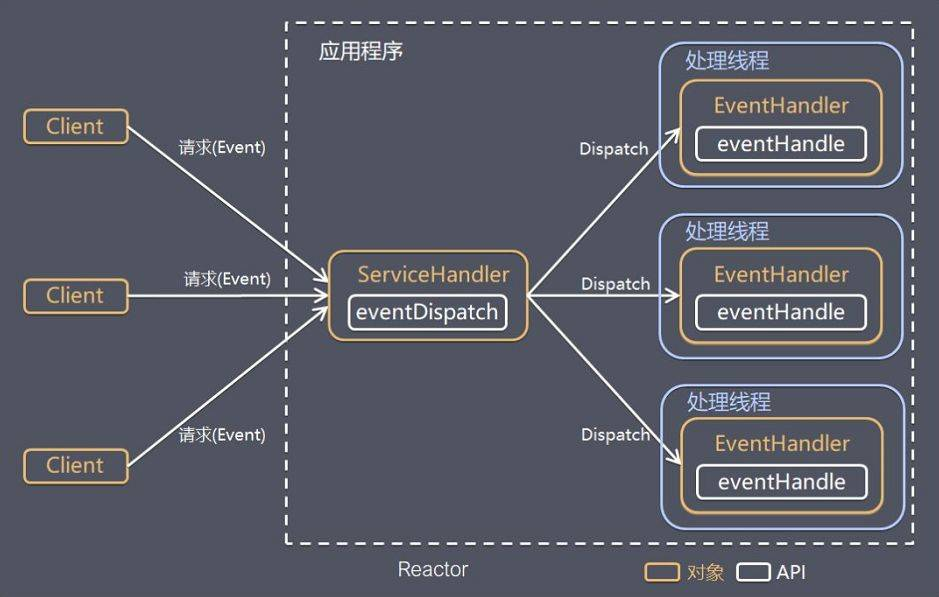
单Reactor多线程
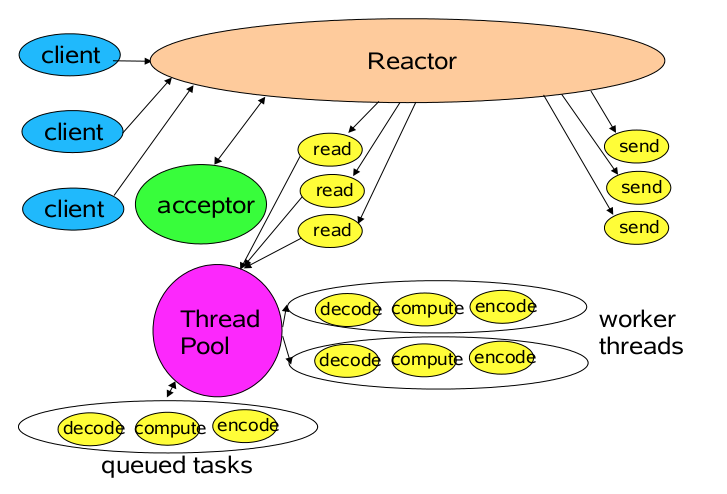
- 事件分发器,单线程选择就绪的事件。
- I/O处理器,包括connect、read、write等,这种纯CPU操作,一般开启CPU核心个线程就可以。
- 业务线程,在处理完I/O后
方案说明
- Reactor对象通过select监控客户端请求事件,收到事件后通过dispatch进行分发
- 如果是建立连接请求事件,则由Acceptor通过accept处理连接请求,然后创建一个Handler对象处理连接完成后的续各种事件
- 如果不是建立连接事件,则Reactor会分发调用连接对应的Handler来响应
- Handler只负责响应事件,不做具体业务处理,通过read读取数据后,会分发给后面的Worker线程池进行业务处理
- Worker线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给Handler进行处理
- Handler收到响应结果后通过send将响应结果返回给client
优点 可以充分利用多核CPU的处理能力
缺点
- 多线程数据共享和访问比较复杂
- Reactor承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈
主从Reactor多线程
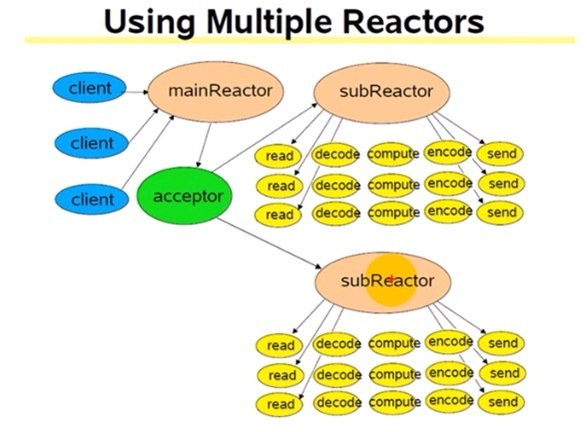
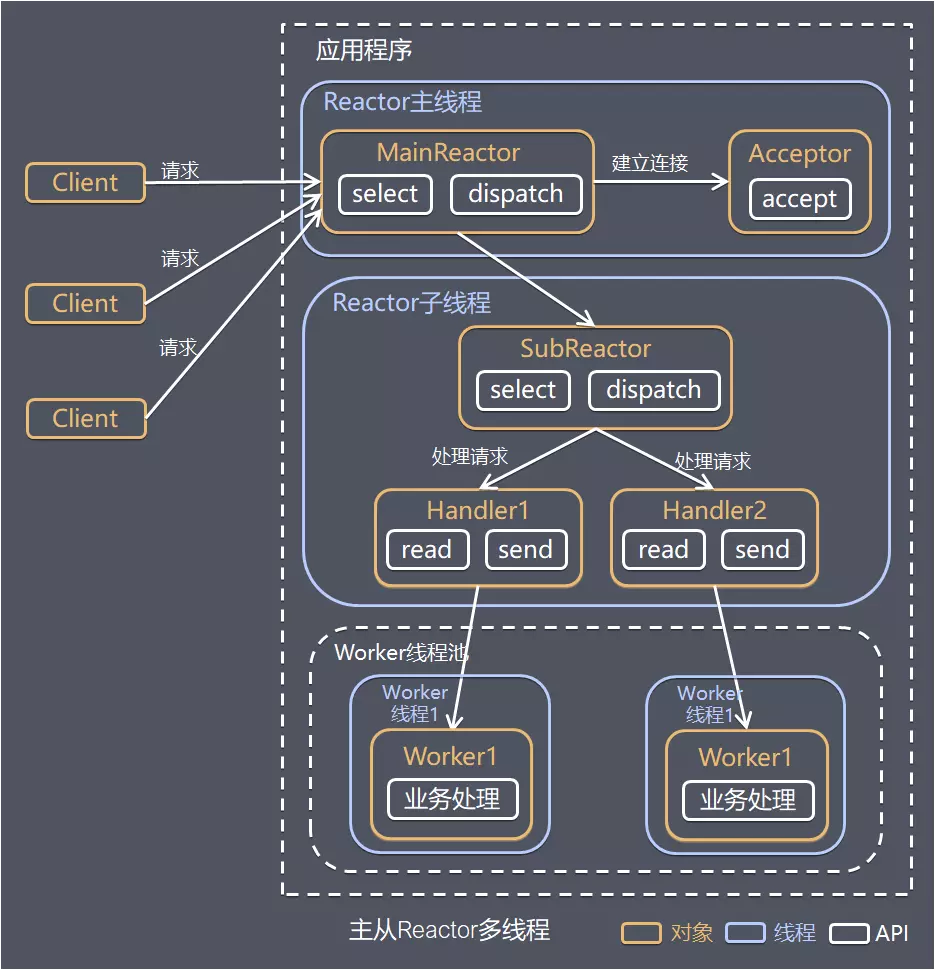
方案说明
- Reactor主线程MainReactor对象通过select监控建立连接事件,收到事件后通过Acceptor接收,处理建立连接事件
- Accepto处理建立连接事件后,MainReactor将连接分配Reactor子线程给SubReactor进行处理
- SubReactor将连接加入连接队列进行监听,并创建一个Handler用于处理各种连接事件
- 当有新的事件发生时,SubReactor会调用连接对应的Handler进行响应
- Handler通过read读取数据后,会分发给后面的Worker线程池进行业务处理
- Worker线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给Handler进行处理
- Handler收到响应结果后通过send将响应结果返回给client
优点
- 父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续的业务处理
- 父线程与子线程的数据交互简单,Reactor主线程只需要把新连接传给子线程,子线程无需返回数据
这种模型在许多项目中广泛使用,包括Nginx主从Reactor多进程模型,
Memcached主从多线程,Netty主从多线程模型的支持
作者:贝聊科技链接:https://juejin.im/post/5b8f23b96fb9a019ec6a133d
来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
多Reactor多线程模型
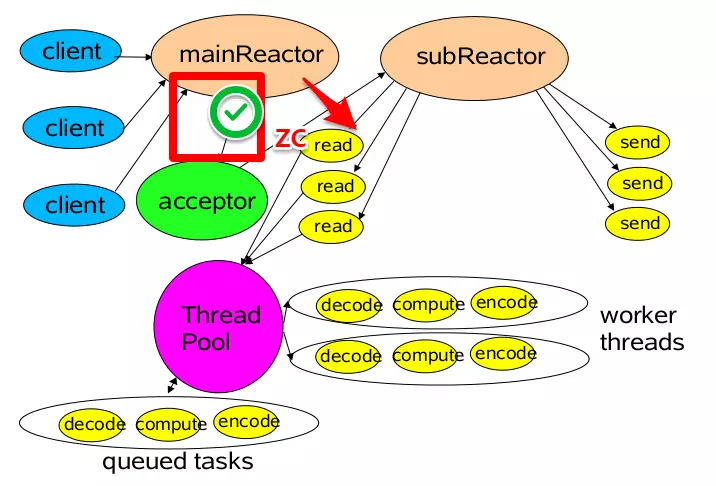
在Reactor中实现读
- 注册读就绪事件和相应的事件处理器。
- 事件分发器等待事件。
- 事件到来,激活分发器,分发器调用事件对应的处理器。
- 事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
操作系统->事件分发器->【处理器】 ->操作系统->事件分发器
在Proactor中实现读:
- 处理器发起异步读操作(注意:操作系统必须支持异步IO)。在这种情况下,处理器无视IO就绪事件,它关注的是完成事件。
- 事件分发器等待操作完成事件。
- 在分发器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分发器读操作完成。
- 事件分发器呼唤处理器。
- 事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分发器。
【处理器】 –>操作系统–>事件分发器–>处理器->事件分发器
当回调handler时,表示I/O操作已经完成 1, 2 ;
同步情况下(Reactor),回调handler时,表示I/O设备可以进行某个操作(can read 或 can write) 1 -> 2 。
标准/典型的Reactor:
- 步骤1:等待事件到来(Reactor负责)。
- 步骤2:将读就绪事件分发给用户定义的处理器(Reactor负责)。
- 步骤3:读数据(用户处理器负责)。
- 步骤4:处理数据(用户处理器负责)。
改进实现的模拟Proactor:
-
步骤1:等待事件到来(Proactor负责)。
-
步骤2:得到读就绪事件,执行读数据(现在由Proactor负责)。
-
步骤3:将读完成事件分发给用户处理器(Proactor负责)。
-
步骤4:处理数据(用户处理器负责)。
框架是什么?
Netty
AE
libevent
Thrift
The Apache Thrift software framework, for scalable cross-language services development, combines a software stack with a code generation engine to build services that work efficiently and seamlessly between C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml and Delphi and other languages.
Google Protocol Buffer
二、线程
问2.1 什么是线程?
线程并发2个方式 消息传递,共享对象
答:
-
锁
互斥锁
条件变量
读写锁(不推荐)
自旋锁
高级组件
线程私有存储(Thread-local storage):
共享内存函数
信号量函数
···················································华丽分隔符 补充基础知识········································


···················································华丽分隔符 补充基础知识········································
问 rwlock和mutex有什么不同和优劣呢
大王: 你平时用c比较多,还是c++比较多?
小王心里:这个还用回答吗?是或者不是,么有任何难度。
这个问题比较坑,如果是回答c++,关于c++的问题 你每次都100%回答不上来。c++对象模型,设计模式
等你回答不上来,如果c这个我没遇到什么情况。
小王: 用c++比较多,但是涉基本组件TCP,线程采用c提供原始接口,没有使用boost lievent这样开源的库。
大王: 你用c++编程,多线程 采用是c++11提供的std::thread吗?
小王:不是,是 Linux操作系统提供的 c语言实现的 pthreads 库
画外音:话题涉及操作系统 和c++ c编程问题
The POSIX thread libraries are a standards based thread API for C/C++
英语:POSIX Threads,常被缩写为Pthreads
Pthreads 是 IEEE(电子和电气工程师协会)委员会开发的一组线程接口,负责指定便携式操作系统接口(POSIX)。Pthreads 中的 P 表示 POSIX
核心资源:
LinuxThreads Frequently Asked Questions
For more information, see the LinuxThreads README and the LinuxThreads Frequently Asked Questions.
问2.2大王:LinuxThreads有什不足?
画外音:
难道这不是完美的吗?还有比它更好的,更方面的,我一直这样用呢?,根本没想过这个问题
字眼缺点 缺点缺点 我不会知道,扩展你擅长核心内容
我第一感觉 java只需要一个类,一个接口好了,超级简单,不需要操作底层api来实现。提供线程池等更加复杂组件
如果不用队列第三方组件,一个线程很难访问另外一个线程栈内 class的对象 ,无法相互串门。只能 通过线程创建时候 参数传入this空间地址,对编程带来不方便,不行不同类直接相互访问呢?
小王:
-
pthread实现基于一对一的线程模型,运行要完全依靠liunx操作内核调度, 无法跨平台
The most common implementation is 1-to-1 mapping where each user-level thread has a corresponding thread that is scheduled by the kernel.
由Xavier Leroy (Xavier.Leroy@inria.fr)负责开发完成,并已绑定在GLIBC中发行。它所实现的就是基于核心轻量级进程的"一对一"线程模型,一个线程实体对应一个核心轻量级进程,而线程之间的管理在核外函数库中实现。
在Linux内核2.6出现之前进程是(最小)可调度的对象,当时的Linux不真正支持线程。但是Linux内核有一个系统调用指令clone(),这个指令产生一个调用调用的进程的复件,而且这个复件与原进程使用同一地址空间。LinuxThreads计划使用这个系统调用来提供一个内核级的线程支持。
但是这个解决方法与真正的POSIX标准有一些不兼容的地方,尤其是在信号处理、进程调度和进程间同步原语方面。
要提高LinuxThreads的效应很明显需要提供内核支持以及必须重写线程函数库
从第3版开始NPTL是Red Hat Enterprise Linux的一部分,从Linux内核2.6开始它被纳入内核。当前它完全被结合入GNU C 库
- LWP就是用户线程
轻量级线程(LWP)是一种由内核支持的用户线程。它是基于内核线程的高级抽象,因此只有先支持内核线程,才能有LWP。每一个进程有一个或多个LWPs,每个LWP由一个内核线程支持。这种模型实际上就是恐龙书上所提到的一对一线程模型。在这种实现的操作系统中,LWP就是用户线程。
轻量级进程具有局限性。首先,大多数LWP的操作,如建立、析构以及同步,都需要进行系统调用。系统调用的代价相对较高:需要在user mode和kernel mode中切换。
其次,每个LWP都需要有一个内核线程支持,因此LWP要消耗内核资源(内核线程的栈空间)。因此一个系统不能支持大量的LWP。
小王:创建一个概念上用户线程,就需要创建一个LWP(chone 共享),就消耗内存栈和id资源,系统资源有限,一个系统不能支持大量的LWP,不会创建线程。
所实现的就是基于核心轻量级进程的"一对一"线程模型,一个线程实体对应一个核心轻量级进程,而线程之间的管理在核外函数库(我们常用的pthread库)中实现。
一直以来, linux内核并没有线程的概念. 每一个执行实体都是一个task_struct结构, 通常称之为进程.
Linux内核并不支持真正意义上的线程,
Linux Threads是用与普通进程具有同样内核调度视图的轻量级进程来实现线程支持的。
每个Linux Threads线程都同时具有线程id和进程id,其中进程id就是内核所维护的进程号,
而线程id则由Linux Threads分配和维护。
用户态线程由pthread库实现,使用pthread以后,
在用户看来, 每一个task_struct就对应一个线程, 而一组线程以及它们所共同引用的一组资源就是一个进程.
但是, 一组线程并不仅仅是引用同一组资源就够了, 它们还必须被视为一个整体.
https://www.cnblogs.com/zhaoyl/p/3620204.html
If threads share the same PID, how can they be identified?
Threads are identified using PIDs and TGID (Thread group id)
Linux 内核进程管理之进程ID
命名空间是为操作系统层面的虚拟化机制提供支撑,目前实现的有六种不同的命名空间,分别为mount命名空间、UTS命名空间、IPC命名空间、用户命名空间、PID命名空间、网络命名空间。命名空间简单来说提供的是对全局资源的一种抽象,将资源放到不同的容器中

- 多对一线程模型
其缺点是一个用户线程如果阻塞在系统调用中,则整个进程都将会阻塞
LWP虽然本质上属于用户线程,但LWP线程库是建立在内核之上的,LWP的许多操作都要进行系统调用,因此效率不高。
而这里的用户线程指的是完全建立在用户空间的线程库,用户线程的建立,同步,销毁,调度完全在用户空间完成,不需要内核的帮助。因此这种线程的操作是极其快速的且低消耗

- 加强版的用户线程——用户线程+LWP
因此进程中某个用户线程的阻塞不会影响整个进程的执行
用户线程库将建立的用户线程关联到 LWP 上
LWP 与用户线程的数量不一定一致。当内核调度到某个 LWP 上时,此时与该 LWP 关联的用户线程就被执行

概念错误纠正:
很多文献中都认为轻量级进程就是线程,实际上这种说法并不完全正确,从前面的分析中可以看到,只有在用户线程完全由轻量级进程构成时,才可以说轻量级进程就是线程。
|
|
-
从用户视角出发,在pid 42中产生的tid 44线程,属于tgid(线程组leader的进程ID) 42。甚至用ps和top的默认参数,你都无法看到tid 44线程。
-
从内核视角出发,tid 42和tid 44是独立的调度单元,可以把他们视为"pid 42"和"pid 44"。
线程共享资源包括:
1.进程代码段
2.进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)
3.进程打开的文件描述符、信号的处理器、进程的当前目录和进程用户ID与进程组ID。
线程独立资源包括:
1.线程ID
每个线程都有自己的线程ID,这个ID在本进程中是唯一的。进程用此来标识线程。
2.寄存器组的值
由于线程间是并发运行的,每个线程有自己不同的运行线索,当从一个线程切换到另一个线程上 时,必须将原有的线程的寄存器集合的状态保存,以便将来该线程在被重新切换到时能得以恢复。
3.线程的堆栈
堆栈是保证线程独立运行所必须的。线程函数可以调用函数,而被调用函数中又是可以层层嵌套的,所以线程必须拥有自己的函数堆栈, 使得函数调用可以正常执行,不受其他线程的影响。
4.错误返回码
由于同一个进程中有很多个线程在同时运行,可能某个线程进行系统调用后设置了errno值,而在该 线程还没有处理这个错误,另外一个线程就在此时被调度器投入运行,这样错误值就有可能被修改。所以,不同的线程应该拥有自己的错误返回码变量。
5.线程的信号屏蔽码
由于每个线程所感兴趣的信号不同,所以线程的信号屏蔽码应该由线程自己管理。但所有的线程都 共享同样的信号处理器。
6.线程的优先级
由于线程需要像进程那样能够被调度,那么就必须要有可供调度使用的参数,这个参数就是线程的优先级。
大王:c++的成员函数可以是多线程的函数吗?
我根本不理解这个题目什么意思
|
|
小王:不能
|
|
大王:那还有其他方式吗?
小王:携程:
大王:实现原理是什么?
小王:想了想太难了,我不清楚。
| 协程库 | 语言 | 开发者 |
|---|---|---|
| state threads library | 3000行C代码 | 历史渊源 |
ST本质上仍然是基于EDSM模型,但旨在取代传统的异步回调方式 ,为互联网应用程序而生的State Threads
用setcontext()和getcontext()来实现单个进程内的用户空间线程.
https://linux.die.net/man/3/getcontext
st_thread_create
三、文件系统
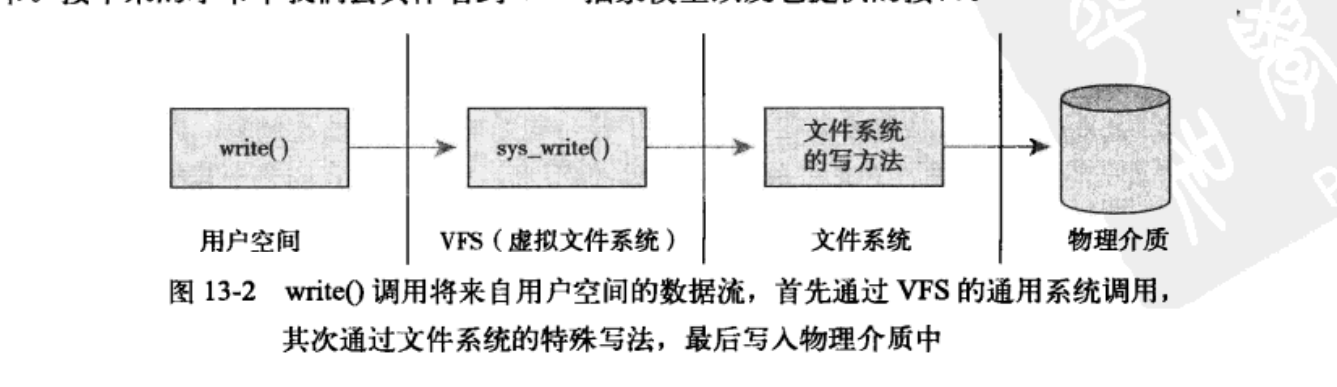
问3.1 一次write操作,数据写入内存那个部分?
一. write文件有那2个方式呀?
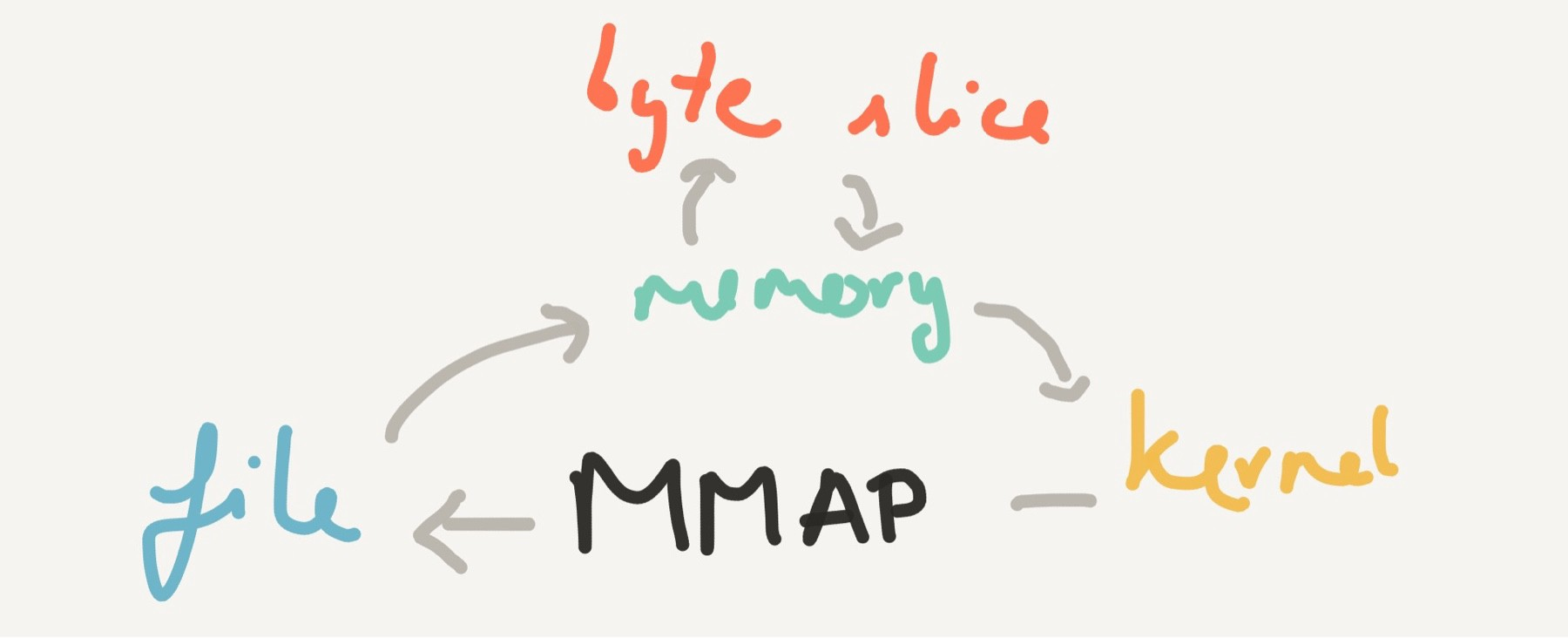
我的理解:还用问吗?直接wirte,还有什么方式
mmap也被称为zero-copy技术
Memory-mapped I/O uses the same address space to address both memory and I/O devices. The memory and registers of the I/O devices are mapped to (associated with) address values. So when an address is accessed by the CPU, it may refer to a portion of physical RAM, or it can instead refer to memory of the I/O device.
SQLite:
Beginning with version 3.7.17 (2013-05-20), SQLite has the option of accessing disk content directly using memory-mapped I/O and the new xFetch() and xUnfetch() methods on sqlite3_io_methods.
MongoDB
The main storage engine in MongoDB is the Memory Mapped Storage Engine or MMAP for short.
The MMAP storage engine uses memory mapped files as its storage engine.
http://learnmongodbthehardway.com/schema/mmap/
Memory mapped files allow MongoDB to delegate the handling of Virtual Memory to the operating system instead of explicitly managing memory itself.
mmap系统调用并不是完全为了用于共享内存而设计的。
它本身提供了不同于一般对普通文件的访问方式,进程可以像读写内存一样对普通文件的操作
常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。
而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程。
|
|
文件读写基本流程



|
|
3 、 网络模块
问题3 为什么采用epoll?
- 第一步: 同步与阻塞,异步和非阻塞的区别?
- 第二步:了解网络模型
- 检查:select/epoll 是阻塞( Block )还是非阻塞( Unblock ),同步( (Sync) )还是异步 (Async) ?
- 第三步:epoll特点
- 第四步:为什么不用现有框架呢 ,自己写干什么
第一步: 同步与阻塞,异步和非阻塞的区别?
阻塞和非阻塞区别是什么?
第一感觉:
-
阻塞和非阻塞本身没有区别,只是调用资源属性是阻塞的还是非阻塞的?
-
阻塞和非阻塞区是否立即返回?
-
阻塞和非阻塞在进程有没有放入调度阻塞队列
-
都不同意
小王 第三次回答
同步和异步区别是调用进程是否阻塞, 什么阻塞 就是不占用cpu
非阻塞和异步区别 返回时候数据在用户缓冲还是内核缓冲区。
同步与阻塞区别:同步可以不阻塞进程。后者一定是。
小王 第二次回答
阻塞和非阻塞在用法区别,
阻塞和非阻塞区别是:继续等待还是离开返回。
在io读写操作中,是当内核缓冲区数据null或者满时候,是否继续等待 阻塞进程,还是离开返回。
其他都一样。
概念区别我不知道
非阻塞 和异步区别
- 当获取事件通知时候,非阻塞数据依然在内核缓冲区,异步数据在用户缓冲区。
小王 第一次回答 感觉不好自己都写不下去来哦
阻塞和非阻塞只是系统调用(铺垫,具体来说同步)
如果访问的资源是阻塞,(意识说跟调用接口没关系,内核处理方式有关系),进程加入等待队列。
等到内核处理程序, i0操作满足完成指定条件 然后 copy用户缓冲区 ,返回结果,唤醒进程读取数据,—什么是阻塞
如果访问的资源是非阻塞,(意识说跟调用接口没关系,内核处理方式有关系),
不加入等待队列,直接返回当前io处理结果。 如果大于0 代表读取到数据,如果小于零 error是EAGAIN
阻塞和非阻塞用法上区别应该是资源的属性,如果非最赛,遇到错误时候,返回EAGAIN。 这个是最大区别吗
–应该不是
阻塞非阻塞的意思很明显,就是用户程序调用系统调用后,操作系统会不会把该用户进程放入等待队列,如果放入等待队列则为阻塞,否则为非阻塞
i0操作 read wite
an input operation:
-
Waiting for the data to be ready
-
Copying the data from the kernel to the process
遗漏任务:一次read/write 内核处理过程是什么,如果不清楚很难回答上面问题?
~~~~~~~~~~~~~~~~~~~~华丽分隔符~~~~~~~~~~~~~~
-
https://www.cnblogs.com/xiehongfeng100/p/4619451.html
Chapter 3. Sockets Introduction
-
阻塞IO比非阻塞IO慢的主要原因是线程切换的开销,尤其是请求数过大时,线程切换开销是没法忽略的。

- 阻塞(Block)这个概念
现在明确一下阻塞(Block)这个概念。当进程调用一个阻塞的系统函数时,该进程被置于睡眠(Sleep)状态,这时内核调度其它进程运行,直到该进程等待的事件发生了(比如网络上接收到数据包,或者调用sleep指定的睡眠时间到了)它才有可能继续运行。与睡眠状态相对的是运行(Running)状态,在Linux内核中,处于运行状态的进程分为两种情况:
https://cloud.tencent.com/developer/article/1008816
-
fcntl 函数 http://man7.org/linux/man-pages/man2/fcntl.2.html
1 2 3 4 5 6 7If the O_NONBLOCK flag is not enabled, then the system call is blocked until the lock is removed or converted to a mode that is compatible with the access. If the O_NONBLOCK flag is enabled, then the system call fails with the error EAGAIN. -
read返回值是什么?
解阻塞与非阻塞recv返回值没有区分,都是
<0 出错
=0 连接关闭 errno
>0 接收到数据大小,
特别:返回值<0时并且(errno == EINTR || errno == EWOULDBLOCK || errno == EAGAIN)的情况下认为连接是正常的,继续接收。
只是阻塞模式下recv会阻塞着接收数据,非阻塞模式下如果没有数据会返回,不会阻塞着读,因此需要循环读取)。
返回说明:
成功执行时,返回接收到的字节数。另一端已关闭则返回0。失败返回-1,errno被设为以下的某个值
几个重要的结论:
1. read总是在接收缓冲区有数据时立即返回,而不是等到给定的read buffer填满时返回
只有当receive buffer为空时,blocking模式才会等待,
而nonblock模式下会立即返回-1(errno = EAGAIN或EWOULDBLOCK)
**注:**阻塞模式下,当对方socket关闭时,read会返回0。
2. blocking的write只有在缓冲区足以放下整个buffer时才返回(与blocking read并不相同)
nonblock write则是返回能够放下的字节数,之后调用则返回-1(errno = EAGAIN或EWOULDBLOCK)
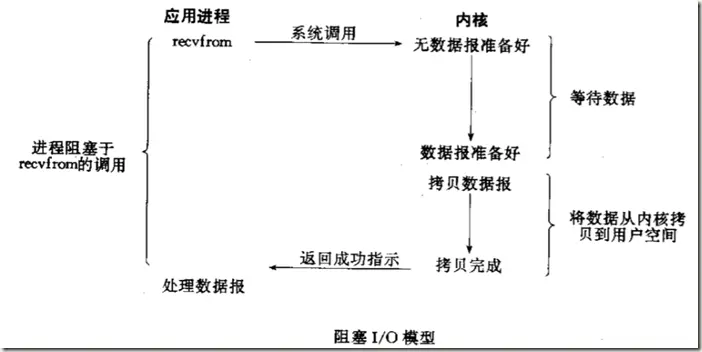
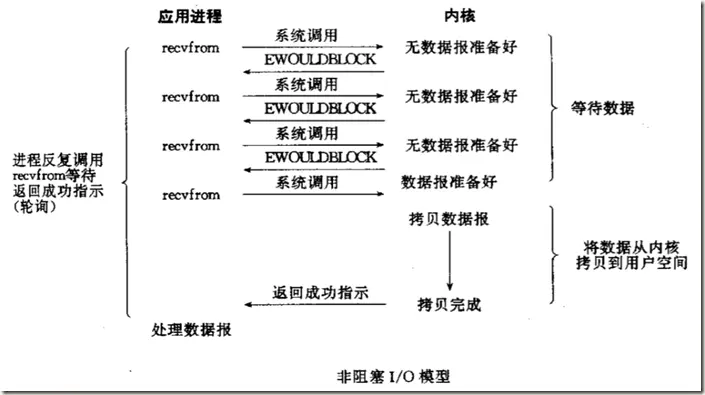
http://www.pulpcode.cn/2017/02/01/user-buffer-and-kernel-buffer/
对比阻塞和非阻塞,在阻塞io中,直到数据从内核缓冲区拷贝到用户缓冲区才通知用户进程调用完成并唤醒,而非阻塞,在轮训得知数据准备好后,数据还是在内核缓冲区中,等你去读取,这也就是说数据准备好,并不代表已经读好可以使用。当然也不代表一定能读。
POSIX defines these two terms as follows: A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
An asynchronous I/O operation does not cause the requesting process to be blocked
-
别人的答案
https://blog.csdn.net/wingter92/article/details/80080737
对于设备文件,我们可以用阻塞和非阻塞的方式读写。
在阻塞方式下,若设备不可读写,则该进程休眠,释放CPU资源;若设备文件可读写,则对设备文件进行读写。
在非阻塞方式下,若设备不可读写,进程放弃读写,继续向下执行;若设备文件可读写,则对设备文件进行读写。
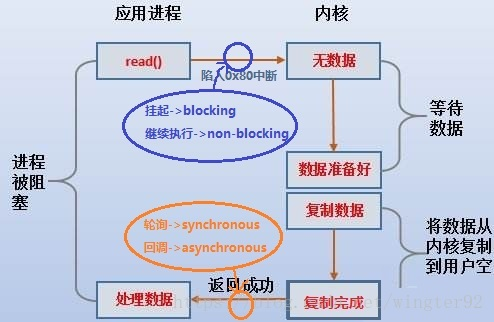
协程切换和内核线程的上下文切换相同,也需要有机制来保存当前上下文,恢复目标上下文。在POSIX系统上,getcontext/makecontext/swapcontext等可以用来做这件事。
协程带来的最大的好处就是可以用同步的方式来写异步的程序。比如协程A,B:A是工作协程,B是网络IO协程(这种模型下,实际工作协程会比网络IO协程多),A发送一个包时只需要将包push到A和B之间的一个channel,然后就可以主动放弃CPU,让出CPU给其它协程运行,B从channel中pop出将要发送的包,接收到包响应后,将结果放到A能拿到的地方,然后将A标识为ready状态,放入可运行队列等待调度,A下次被调度器调度就可以拿到结果继续做后面的事情。如果是基于线程的模型,A和B都是线程,通常基于回调的方式,1. A阻塞在某个队列Q上,B接受到响应包回调A传给B的回调函数f,回调函数f将响应包push到Q中,A可以取到响应包继续干活,如果阻塞基于cond等机制,则会被OS调度出去,如果忙等,则耗费CPU。2. A可以不阻塞在Q上,而是继续做别的事情,可以定期过来取结果。 这种情况下,线程模型业务逻辑其实被打乱了,发包和取包响应的过程被隔离开了。
实现协程库的基本思路很简单,每个线程一个调度器,就是一个循环,不断的从可运行队列中取出协程,并且利用swapcontext恢复协程的上下文从而继续执行协程。当一个协程放弃CPU时,通过swapcontext恢复调度器上下文从而将控制权归还给调度器,调度器从可运行队列选择下一个协程。每个协程初始化通过getcontext和makecontext,需要的栈空间从堆上分配即可
怎样理解阻塞非阻塞与同步异步的区别?
为什么不要阻塞你的事件轮询(或是工作线程池)?
Node 有两种类型的线程:一个事件循环线程和 k 个工作线程。
事件循环负责 JavaScript 回调和非阻塞 I/O,工作线程执行与 C++ 代码对应的、完成异步请求的任务,包括阻塞 I/O 和 CPU 密集型工作。
这两种类型的线程一次都只能处理一个活动。 如果任意一个回调或任务需要很长时间,则运行它的线程将被 阻塞。 如果你的应用程序发起阻塞的回调或任务,在好的情况下这可能只会导致吞吐量下降(客户端/秒),而在最坏情况下可能会导致完全拒绝服务。
|
|
从操作系统角度考虑 只有AIO,操作才是真正异步
从用户角度 Libevent ,Netty ,确实IO多路复用也是异步的 如何理解?
libevent is a software library that provides asynchronous event notification.
The libevent API provides a mechanism to execute a callback function when a specific event occurs on a file descriptor or after a timeout has been reached. libevent also supports callbacks triggered by signals and regular timeouts.
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
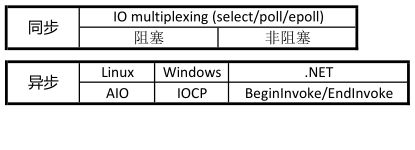
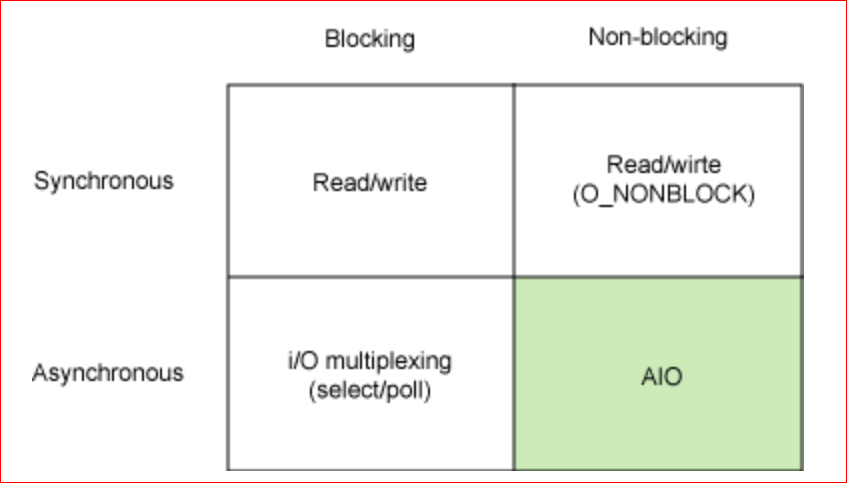
第二步:了解网络模型
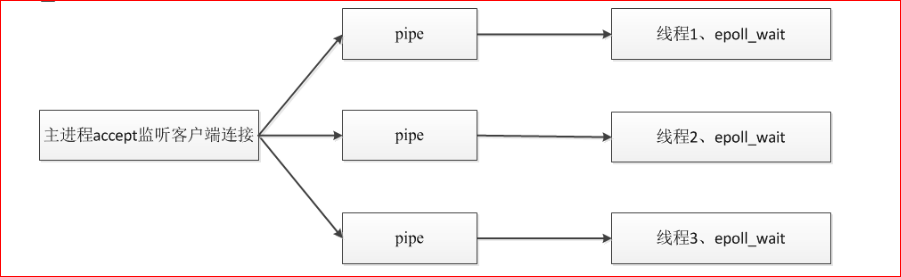
假设你即将要为一个重要的大公司开发一个新的关键任务的应用程序。
在第一次会议上,你了解到这个系统必须能无性能损耗地扩展到支持15万个并发用户。这时所有的人都看着你,你会说什么?
NIO(Non-blocking I/O,在Java领域,也称为New I/O),是一种同步非阻塞的I/O模型,也是I/O多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有效方式
检查:select/epoll 是阻塞( Block )还是非阻塞( Unblock ),同步( (Sync) )还是异步 (Async) ?
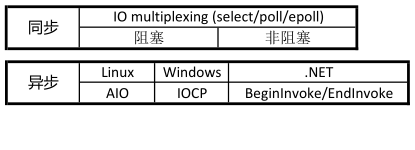
~~~~~~~~~~~~~~~~~~~~华丽分隔符~~~~~~~~~~~~~~
第三步:epoll特点
小王:我从使用角度考虑
-
epoll 单节点很容易扩展到大量TCP连接( concurrency )并发的情况,摆脱最原始的一个连接一个线程处理,系统打开最大线程数量的限制。
-
epoll虽然是基于事件触发来轮询处理的(同步处理),但是与全局变量(redis),消息队列,多进程(Nginx )/多线程(Memcached)达到异步非阻塞效果(信号是进程间通信机制中唯一的异步通信机制)。
select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
-
大量连接部分活跃情况有优势,比select多了一层异步回调。
几个线程处理上万连接,主要是指有很多不忙的连接的场景,如聊天室服务器
分析过程:
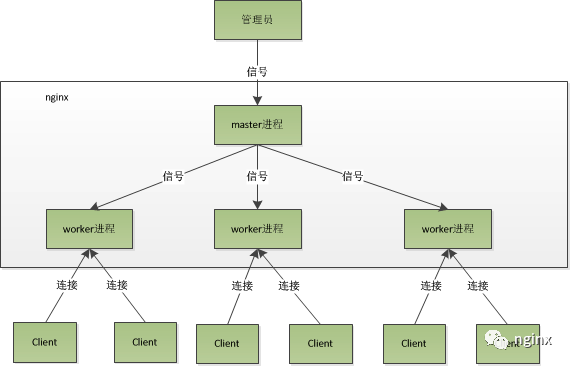
这种进程模型的好处:
- 每个worker进程相互独立,无需加锁,省掉锁的开销
- 多个worker进程互相不影响,提高稳定性
- 多进程提供性能
nginx利用多进程+非阻塞的模型,能轻松处理上万连接。其处理请求的大致过程为:
- 一个连接请求过来,worker进程的监听套接字可读(这里涉及到
惊群现象) - 处理监听套接字可读事件,accept该连接
- worker进程开始读取请求,解析请求,处理请求,回复数据,断开连接的流程
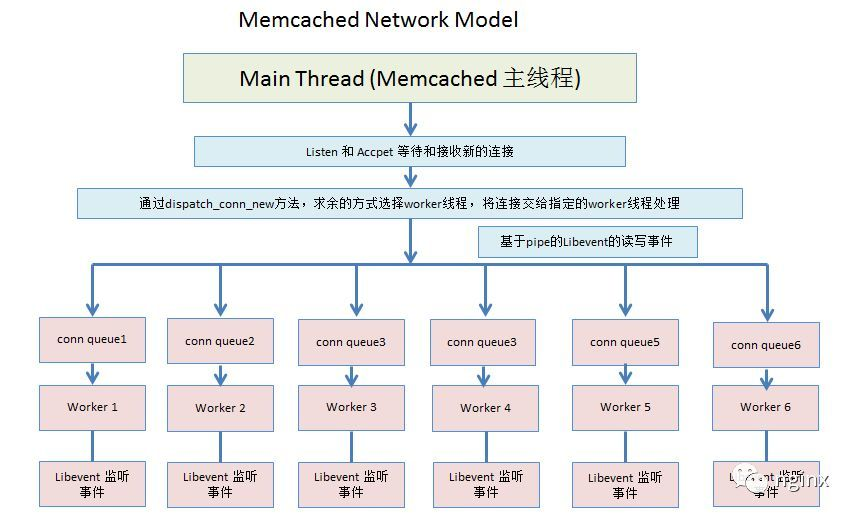
Memcached总结
网络模型
memcached是一款服务器缓存软件,基于libvent开发,使用的多线程模型,主线程listen\accept,工作线程处理消息。
主要流程是:
- 创建主线程和若干个工作线程;
- 主线程监听、接受连接;
- 然后将连接信息分发(求余)到工作线程,每个工作线程有一个conn_queue处理队列;
- 工作线程从conn_queue中取连接,处理用户的命令请求并返回数据;
Redis事件模型
Redis采用单线程模型,通过IO多路复用来监听多个连接,非阻塞IO,同时单线程避免了不必要的锁的开销。
Redis同时处理文件事件和时间事件
epoll非阻塞服务器,在20k并发测试结束产生大量establish状态假连接,可能原因
|
|
第四步:为什么不用现有框架呢 ,自己写干什么
问题4 tcp
问:如何消除大量time_wait 状态?
回答:
对于服务器来说 一般属于被动关闭一方,一般不会出现多time_wait 状态,并且TCP建立连接,只会消耗更多文件,内存等资源 并不过占用过多的port端口?
画外音:
作为客户端,最多可以 使用64512个端口,也就是同一时刻对同一个服务器同一个端口可以创建64512个TCP连接
而对于服务器来说,它没有所谓的“65536”端口数量的限制。可以有多少客户端连接服务器,取决于CPU、内存等资源的大小
一个TCP连接唯一性确定:
ServerIP => ServerPort <= TCP => ClientIP => ClientPort
分析一下是什么原因造成的呢?
- 客户端大量的压测 每秒就会创建400+的连接,1分钟就是2.4万的连接,系统无法及时回收
默认ip_local_port_range是2.8w个
解决方式是:
- 当出现大量的time_wait状态时候,首先检查一下当前系统配置参数情况,如果在合理访问内
具体参数是:
1.随机端口范围 ip_local_port_range 默认2.8w
sysctl -a | grep ip_local_port_range
net.ipv4.ip_local_port_range = 32768 61000
系统允许的文件描述符数量 默认6.5w可以调整10w
cat /proc/sys/fs/file-max
655360
心跳检查参数
sysctl -a | grep tcp_keepalive_time
net.ipv4.tcp_keepalive_time = 7200
tcp_tw_reuse等快速回收 参数 是有风险的不建议启用。
TIME_WAIT关闭的危害:
1、 网络情况不好时,如果主动方无TIME_WAIT等待,关闭前个连接后,主动方与被动方又建立起新的TCP连接,这时被动方重传或延时过来的FIN包过来后会直接影响新的TCP连接;
2、 同样网络情况不好并且无TIME_WAIT等待,关闭连接后无新连接,当接收到被动方重传或延迟的FIN包后,会给被动方回一个RST包,可能会影响被动方其它的服务连接。
|
|
参考:百万并发连接、65536和Linux TCP/IP 性能优化
二、提升
性能优化
问题4 如果一个c++开发的系统,在生产运行3年后,最后查询越来越慢 如何解决?
c++ 语言本身 ;和操作系统方面
参考书
性能之巅 洞悉系统、企业与云计算
提高C++性能的编程技术
C++性能优化指南
参考项目:
虽然很重要但是不考虑问题
优化数据库,这个和程序有啥关系
回答1 热点函数优化 20%原则
-
能不能内敛
-
函数 时间复杂度 减少循环的层次,次数和 循环体非必要函数调用出现的开销(引用避免拷贝)
-
函数调用开销
虚函数的另一个问题是编译器难以内联它们
用模板在编译时选择实现
std:bind+std:function取代虚函
编译选项 o2
提高编译速度
回答2 优化数据结构,更好的库
参考资料
[1] http://kernel.pursuitofcloud.org/531016
[2] https://www.kancloud.cn/kancloud/understanding-linux-processes/52197
[3] 从内核文件系统看文件读写过程 [ok]
[5] Linux 中 mmap() 函数的内存映射问题理解? [这个很重要,必看]
[7] MMAP storage Engine in Mongodb
[8] https://juejin.im/post/5aeb0e016fb9a07ab7740d90 深入理解读写锁ReentrantReadWriteLock
http://blog.guoyb.com/2018/02/11/rwlock/
https://tech.meituan.com/2018/11/15/java-lock.html
【9】 获取自旋锁和禁止中断的时候为什么不能睡眠?
https://www.zhihu.com/question/28821201
https://www.zhihu.com/question/23995948
https://segmentfault.com/a/1190000019506505
[10] 网络编程:进程间通信性能比较 https://zhuanlan.zhihu.com/p/80368714
[11] https://people.cs.clemson.edu/~dhouse/courses/405/papers/optimize.pdf
[12] http://oldblog.antirez.com/post/redis-virtual-memory-story.html
[13] https://www.sqlite.org/mmap.html
[14] What are the advantages and disadvantages of memory-mapped I/O and direct (or port) I/O?
【15】 Java NIO浅析
[16] socket阻塞与非阻塞,同步与异步、I/O模型,select与poll、epoll比较
[17] Blocking I/O, Nonblocking I/O, And Epoll 【redis作者]
【18】浅谈IO的多路复用技术之一(select和epoll实质)
https://medium.com/@copyconstruct/the-method-to-epolls-madness-d9d2d6378642
[19] 进程线程常见基础问题